赠书:聊聊「分布式架构」那些事儿
Posted 程序猿DD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赠书:聊聊「分布式架构」那些事儿相关的知识,希望对你有一定的参考价值。
什么是分布式架构?
分布式架构是分布式计算技术的应用和工具,其中J2EE技术应用较为广泛,它简化和规范多层分布式企业应用系统的开发和部署,它可以给分布式应用软件提供在各种技术间共享资源的平台
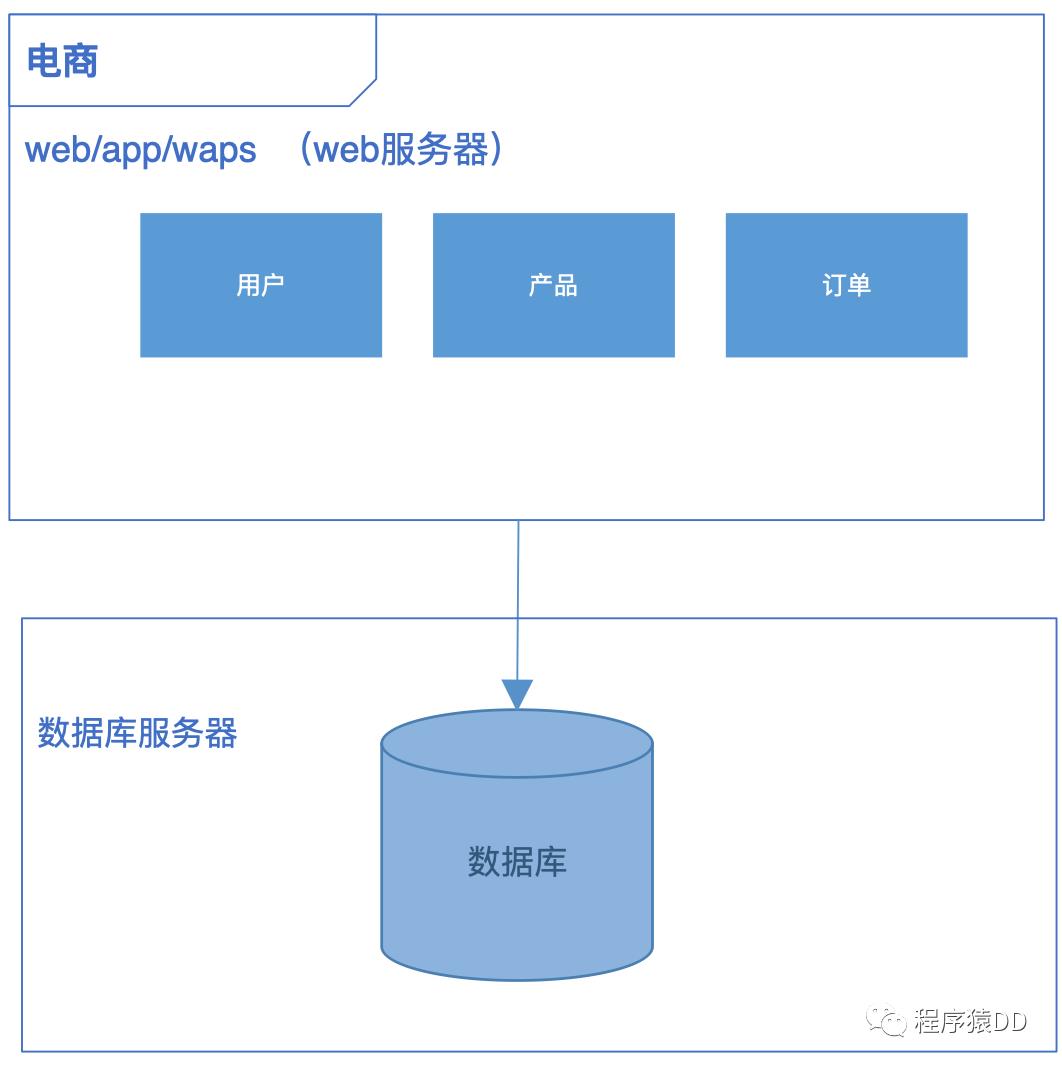
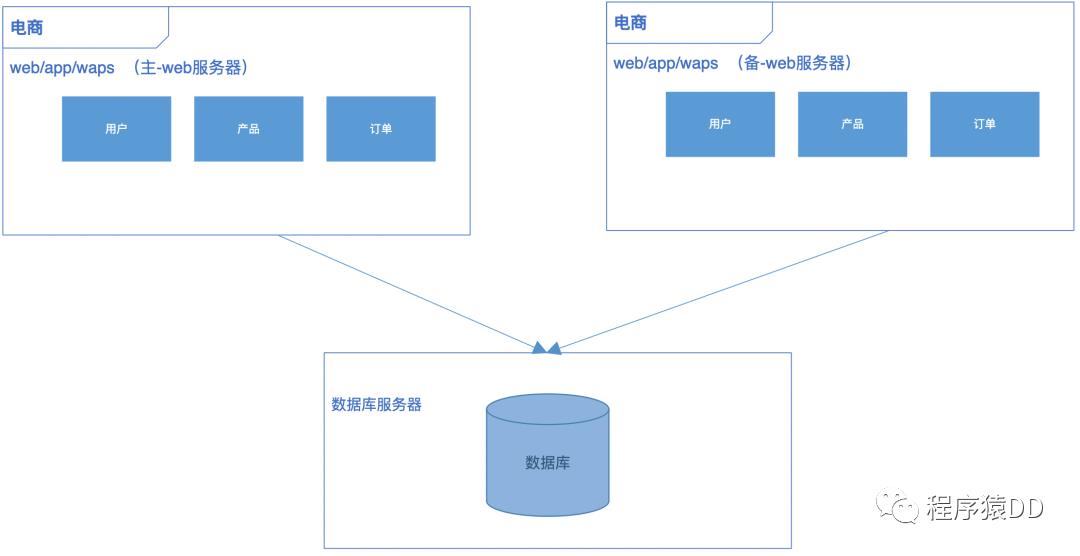
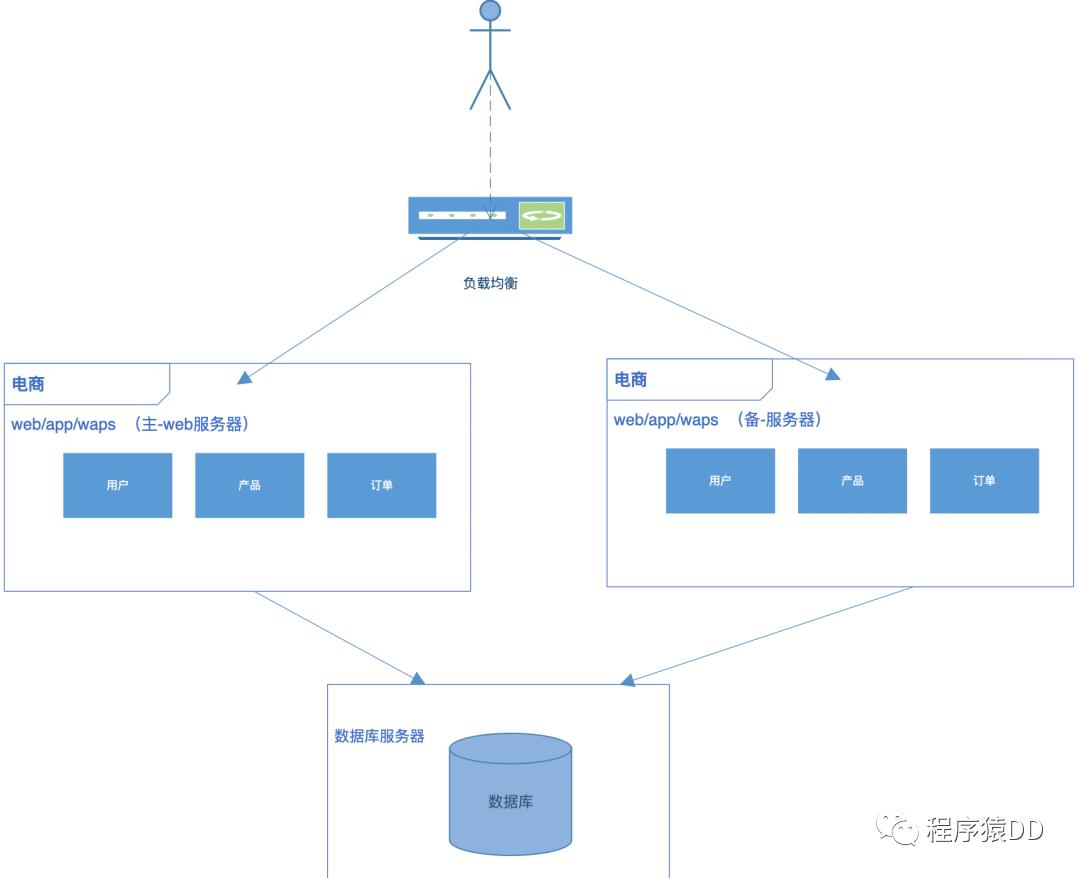
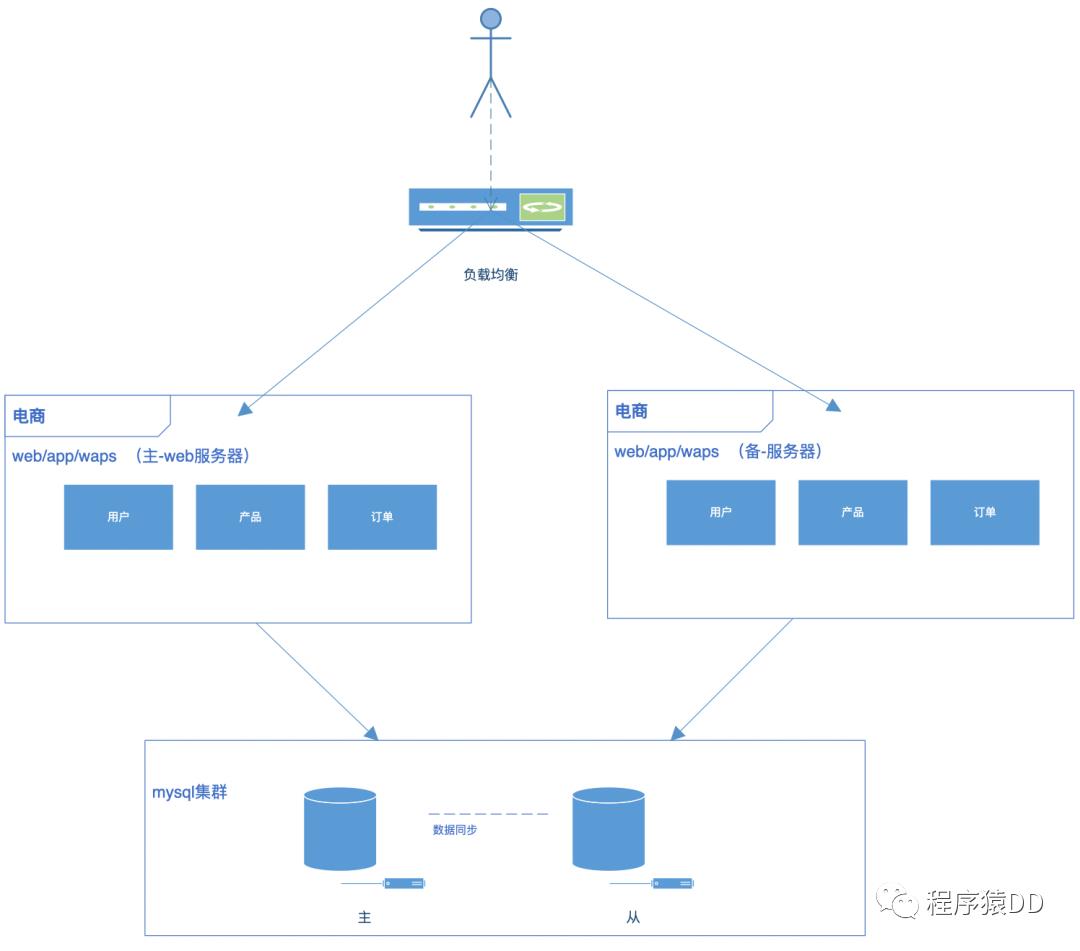
众所周知,传统架构单一无分层,模块之间耦合性过高导致稳定性和扩展性较差,无法满足互联网高速迭代变化的脚步,技术架构也会发生很大变化。传统架构逐渐分化为分布式架构。提供更稳定、容错、高可用的特质。演变过程如下图所示。
阶段1
阶段2
阶段3
阶段4
阶段5
设计理念:分布式架构的核心理念按照一定维度(功能、业务、领域)等,对系统进行拆分,通过合理的拆分结构,实现各业务模块解耦,同时通过系统级容错设计,在廉价硬件基础设施上构建起高可用、可扩展的开放技术体系。
目标:设计目标可以明确方向,通过设计驱动和方向的把控,朝着既定方向前行并最终实现目标。设计目标分为以下方面:
系统拆分
以业务为导向,充分了解系统业务模型,按不同层面的业务模型上可以划分为主模型、次模型。业务模型在一定的比例上能够凸显出系统的业务领域及边界;
业务依赖范围,由于业务存在重复依赖,从业务边界中按照业务功能去细分;
把拆分结构图梳理出来,按照系统周边影响从小到大逐渐切换;
拆分过程中尽量不要引入新的技术或者方案,如需讨论评估后再实施。
业务模块解耦
拆分之前可能模块和模块之间、系统和系统之间有非常强的依赖,所以我们在拆分过程中需要思考,哪些模块需要减少依赖,依赖越少,独立性越强
系统容错
架构设计层面(重试、服务降级、熔断和限流)
业务功能层面(幂等、异步处理、事务补偿机制)
高可用
单点系统面临严重高可用问题,所以在设计过程中要尽量避免系统的单点出现,保证系统处于多机状态,俗称冗余。冗余指重复配置系统某些部件,当系统发生故障不可用时,冗余配置的部件介入并承担故障部件的工作,减少系统的故障时间。
通过设计和监控可以提高系统正常提供服务的可靠性,那么,如何才能保障系统的高可用。
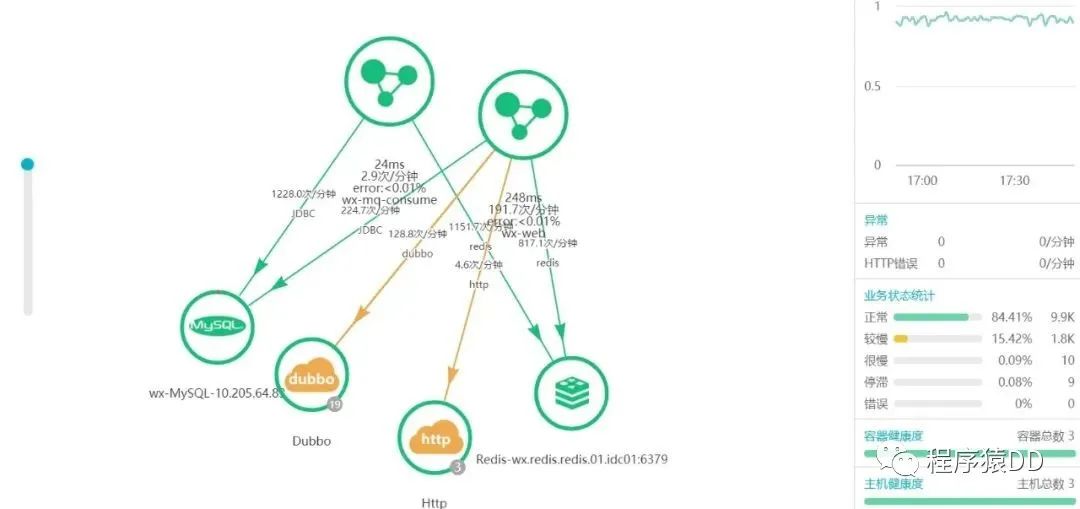
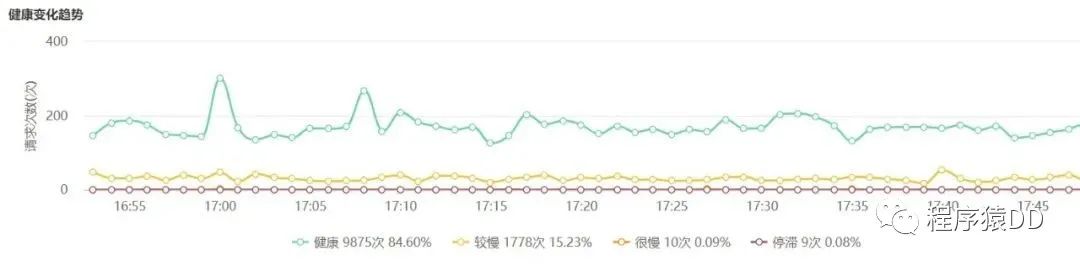
•适用于对数据密集/实时要求比较高的项目或系统•适用于对服务器高可用运用指数较高的系统•适用于大型业务复杂/统计类系统
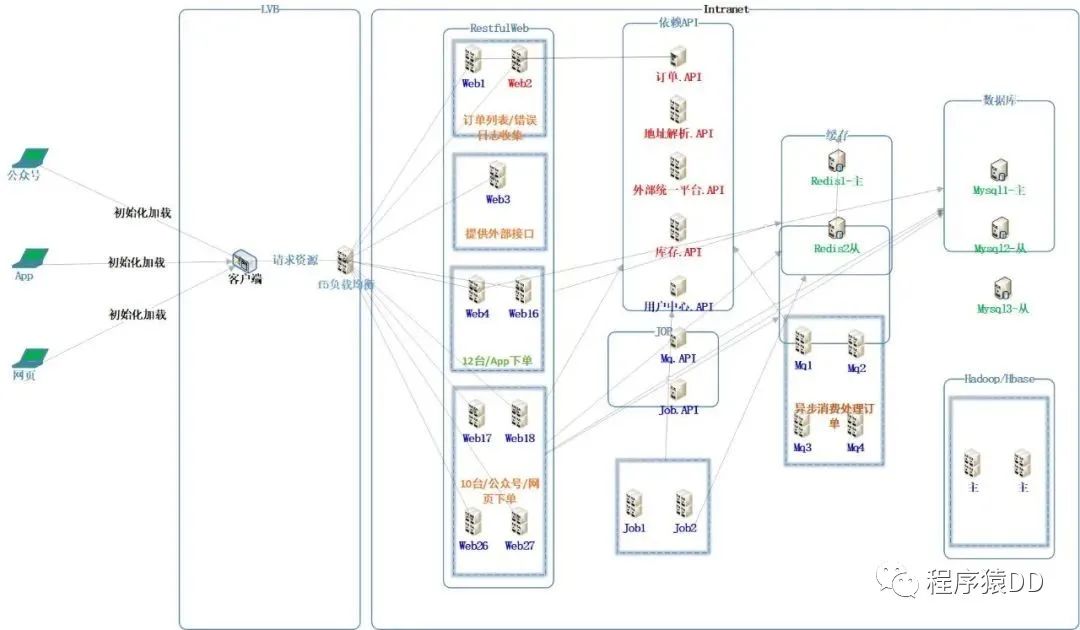
•网络因素
网络延迟:延迟是指在传输介质中传输所用的时间,如部署在同个机房,网络IO传输相对较快,但是很多公司为了增加系统的可用性,有多套机房(线上、线下)等,此时会面临跨机房、跨网络传输。尤其跨IDC,网络IO会存在不确定性,出现延迟、超时等情况,大家都知道宽带有瓶颈可以换网卡,但从根本上不能解决物理延迟。由于这些现象会给整个设计带来整体性的难点,我们在做分布式架构设计的同时需要考虑这些要素,并且提供相关高效解决方案,从而规避此问题
网络故障:若出现网络故障问题,可以先了解数据是以什么协议方式在网络中传输导致丢包、错乱。然后采用比较稳定的TCP网络协议进行传输
•服务可用性
a.由于探针监控是定时去请求访问服务器,通过请求回应来收集服务器状态。定时需设置在合理范围值内,太短会给服务器带来压力,太长会导致不能及时收集报错信息,而错过最佳时机。基于以上情况,可以采用服务器集群化的方式,根据系统场景,设置合理探针请求频率,当发现异常及时剔除替换
b. 为了保证服务器正常运行,可对服务器进行监控,如探针、心跳检测等,而这些仅仅是针对服务器的运行数据和日志分析。为了提高服务器服务的可用性,可进一步实施服务器负载均衡、主从切换、故障转移等
•数据一致性
a. 可以从系统构建层面减少这种现象发生,采用分布式事务进行处理,存在牺牲一部分性能去弥补数据一致性。
b. 由于数据架构需要提供多节点部署,不同节点之间通信存在数据差异,在很多场景下会往往产生脏数据、异常数据,让业务不能正常运转。数据一致性指,关联数据之间的逻辑关系是否正确和完整,那么分布式情况下如何让不同模块之间的数据保证完整性、一致性。
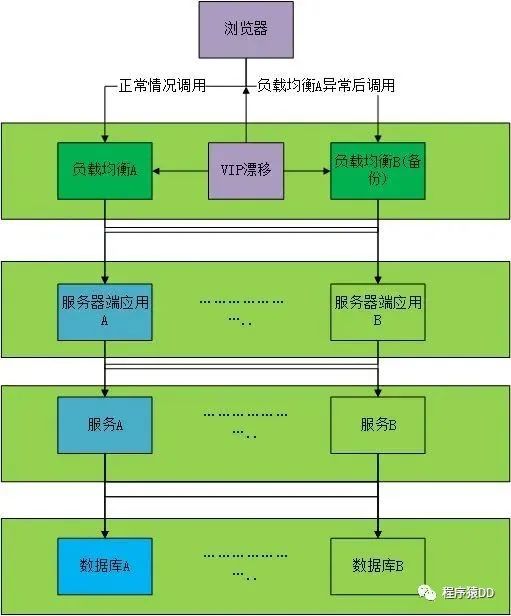
•系统宕机
系统业务量逐渐增多,导致系统压力增大,通过监控和各方面指标发现系统频繁报警,通过优化让系统变的稳定,降低负载。最直接的方式是增加系统容量,调整系统参数,但是通过硬件扩展并非解决问题的最优方式,会存在以下弊端
硬件设备费用高额后续会带来更大的维护代价
进一步优化过程需要垂直或者水平拆分业务系统,按照一定维度拆分成多个模块,降低耦合性,通过合理的设计方案,从端到端、点到点优化,让系统变得健壮,为后续复杂业务提供模块化管理和运营。
分布式的架构体系具有良好的横向扩展性,通过横向扩展机器能够快速高效提高系统的并发量和吞吐量,为复杂的业务系统提供良好支撑。而分布式架构体系调用过程较长,从外界流量入口分发、代理服务、网络传输、容器、应用服务、数据存储,存在很高的优化空间,通过合理的设计方案能让系统承载更多更高的指标,从而稳定运行.
•系统瘫痪
很多外部因素也会导致系统瘫痪,如机房停电、线路关闭、网络堵塞等,因此需要一套完整的分布式架构方案(高可用、监控、故障转移等)来支撑。
系统在构建时期需要考虑这些外在因素,然后构思设计相应的处理方案,通过设计方案然后落地,在测试环境中演练外在因素导致系统瘫痪场景,不断探索、改进、完善,这样,当外部因素真的出现时,系统可以从容面对,从侧面凸显出系统的健壮。
分布式架构体系中针对以上场景有众多解决方案,会从设计之初就会考虑这些因素,确保系统是可用的、可靠的。而多机房部署就能从根源上解决由机房停电引起的事故.
•系统故障
当系统发生故障,因系统构建庞大,维修排查故障时间过久,影响用户群体使用。
分布式架构中讲究系统拆分模块化,使用更轻量级的模块、可用的部署策略,从一定程度上规避掉故障风险,如出现故障,通过有效的故障转移方式能让系统在短时间之内正常服务
•系统臃肿
分布式架构中可拆分模块化,模块细化后可读性、维护性会变得简单明了,针对细化后的模块可更专注开发和优化,系统庞大内核聚集多,导致臃肿。迭代维护运营成本高额,风险过大
•阿里巴巴
初级阶段阿里巴巴已拥有规模庞大的用户,业务体系复杂,业务之间相互依赖较高,不能给客户提供好的服务和体验。
阿里巴巴规划使用分布式架构,通过多条业务线的拆分,让业务模块之间相互解耦,减低依赖,提高系统间的容错和稳定性。
阿里巴巴在此期间研发了多项分布式技术和框架,如:Dubbo(微服务)、Rocketmq(消息队列)、OSS(资源存储)、Tair(缓存)、Xdb(数据库)等等。其中面对国内每年的’双11‘,淘宝/天猫等商城系统每年都会面对较大的压力,压力多方面来自于用户数的增加(多用户的请求频率和次数),之所以能够提供给用户良好的体验和使用量,阿里的技术体系尤为重要,每年的’双11‘都是阿里的自家技术的实战和分析。技术创新、技术沉淀让阿里在国内首屈一指
•百度
百度是一家做搜索引擎及其人工智能的企业,搜索业务场景复杂多变,搜索涉及信息较广。最初搜索体验不好,搜索结果不太准确。
百度拥有’独立搜索引擎核心技术‘,每天面对来自百余个国家和地区的数十亿次搜索请求,为了满足用户需求和提高体验,不断坚持技术创新、优化分布式搜索引擎、分布式存储(Tera)
分布式发展过程经历了传统单体结构、集群化结构等。它的发展都离不开业务场景,业务场景是驱动技术架构变革的载体。本章重点讲述了大型系统在分布式环境中面临的问题,分布式环境中存在诸多不确定性因素,系统从构建到发展成型,会经历很多阶段,而不同阶段需要关注点不同,所以设计之初需考虑全面。从而让系统在面临诸多不确定因素时有多种容错方式,整体提高系统的稳定性。
以上是关于赠书:聊聊「分布式架构」那些事儿的主要内容,如果未能解决你的问题,请参考以下文章
Binary classification - 聊聊评价指标的那些事儿实战篇