HDFS中的文件租约Strom中的LRUMap底层竟然是......
Posted 大数据Kafka技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS中的文件租约Strom中的LRUMap底层竟然是......相关的知识,希望对你有一定的参考价值。
第一章 JDK源码剖析-集合篇
第 8 节
HashMap的兄弟姐妹们
这一节带大家一起过一下HashMap的其他兄弟姐妹。还是围绕一个原理图来讲解核心知识,今天还会给大家举2个开源项目中使用它们的例子。
你之后可以自己按照原理图的思路来看下源码,彻底掌握它们的原理。
LinkedHashMap的源码底层原理
LinkedHashMap继承自HashMap,但是它的底层增加了一个链表来维护插入或者访问顺序,使得LinkedHashMap变动有顺序性。如下图所示:
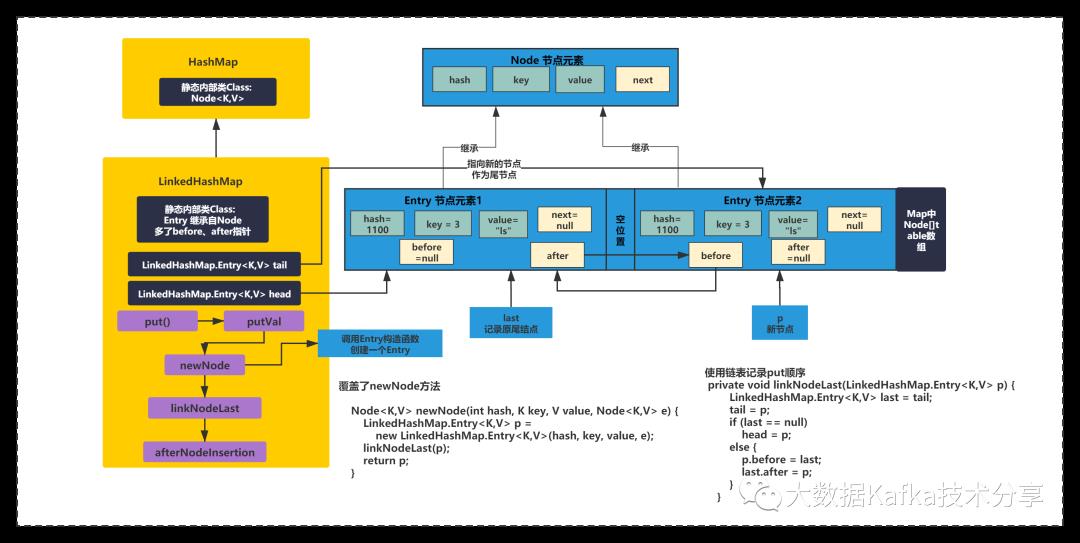
上图中可以看出,LinkedHashMap继承了HashMap,多了两个成员变量,tail和head指针,还使用Entry内部类继承了HashMap的Node内部类,在原有基础上增加了before和after指针。
默认情况下,是按照插入顺序的,也就是put的顺序。LiknedHashMap在put元素的时候会记录用指针,将数组元素的插入顺序记录下来。
通过重写HashMap的newNode()方法,在put方法,插入一个Entry后,Entry的before和last指针类似链表会连起来,并且LinkedHashMap的tail和head指针也会记录下首尾元素。将插入顺序用链表记录下来。
至于访问顺序的情况,你可以在一会后面的例子会提到。
TreeMap的源码底层原理
同理TreeMap也是一个有序的Map,底层是通过红黑树来维持顺序的,并且TreeMap支持自定义排序规则。原理下图所示:
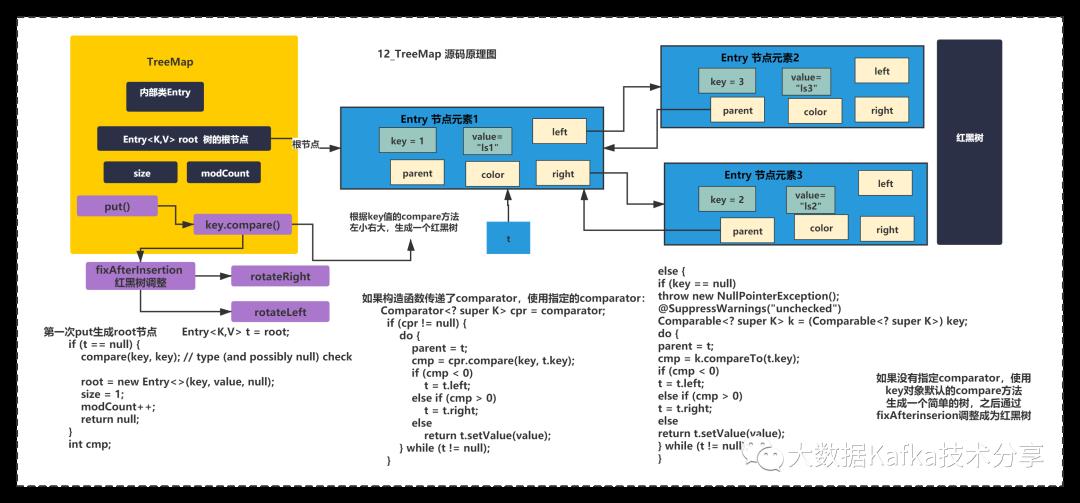
TreeMap没有继承HashMap,他自己实现了put方法,主要逻辑是生成树root节点和普通叶子节点。
刚开始树为空,肯定是进入第一步,生成root节点,创建一个Entry就结束了,这个Entry中多了left和partent、right,color等变量。
创建TreeMap的时候可以指定排序规则,默认不指定使用Key值默认的compare方法,进行排序生成一棵排序后的二叉树,之后调整为红黑树。
而且它没有数组的结构,它就是一个纯粹的红黑树,get的时候通过遍历红黑树获取元素。
在遍历的时候,TreeMap通过EntryIterator进行从小到大的遍历,实现有序访问。
HashTable、HashSet、LinkedHashSet、TreeSet底层原理
最后我们聊一下HashMap的其他兄弟姐妹。为什么这么说呢?
因为HashTable和HashMap核心区别就是使用synchronized保证线程安全,这个和Vector+ArrayList很像。
因为HashSet使用了HashMap,只不过add方法时候的value都是new Object()而已,结合map的特性,同一个key值只能存在一个,map在put的时候,会hash寻址到数组的同一个位置去,然后覆盖原来的值,所以Set是去重的。默认是无序的。核心代码如下:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
因为LinkedHashSet继承了HashSet,此时HashSet通过使用LinkedHashMap是可以进行访问有序的保证。
因为TreeSet也同理,默认是根据key值的compare方法来排序的,可以自定义Comparator,底层使用了TreeMap,add元素时,同样是空的Object,同样去重,但是TreeSet访问是可以有序。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
它们的源码都极其简单, 没什么好研究的。所以重点是,你懂了之前的HashMap、LinkedHashMap、TreeMap才是关键。
下面我们来看一些使用这些集合的场景:
LinkedHashMap应用:Storm中的LRUMap
之前你应该熟悉了LinkedHashMap的的插入有序性。调用put方法时,通过链表记录插入的顺序。但是LinkedHashMap还可以支持访问有序性。按照get方法的访问顺序,进行排序。比如:
这个底层和插入有序很像,也是通过一个变量叫做accessOrder和HashMap的put方法和get中重写预留的方法做到的。
每访问一次元素,会将元素移动链表的指针,将刚访问的元素移动到链表的尾部。
基于这个机制我们可以实现一个LRU的Map,实现有自动失效LRU内存缓存Map,这样当元素个数超过缓存容量时,通过LRU可以保证最近最少访问的元素被移除掉。
如果你看过storm的源码的话,你会看到有这样一个LRUMap实现:
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUMap<A, B> extends LinkedHashMap<A, B> {
private int maxSize;
public LRUMap(int maxSize) {
super(maxSize + 1, 1.0f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(final Map.Entry<A, B> eldest) {
return size() > maxSize;
}
}
这个方法很巧妙的基于LinkedHashMap访问有序,实现了一个LRUMap。
首先通过maxSize限定缓存Map的大小,调用父类构造函数,扩容因子为1.0f,第三个入参表示accessOrder=true。重写了removeEldestEntry。
其次通过LinkedHashMap,在get方法时候,如果accessOrder是true,会将get到的元素,放到链表的尾部。保证Map缓存中最新访问的元素的不会被LRU掉。get方法源码如下:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
可以看到有一个方法afterNodeAccess,通过这个来控制LinkedList访问时,单向链表的顺序,从而达到访问有序。
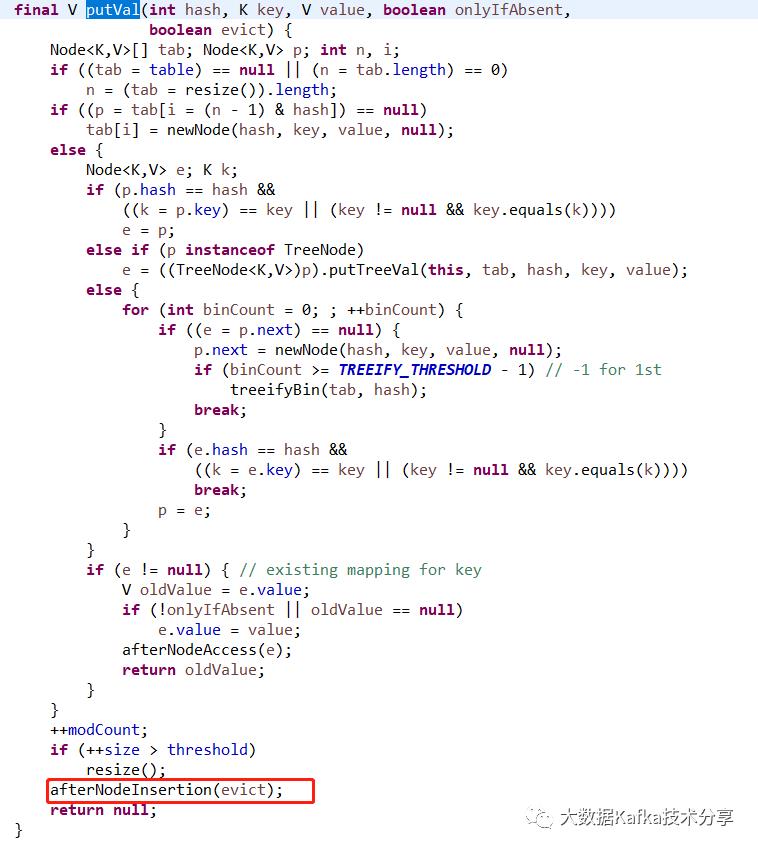
在put方法的时候有一个扩展的入口afterNodeInsertion中,HashMap默认这个方法是空的,什么都不做。但是LinkedHashMap实现了这个方法,并且通过removeEldestEntry+accessOrder控制,如果访问有序参数为true,并且头节点有元素,且 removeEldestEntry 满足,即size() > maxSize,缓存大小达到上限maxSize,会进行一次removeNode操作,移除链表第一个元素。第一个元素就是最近最少访问的元素。如下图所示:
HashMap的put方法: afterNodeInsertion回调入口
TreeSet和TreeMap应用:HDFS中文件租约时长维护
在HDFS中LeaseManager,有一个非常经典契约检查的机制,对所有的契约,按照续约的时间在TreeSet里排序,后面检查的时候,每次就挑最老的那个契约来检查,是否超过60分钟。如果超过,就释放契约再检查第二老的那个契约,如果最老的契约都没过期,那就说明其他的契约肯定都没过期。
用这个方法,可以巧妙的避免说,后台线程每隔一定时间,就要把所有的契约都遍历一遍来检查里面的最近一次续约的时间
如果一个客户端申请契约过后,超过1小时,都还没有续约,那么这个契约会被自动释放掉,这是他的一个很重要的机制。
如下图所示:
好了,到这里,《JDK源码成长记》集合篇的知识基本就带大家学习完了。当然,你一定要结合学到的,不断自己看源码分析思路,之后讲给同事,和他们讨论一下,才能更多的融会贯通。而不是看过文章之后,80%还给我了。
你可以在评论区回复你遇见的使用这些集合的场景,欢迎你评论。
你也可以搜索下你们的业务代码,看看使用了哪些集合类,怎么用的,有没什么隐患?
下一篇我会进行章节总结,也会给大家提供一些常见面试题,让大家检测下学习成果。相信大家掌握了源码原理后,无论是看源码,还是面试,或者应用都可以游刃有余。
金句甜点
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:坚持的三个秘诀之一个性化。
所以,当你选择你能坚持而且喜欢的,变成一个好的习惯,还一直提醒自己觉得值,就一定能坚持下来。记住坚持的秘诀视觉化、目标化、个性化,你可以试试。
最后,大家可以在阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。
欢迎大家在评论区留言和我交流。
更新说明:每周1,3,5更新一篇文章。
(声明:JDK源码成长记基于JDK 1.8版本,部分章节会提到旧版本特点)
以上是关于HDFS中的文件租约Strom中的LRUMap底层竟然是......的主要内容,如果未能解决你的问题,请参考以下文章
HDFS超租约异常总结(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException)
kafka-connect-hdfs重启,进去RECOVERY状态,从hadoop hdfs拿租约,很正常,但是也太久了吧