知识干货 | 大数据全解 HDFS分布式文件系统
Posted 智汇云校
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识干货 | 大数据全解 HDFS分布式文件系统相关的知识,希望对你有一定的参考价值。
Hadoop分布式文件系统(HDFS)是一种旨在在商品硬件上运行的分布式文件系统。
HDFS具有高度的容错能力,旨在部署在低成本硬件上。
HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。
HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。
HDFS最初是作为ApacheNutch Web搜索引擎项目的基础结构而构建的。
HDFS是ApacheHadoop Core项目的一部分。
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
目前的分布式文件系统所采用的的计算机集群都是由普通硬件构成的,这就大大降低了硬件上的开销。
HDFS默认一个块128MB,一个文件被分成多个块,以块作为存储单位。
块的大小远远大于普通文件系统,可以最小化寻址开销。
|
|
|
|
|
|
|
|
|
|
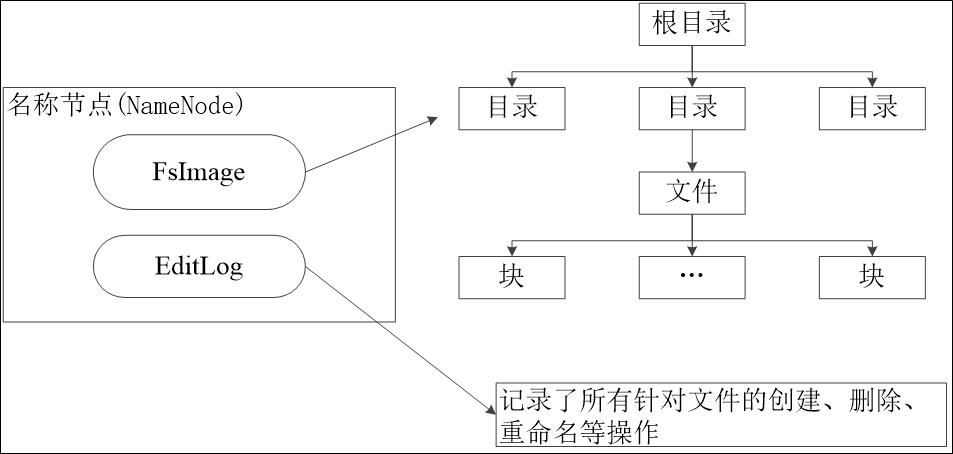
保存文件,block,datanode之间的映射关系
|
维护了block id 到datanode本地文件的映射关系
|
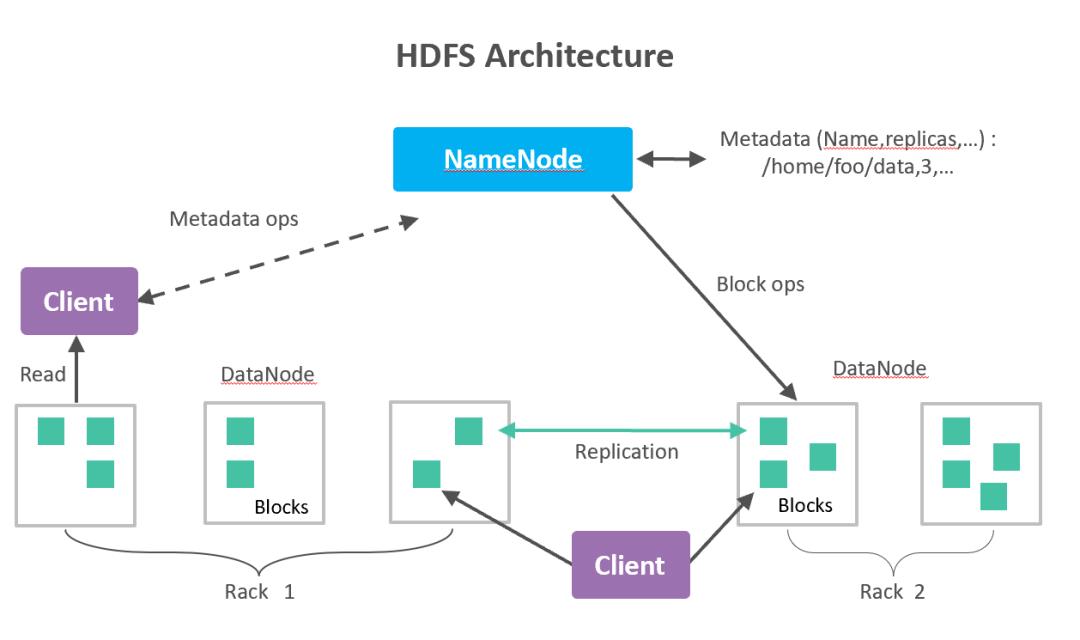
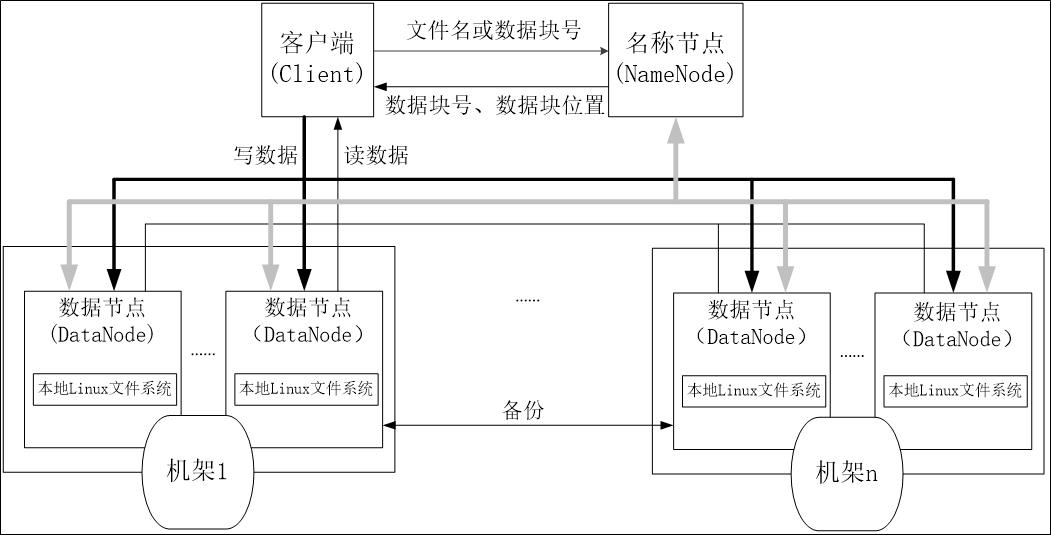
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等。
NameNode维护文件系统命名空间。对文件系统命名空间或其属性的任何更改均由NameNode记录。
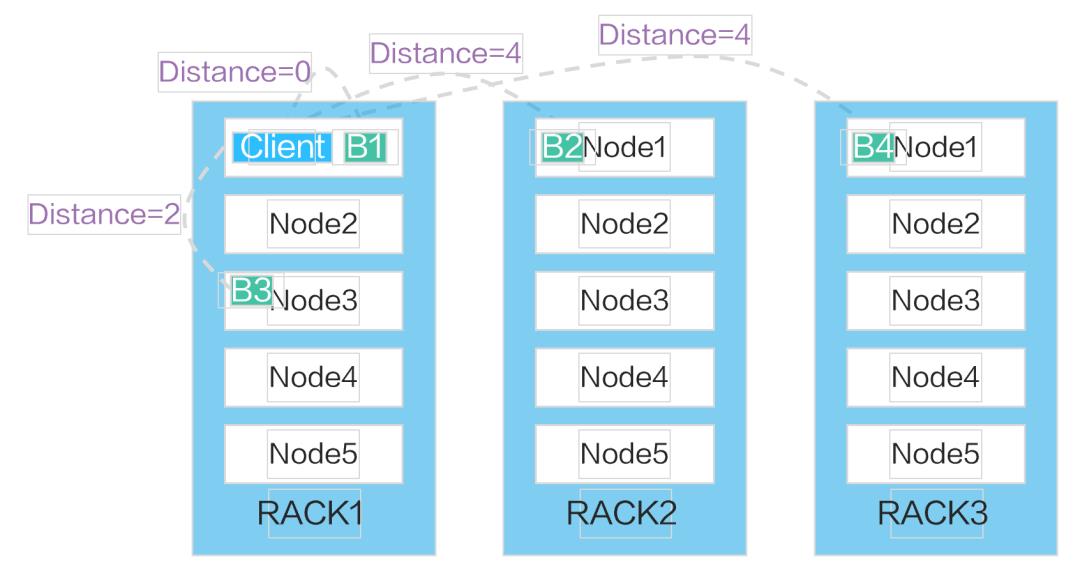
HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。
所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。
客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。
名称节点和数据节点之间则使用数据节点协议进行交互。
客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
客户端是用户操作HDFS最常用的方式,HDFS在部署时都提供了客户端。
HDFS客户端是一个库,包含HDFS文件系统接口,这些接口隐藏了HDFS实现中的大部分复杂性。
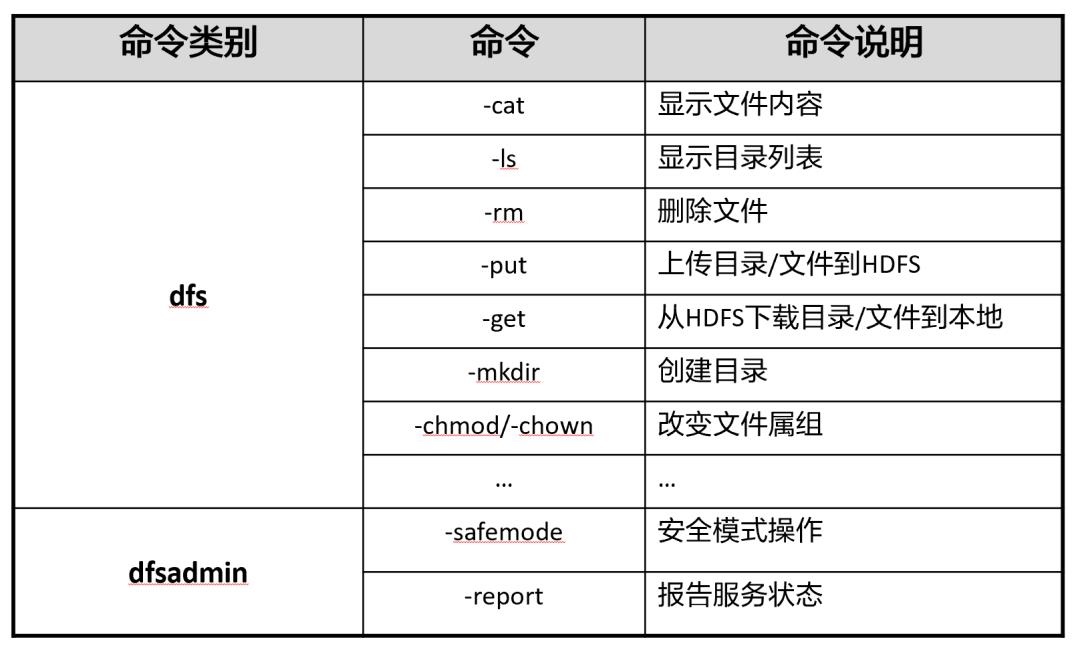
客户端可以支持打开、读取、写入等常见的操作,并且提供了类似shell的命令行方式来访问HDFS中的数据。
HDFS也提供了Java API,作为应用程序访问文件系统的客户端编程接口。
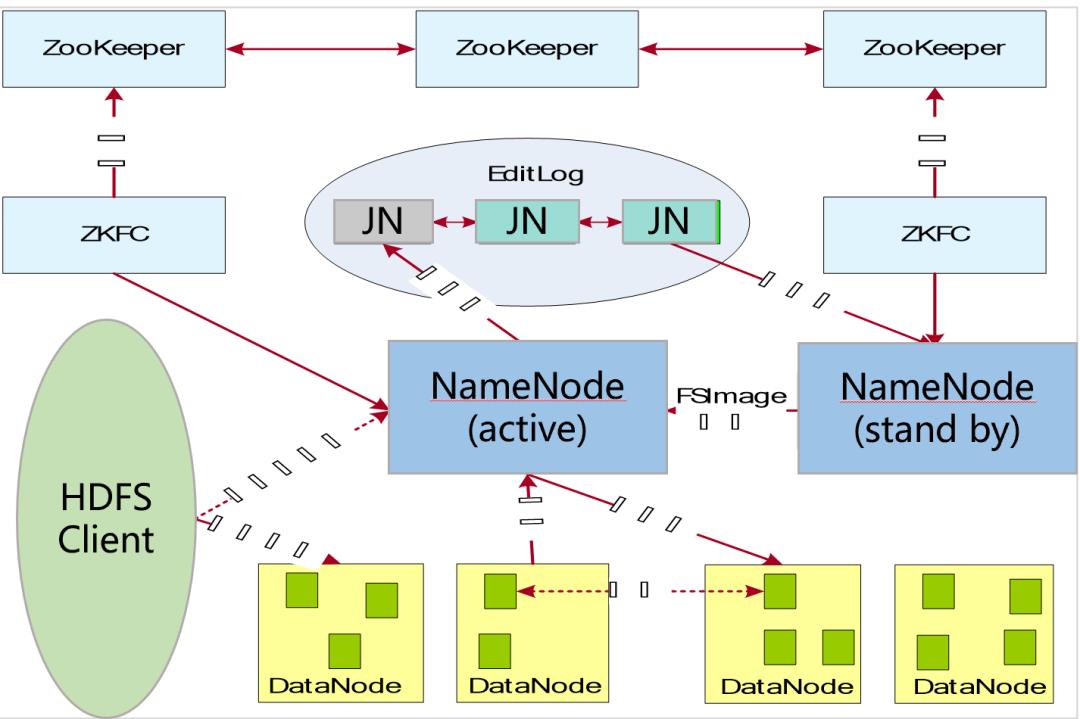
HDFS只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了一些明显的局限性,具体如下:
命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
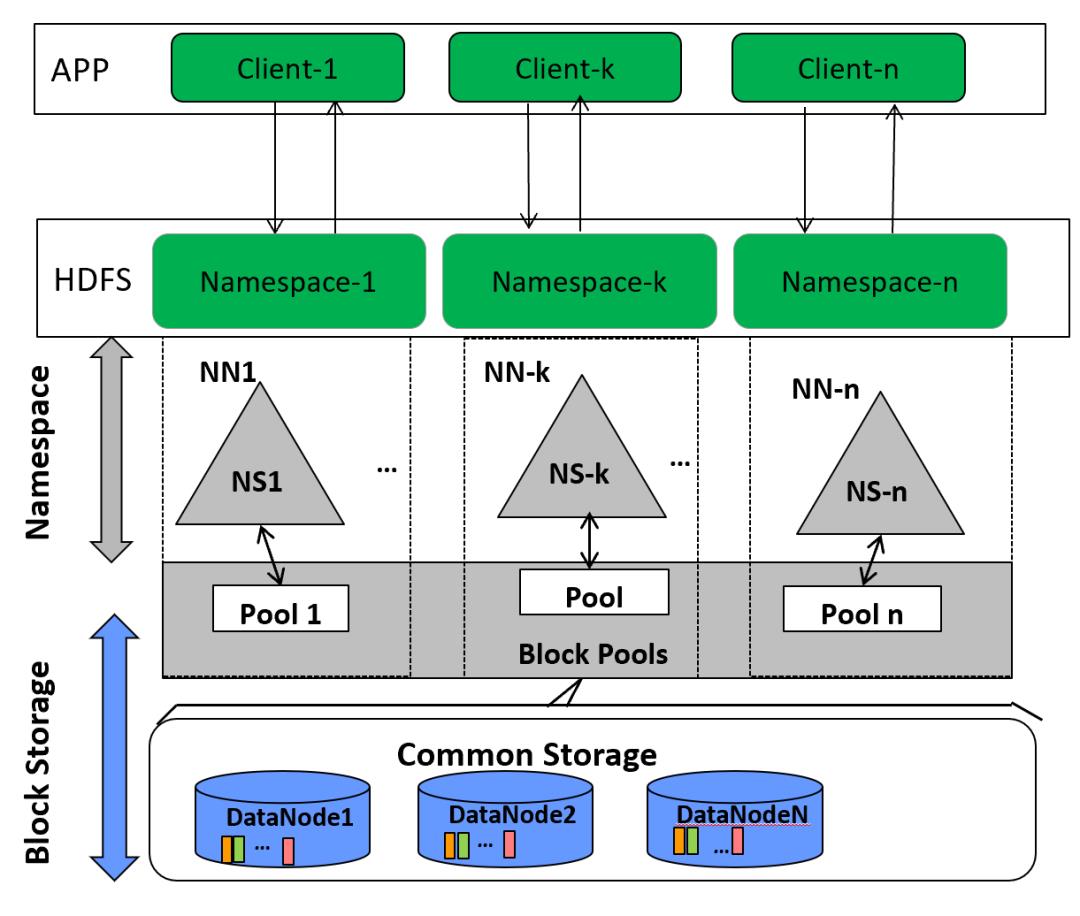
隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。
集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
HDFS主要目的是保证存储数据完整性,对于各组件的失效,做了可靠性处理。
DataNode向NameNode周期上报失败时,NameNode发起副本重建动作以恢复丢失副本。
HDFS架构设计了数据均衡机制,此机制保证数据在各个DataNode上分布是平均的。
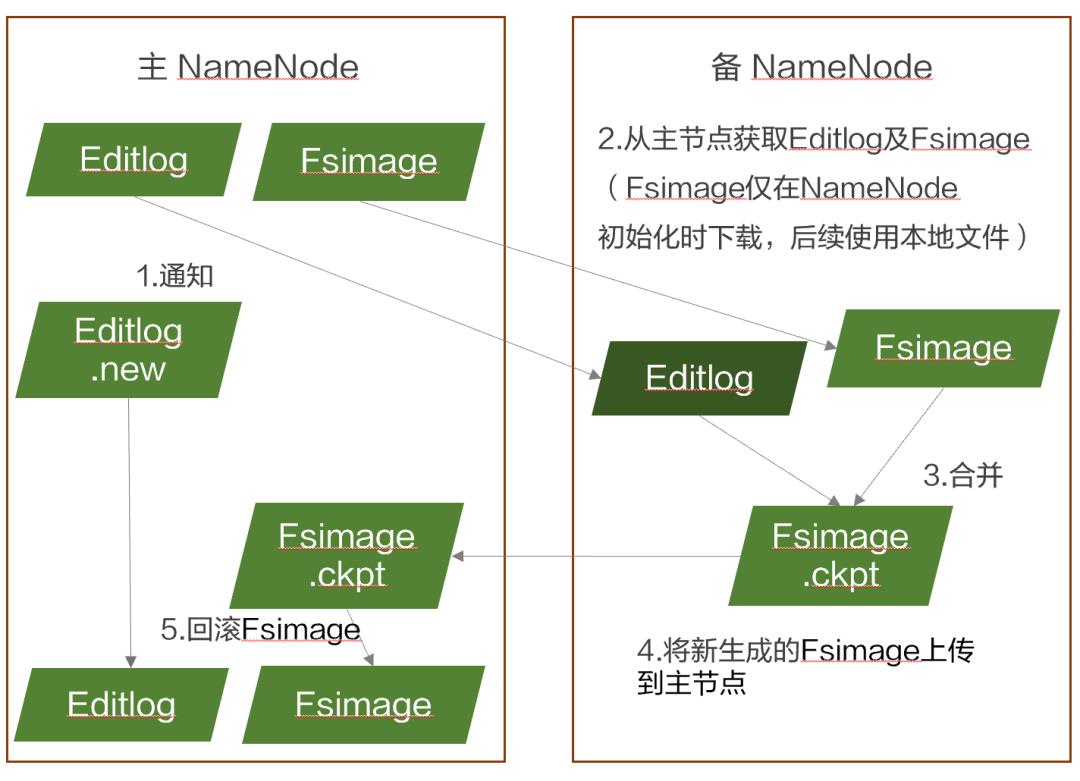
采用日志机制操作元数据,同时元数据存放在主备NameNode上。
快照机制实现了文件系统常见的快照机制,保证数据误操作时,能及时恢复。
HDFS提供独有安全模式机制,在数据节点故障,硬盘故障时,能防止故障扩散。
数据存储以数据块为单位,存储在操作系统的HDFS文件系统上。
提供JAVAAPI,HTTP方式,SHELL方式访问HDFS数据。
支持HDFS中的纠删码ErasureEncoding
DataNode内部添加了负载均衡 DiskBalancer
以上是关于知识干货 | 大数据全解 HDFS分布式文件系统的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点# 大数据技术栈之Hadoop-HDFS
#yyds干货盘点#大数据基础HDFS练习
HDFS知识总结
HDFS知识点
好程序员大数据学习路线Hadoop学习干货分享
win7系统分几位吗?