HDFS读写数据过程
Posted 大白猿学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读写数据过程相关的知识,希望对你有一定的参考价值。
一、FileSystem基类
Hadoop提供的FileSystem抽象基类可以被HDFS继承,以实现DistributedFileSystem子类(FileSystem也可以被继承为其他子类,如用HTTP访问相关文件或FTP方式读写文件)。
FileSystem常用的三个方法:open,read和close
二、HDFS读取数据步骤
1. 打开文件:用FileSystem类声明一个实例对象,fs=FileSystem.get(conf),这时会创建实例对象DistributedFileSystem和输入流FsDataInputStream。而这个输入流里面封装了DFSInputStream,它才真正和名称节点打交道(客户只和FsDataInputStream打交道)
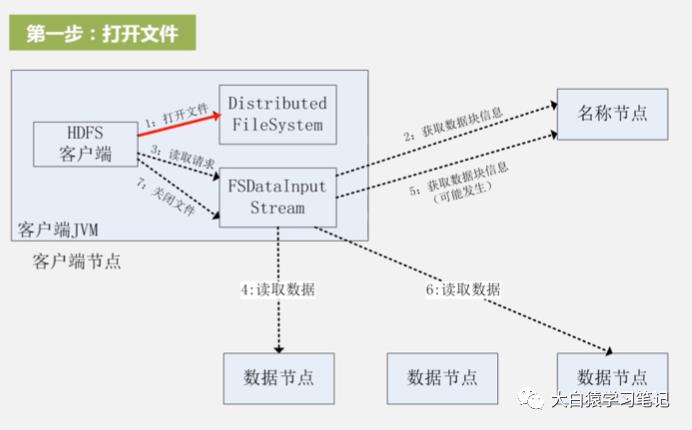
上图中左上的大框是封装起来的
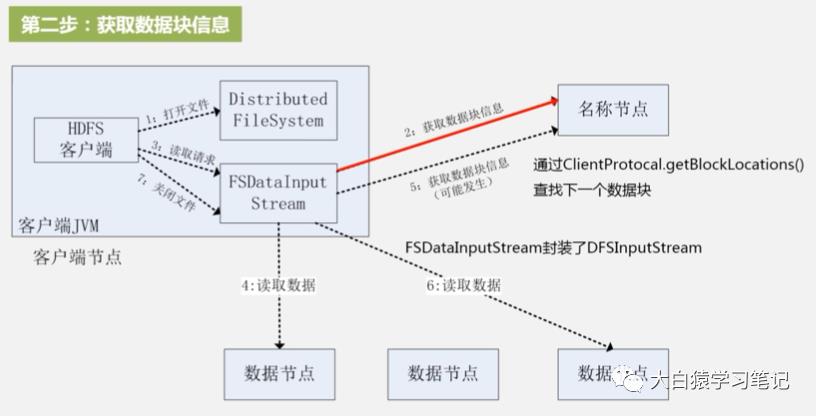
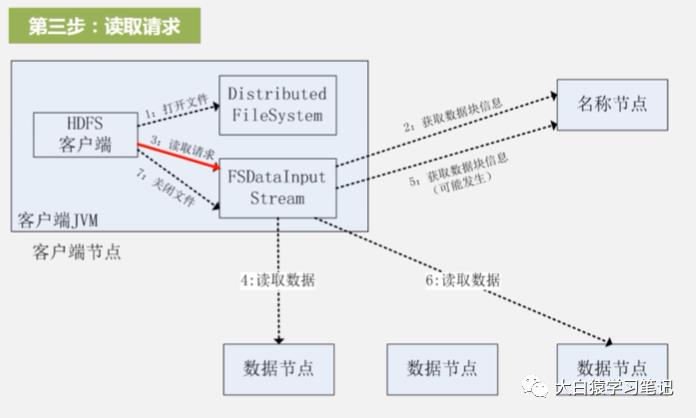
3. 读取请求:调用read函数,根据上一步名称节点返回的数据位置,根据离客户端远近去建立于数据节点的连接(近的先读,远近排序也是名称节点返回的)
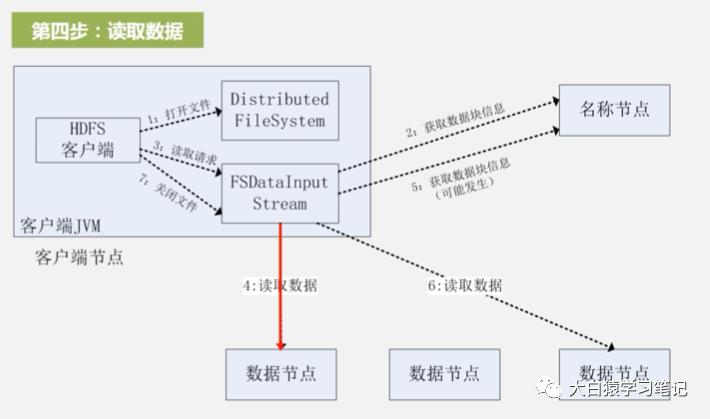
4. 读取数据:把数据从数据节点读到客户端。读完后FsDataInputStream会关闭和此数据节点的连接。
5. 再次获取数据块信息:如果还有其他数据块没读,重复第2步
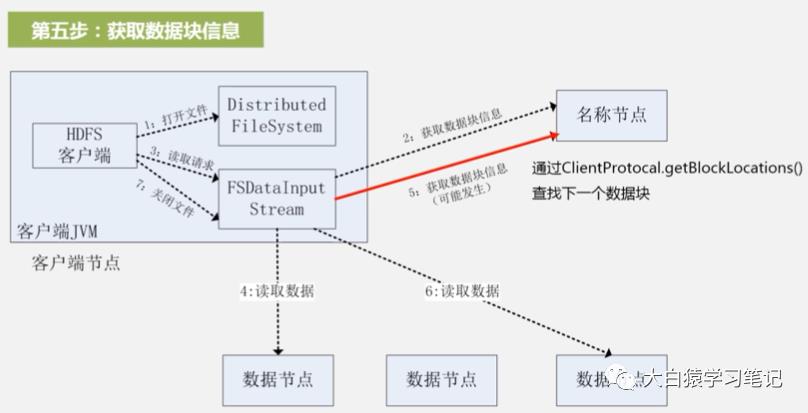
6. 再次读取数据:重复第3、4步
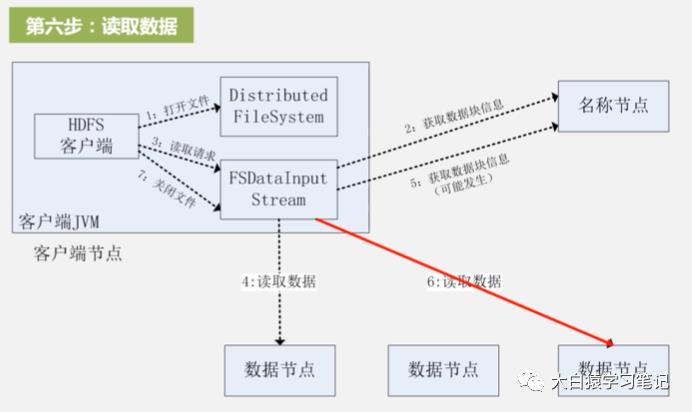
7. 关闭文件:一直重复第5、6步,直到所有目标文件读完,这时就调用输入流FsDataInputStream的关闭操作close来关闭整个文件。至此整个读数据过程结束
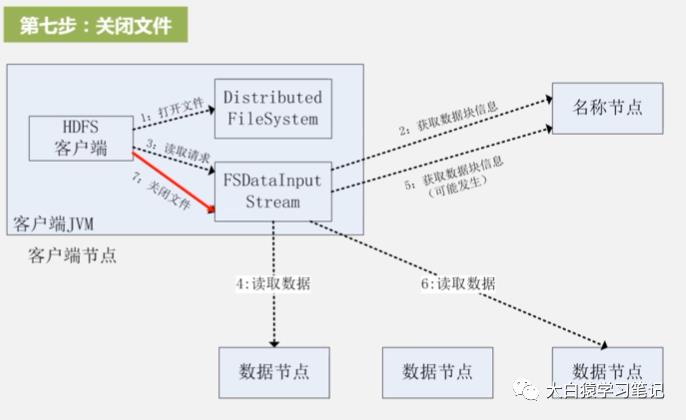
三、HDFS写数据步骤
1. 创建文件请求:用FileSystem实例化一个对象fs,其类型也是DistributedFileSystem。同时创建输出流FsDataOutputStream——实际Hadoop会在后台封装一个DFSOutputStream。与读数据过程类似,前者和客户端打交道,后者和名称节点打交道
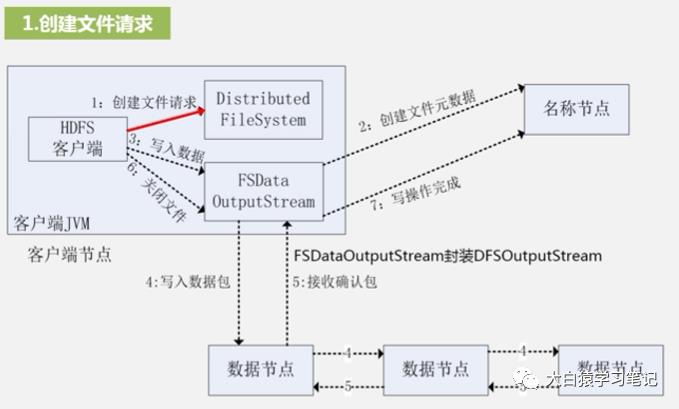
2. 创建文件元数据:DFSOutputStream执行RPC远程调用名称节点,让名称节点再其命名空间中新建一个文件——但在新建前,名称节点会先确认目标文件是否存在以及客户端是否有权限访问
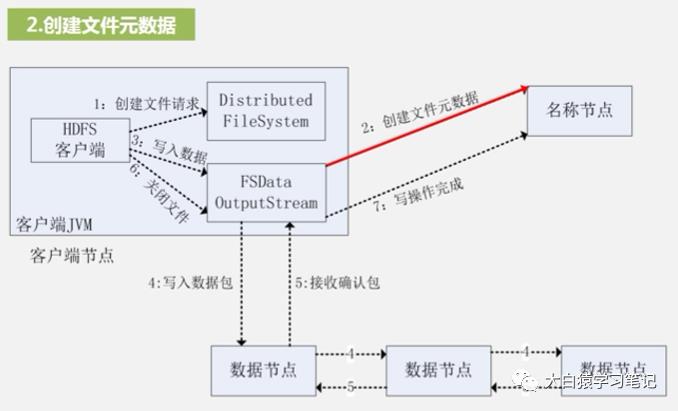
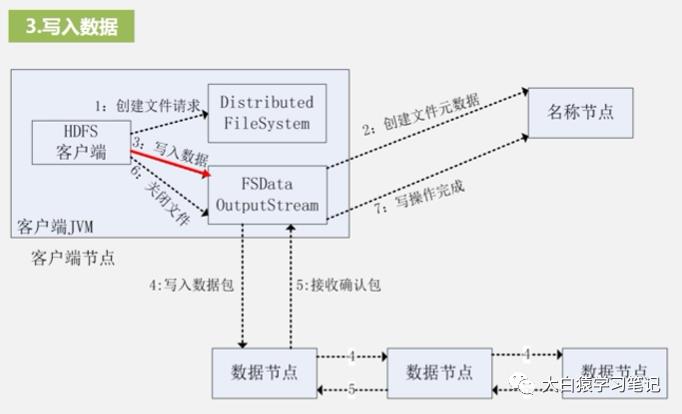
3. 写入数据:HDFS以一种被称为“流水线复制”的高效方式写数据。它把整个数据分包,这些分包被分别放到DFSOutputStream对象的内部队列,然后此对象向名称节点申请保存这些数据块的数据节点
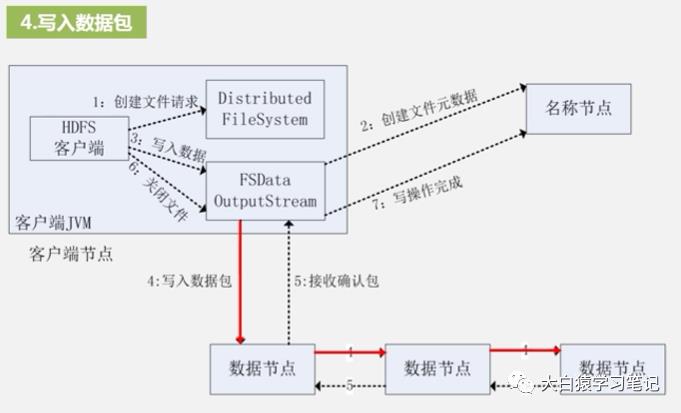
4. 写入数据包:分包先发到第一个数据节点,第一个再把分包复制并发到第二个数据节点,以此类推(类似菊花链)
5. 接受确认分包:确认分包是从最后一个数据节点传到前面一个,前面一个再继续往前传,直到传到客户端。客户端确认都正确了才是成功
6. 关闭文件:写操作完成
值得再次强调:客户端只和输出流FsDataOutputStream直接打交道,而封装在其中的DistributedFileSystem才具体和名称节点打交道
参考:大数据技术原理与应用-厦门大学林子雨
https://www.icourse163.org/learn/XMU-1002335004#/learn/content?type=detail&id=1214310118&cid=1217922276
以上是关于HDFS读写数据过程的主要内容,如果未能解决你的问题,请参考以下文章