万丈高楼平地起——大数据配置管理之HDFS(上)
Posted 大数据可视化周刊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万丈高楼平地起——大数据配置管理之HDFS(上)相关的知识,希望对你有一定的参考价值。
众所周知,Hadoop是目前最流行的大数据计算平台,它由众多的框架(或者称为模块,组件)组成,共同完成大数据的计算任务。实际上,大数据需要解决的两大核心问题是数据的存储和数据的计算。Hadoop对数据的存储采用的是分布式方式,对数据的计算也采用分布式方式。具体来说,Hadoop包含以下核心框架:
HDFS:实现数据的分布式存储
MapReduce:实现数据的分布式计算
Yarn:对计算任务进行资源分配和任务调度
这就说明,只要安装和配置了Hadoop,以上三个框架就能使用了。MapReduce只实现了最基本的对数据的离线计算,而Hadoop这个开放式计算平台是不断发展的,更多的更先进的计算框架不断加入,如Spark能够对数据进行实时计算,而Storm能够对数据进行实时的流式计算。
一、HDFS的设计思想
HDFS即Hadoop Distributed File System,Hadoop分布式文件系统,它来源于谷歌公司的一篇学术论文“The Google File System”,这篇论文中介绍的思想被引入Hadoop,就是现在的HDFS,它是Hadoop的基础架构。Hadoop的配置管理就是从HDFS开始的。
HDFS作为一种文件系统,用于存储数据,它与传统文件系统既有相同的特点,也有巨大的差别。由于HDFS对于硬件没有特别的要求,普通的PC机和普通硬盘即可,所以带来一个不可避免的问题:如果硬件出现故障,数据就会丢失。HDFS的设计基于以下思想:
硬件故障的发生是常态,而不是偶然事件。HDFS采用高冗余的方式保证数据的安全,任何数据在HDFS中都有多个拷贝,它们分布在不同的计算机系统中
移动计算的成本低于移动数据。数据存储在什么地方,对数据的计算就在什么地方进行,应用程序在本地就能找到数据,而不需要通过网络获取数据
支持大文件,文件大小可达到TB、PB级,这样的文件在任何单个硬盘中都无法存储。HDFS将文件分割为数据块,写入不同的DataNode中
数据的存储空间是可以扩展的。虽然单个硬盘的空间是有限的,但HDFS把多个计算机系统中的硬盘设备整合在一起,从而产生一个非常大的、可以不断扩展的存储空间
数据的访问方式是:一次写入,多次读取
应用程序对数据的访问应该是批量的流式读访问,而不是随机的读写访问
由此可见,HDFS的功能是为Hadoop中的分布式应用程序提供分布式数据存储。一方面,HDFS存储原始数据,即需要被处理的数据;一方面,存储计算的中间结果;另一方面,存储最终的计算结果。分布式应用程序在多个计算机系统中同时运行,读取HDFS中位于本地硬盘上的数据,对它们进行处理,然后把处理结果写入HDFS,从而实现数据的并行计算。
通过上面的描述可以知道,大数据是数据的集合,而数据库也是数据的集合,那么它们之间有什么区别呢?二者的区别与联系有以下几点:
传统数据库的数据量一般为GB、TB级,而大数据的数据量为TB、PB甚至更多
传统数据库的访问侧重于OLTP(联机事务处理),而大数据的访问侧重于批量处理
传统数据库的数据频繁变化,而大数据则是一次写入、多次读取
传统数据库中存储联机数据,而大数据则是历史数据。实际上,大数据的来源一般都是关系型数据库,如mysql数据库或者Oracle数据库
传统数据库对数据采用集中存储、集中处理的方式,而大数据则采用分布式存储、分布式计算的方式
传统数据库对数据的处理是实时的,而大数据的处理有相当的延迟
传统数据库支持事务,而大数据不支持事务
二、HDFS的体系结构
HDFS的体系结构如图1所示。HDFS包含一个NameNode,一个或多个DataNode。这里所说的node,一方面指的是操作系统中的进程,另一方面指的是运行这些进程的计算机系统。这些进程可以运行在相同或不同的操作系统中,如果是生产环境,它们应该运行在独立的PC机上的操作系统中。
DataNode的功能是为HDFS提供数据的存储空间,如果一个操作系统中运行DataNode进程,那么这个计算机系统就把本地硬盘作为HDFS的存储空间。NameNode的功能是维护HDFS的配置信息,如HDFS中的NameNode和DataNode,以及HDFS的元数据,即数据在DataNode中的分布情况。如果要修改HDFS的配置,那么需要修改NameNode上的配置文件,如果文件系统的结构有变化,比如用户写入文件、删除文件,那么NameNode上的元数据就会发生相应的变化。
HDFS中的数据是以文件形式存在的,这种文件可以达到PB、TB甚至更大。数据在被写入HDFS之前,首先被分割为块(block),块大小是可以指定的,如64MB、128MB、256MB等,对同一个文件来说,块大小都是相同的,当然,最后一个块可能不足一个块大小。为了防止硬件故障,每个块会有多个拷贝,默认为3,分布在不同的DataNode上。同一个文件的各个块具有相同的拷贝数。对于HDFS来说,块大小和块的拷贝数是可以修改的,这样的修改将对以后的文件产生影响。
图1 HDFS体系结构
对于HDFS来说,客户端(即图1中的Client)就是访问HDFS中的数据的应用程序,比如hdfs shell命令,也可能是其它框架,如MapReduce,Hbase等,也可能是用户自己编写的分布式应用程序。客户端需要把数据写入HDFS。按照HDFS的块大小和块的拷贝数,数据被写入各个DataNode,而这些块的分布情况则被写入NameNode,这就是元数据。以后客户端如果希望访问数据,首先从NameNode获得元数据,然后从DataNode获取数据。数据的分布情况与元数据的关系如图2所示。
NameNode和DataNode协同工作,共同实现HDFS的功能,它们之间通过TCP/IP协议进行通信。DataNode通过高层的RPC协议,定期向NameNode报告自己的状态,同时报告数据块在自己的硬盘上的分布情况。如果DataNode停止发送心跳信号,那么NameNode将认为DataNode停止运行,以后的数据将不会被写入这个DataNode,而客户端对数据的访问请求也不会被发送到这个DataNode。
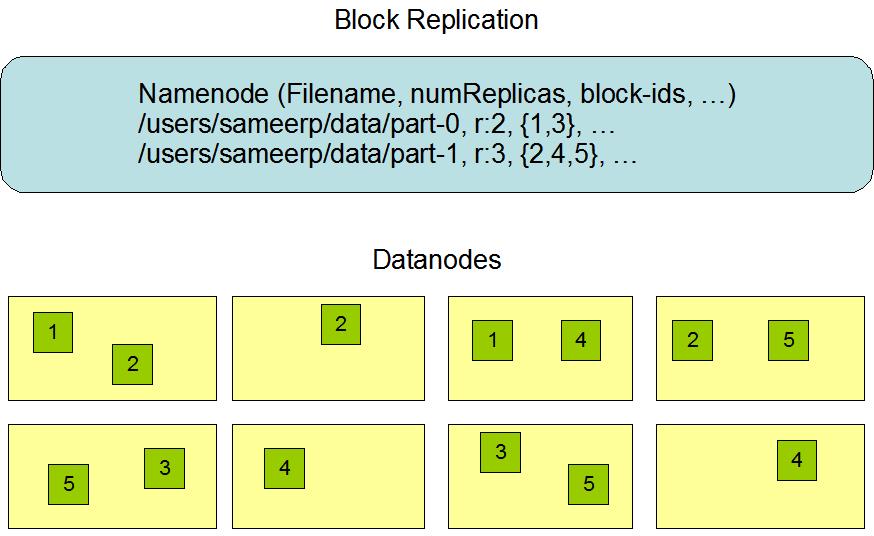
图2 HDFS中数据的分布情况
HDFS的元数据表现为操作系统中的文件,在NameNode的本地文件系统中,有一个文件叫做Fsimage,这就是元数据文件。每次NameNode启动时,把这个文件加载到内存中,这样它就获得了数据在DataNode上的分布情况。随着客户端对HDFS不断地进行访问,如写入新数据、删除文件等,元数据将不断变化。然而这样的变化并不是立刻体现到Fsimage文件中的,NameNode将文件系统的变化写入另外一个文件,即Editlog。NameNode定期将Editlog文件的内容应用到Fsimage中,使其成为最新的元数据文件,然后将这个文件写入本地文件系统,这个过程叫做checkpoint。当管理员正常关闭NameNode时,checkpoint也会发生一次。
三、HDFS的高可用性
HDFS的高可用性包括两个方面,其一是数据的高可用性,这是通过数据的高冗余来保证的;其二是NameNode的高可用性,这是通过集群来保证的。通过前面的内容介绍可以知道,NameNode在HDFS中处于核心地位,如果它停止运行,那么整个HDFS将不可用。为了防止NameNode出现故障,可以配置HDFS集群。在集群中,有多个NameNode在运行,其中一个处于Active状态,其余处于Standby状态。客户端对HDFS的访问请求都发送到Active状态的NameNode,如果这个NameNode由于故障原因而不可用,这时其中一个Standby状态的NameNode将升级为Active状态。这些NameNode必须解决一个重要的问题,那就是Fsimage和Editlog文件的一致性。当HDFS的元数据有变化时,处于Active状态的NameNode将更新本地文件系统中的Fsimage和Editlog文件,然而这样的变化并没有体现在其它的NameNode中。处于Standby状态的NameNode必须获得最新的元数据,才可能升级到Active状态。
如果希望配置HDFS集群,需要选择以下两种方法之一,来保证元数据的一致性:
NFS服务
QJM
第一种方法的实现原理是,多个NameNode通过NFS服务的共享目录来保证元数据的一致性。当HDFS的元数据有变化时,处于Active状态的NameNode将更新本地的Fsimage和Editlog文件,同时将这两个文件写入NFS共享目录。而那些处于Standby状态的NameNode则从NFS共享目录读取这两个文件,更新自己本地的这两个文件,从而获得最新的元数据。
第二种方法QJM(即Quorum Journal Manager)的实现原理是,多个NameNode通过一组JournalNode来保证元数据的一致性。JournalNode是指操作系统中的进程,同时指的是运行这种进程的计算机系统。当HDFS的元数据有变化时,处于Active状态的NameNode将更新本地的Fsimage和Editlog文件,同时将这两个文件写入JournalNode的本地目录。而那些处于Standby状态的NameNode则从JournalNode读取这两个文件,更新自己本地的这两个文件,从而获得最新的元数据。JournalNode的数量至少要求三个,只要处于Active状态的NameNode将Fsimage和Editlog文件写入大多数JournalNode,元数据的一致性就能够得到保证。为了保证“大多数写入”,JournalNode的数量最好配置为奇数。
然而,当你配置并启动了HDFS集群,并且通过上述两种方法之一实现元数据的同步之后,你会发现,所有的NameNode都处于Standby状态,也就是说,它们的状态转换需要通过执行命令来手工进行。为了使NameNode的状态能够自动地在Active和Standby之间进行转换,还需要配置另外一个框架,那就是ZooKeeper。
四、数据的水平复制
假设一个文件的大小为1GB,客户端需要把文件上传到HDFS中。如果HDFS指定的块大小为256MB,数据的拷贝数为3,那么这个文件将被分割成4个块,每个块有三个拷贝,分布在三个不同的DataNode中。这是不是意味着客户端需要把这个文件上传三次呢?当然不是,客户端只需要把文件上传到其中一个DataNode,这个DataNode将这个块水平复制到第二个DataNode,第二个DataNode再将此块水平复制到第三个DataNode,以此类推。这种方式叫做pipeline。图3表示其中一个块的水平复制情况。
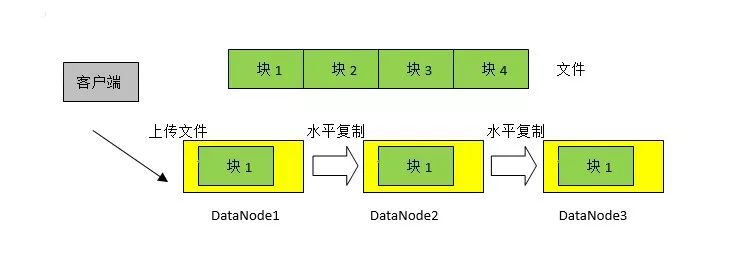
图3 数据的水平复制
HDFS能够自动感知多个DataNode所在的计算机是不是位于同一个机架(Rack)上。一般来说,同一个机架上的计算机通过同一个交换机相连,相互之间的数据传输速度较快,但如果机架整体遇到灾难性的故障,如火灾,那么所有计算机都会受到牵连。不同机架上的计算机一般通过不同的交换机甚至路由器相连,相互之间的数据传输速度较慢,然而多个机架同时发生故障的可能性比较小。HDFS在对数据进行水平复制时,一方面考虑到数据的传输速度,另一方面考虑到数据的高可用性。水平复制的顺序一般是:客户端把数据写入其中一个DataNode,这个DataNode把数据水平复制到另一个机架上的一个DataNode,然后把数据水平复制到同一机架的一个DataNode。
五、实验环境的搭建
实验环境一般以练习、测试或者开发为目的,硬件资源有限,所以希望计算机的处理能力能够得到充分利用。一般在个人PC或者笔记本中运行Vmware虚拟机,至少三个;在虚拟机中安装Linux操作系统,作为Hadoop的运行环境。在这样的实验环境中运行一个MapReduce任务时,硬件资源立刻显得捉襟见肘。
在开始配置Hadoop之前,首先需要对Linux操作系统进行以下配置和规划:
1、创建必要的操作系统用户
虽然root用户是Linux操作系统中的管理员,但Hadoop的运行不能使用这个用户,而需要一个普通用户,如hadoop。以root用户登录每个Linux操作系统,创建hadoop用户,并且为其指定口令。以后对Hadoop的配置管理任务,基本上是以这个用户身份进行的。
2、安装JDK软件
Hadoop的各个框架基本是用Java语言编写的,所以Hadoop的运行需要JDK。虽然Linux操作系统自带JDK,但在运行Hadoop时会出现各种莫名其妙的问题。因此,需要在Oracle官网下载较新的JDK,然后以root用户身份,在每个Linux操作系统中进行安装。
接下来,需要以hadoop用户身份,在HOME目录下的.bash_profile文件中定义环境变量,如:
export JAVA_HOME=/usr/java/jdk1.8.0_152
export PATH=$JAVA_HOME/bin:$PATH
上述第一个变量用于指定JDK的安装目录,具体的变量值取决于JDK的实际安装路径。第二个变量用于指定操作系统中可执行文件所在的路径,在这里需要把JDK安装目录下的bin子目录置于前面,这样可以保证以后执行的Java相关命令都来自我们自己安装的JDK,而不是操作系统自带的JDK。
3、SSH对等关系的配置
由于Hadoop运行环境包含众多的node,它们分布在不同的操作系统中,所以集中式的配置和管理是非常必要的。一般情况下,在一个node上修改配置文件,然后把修改结果拷贝到其它node,在一个node上执行命令,控制其它所有node。
为了实现Hadoop的集中配置和管理,需要在操作系统中配置SSH对等关系,这种配置在有些文档中叫做无密/免密登录。SSH对等关系的原理是,在两个操作系统中选择对等用户,一般是同名用户,在第一个操作系统中执行SSH中的ssh-keygen命令,产生一对密钥,一个公钥一个私钥;然后把公钥拷贝到第二个操作系统,这样就可以在第一个操作系统中通过ssh命令执行第二个操作系统中的命令,或者通过scp命令在两个操作系统中拷贝文件,不需要输入对方用户的口令。如果仅仅把一个操作系统中的公钥拷贝到另一个操作系统,这样的对等关系是单向的。利用SSH还可以配置用户之间的双向对等关系,具体做法是,首先在每个操作系统中分别产生密钥,再把每个操作系统中的公钥集中到一个文件中,然后把这个文件分发到所有操作系统中,以后用户就可以登录任何一个操作系统,控制整个Hadoop,或者在任意两个操作系统中拷贝文件。以下是双向对等关系的配置过程。
首先,以hadoop用户身份分别登录每个操作系统,执行命令ssh-keygen,一路回车,产生两个密钥文件,位于HOME目录的.ssh子目录下,其中id_rsa是私钥文件,id_rsa.pub是公钥文件。
然后选择其中一个操作系统,把自己的公钥拷贝到.ssh目录下的authorized_keys文件中,例如:
cat id_rsa.pub > authorized_keys
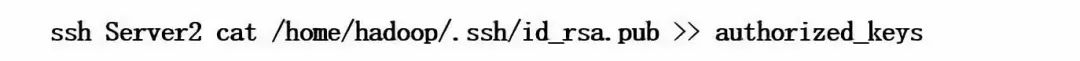
此时由于用户的对等关系尚未配置完成,所以在执行上述命令时,需要输入对等用户的口令。这条命令的意思是:通过ssh调用Server2上的cat命令,打开id_rsa.pub文件,把文件内容追加到当前系统的authorized_keys文件中。
接下来,在选定的操作系统中,把authorized_keys文件拷贝到其它所有操作系统的对等目录下,即对等用户的HOME目录下的.ssh子目录。例如:
最后,在每个操作系统中,修改authorized_keys的权限模式为600。如:
chmod 600 authorized_keys
为了保证Hadoop的正常运行,需要对SSH对等关系进行测试。选择其中一个操作系统,通过ssh命令调用其它任一操作系统的一条命令,如date,观察是否需要输入对方操作系统中的用户口令,如:
ssh Server2 date
如果在不需要输入对方用户口令的情况下,上述命令获得了对方系统的系统时间,那就说明SSH对等关系已经配置成功。
4、关闭防火墙
在默认情况下,Hadoop的各个node如果运行在不同的操作系统中,它们之间的通信是被防火墙屏蔽的。在实验环境中,完全可以将防火墙关闭,以取得一劳永逸的效果。在生产环境中,防火墙的关闭可能是不被允许的,这时需要求助于系统管理员,修改防火墙的配置,保证各个node之间的通信。例如,以root用户身份执行以下命令,关闭并禁用防火墙。需要注意的是,在不同版本的Linux系统中,这样的命令是不一样的。以下两条命令适用于Redhat/Centos7.x。
systemctlstop firewalld
systemctldisable firewalld
5、端口的规划
随着Hadoop学习的深入,你会发现,在每个Linux操作系统中需要运行多个进程,即各种node,而每个node都需要监听一个或多个端口,整体算下来,一个Hadoop运行环境就需要一大堆端口。Hadoop可以使用默认端口,也可以使用指定的端口。而在生产环境中,端口的使用并不是随意的,管理员可能会分配一定范围的端口给Hadoop。所以在配置Hadoop的过程中,需要与系统管理员和网络管理员保持密切的沟通,共同协商端口的分配。
6、Node的规划
Hadoop中的每个node都需要在操作系统中运行。那些重要的node,应该在单独的操作系统中运行,如HDFS的NameNode,Hbase的HMaster,以及提供底层支持的ZooKeeper等;而其它node,如HDFS的DataNode,Hbase的HRegionServer,可以安排在同一个操作系统中运行。同一类型的多个node,应该分布在不同的操作系统中。
在实验环境中,由于硬件资源有限,每个计算机系统往往需要身兼数职。表1是node规划的一个例子。
表1 Node规划的例子
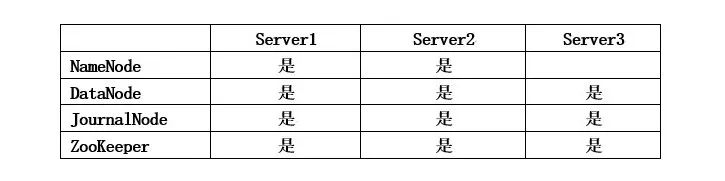
在上述规划中,计算机系统Server1既作为NameNode,又作为DataNode,同时运行JournalNode和ZooKeeper。
编辑:小恒
作者简介:
刘宪军,男,1997年毕业于西北大学计算机科学系,获工学硕士学位。目前主要从事小型机、中间件、数据库、大数据的技术支持和培训工作。
历年出版的专著有:
《Oracle数据库备份、恢复与迁移》 机械工业出版社 2017年1月
《Oracle RAC 11g实战指南》 机械工业出版社 2011年1月
《Oracle 11g 数据库管理员指南》 机械工业出版社 2010年8月
《软件过程管理》 水利水电出版社 2004年
《UNIX系统管理教程》清华大学出版社 2002年
《Windows/Linux/UNIX综合组网技术》清华大学出版社 2002年
作者原创:
《》
《》
《》
《》
每周五《大数据可视化周刊》与您不见不散
以上是关于万丈高楼平地起——大数据配置管理之HDFS(上)的主要内容,如果未能解决你的问题,请参考以下文章