分布式架构的那些事儿之一:1+1=2么?
Posted 老鸟论IT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构的那些事儿之一:1+1=2么?相关的知识,希望对你有一定的参考价值。
本节要点:
-scale-up和scale-out的恩怨情仇
-分布式架构的发展历程
-分布式能带来多大的效能收益
-横向扩展架构的性能极限在哪里
讲计算机系统架构之前,我们先插播一段轻松的话题。
作为看着武侠小说成长起来的一代人,我们都知道武林之中要提高武功水平,一直有两条路线。一条路线是打造深厚的内力,典型代表觉远和尚,修炼《九阳真经》,内力之深厚一时无两,但是招式上的白痴;更有甚者如虚竹,靠着“借来”的内力一样可以短时间内跻身顶尖高手行列;另一条路线是学习精妙的招式,典型代表令狐冲,内力渣渣,修习《独孤九剑》,招式精绝天下。当然,要成为最强者,必须内力和招式兼修,如乔峰,靠着强悍内力和绝妙的降龙十八掌,以一敌万,空前绝后。把中国功夫推广到全世界的李小龙,其举世公认的功夫特点便是爆发力、速度和动作。“一个武打者,除了有像野兽一般的爆发力以外,技术也应该是高明合理的,不能是死缠烂打。武打,就像舞蹈、围棋一样,需要存在转换动作,需要有真假变化,而这些李小龙都做到了。”
学招式相对容易,修习内力则非三两年之功,因此武侠小说里很多心术不正之人不好好练功,试图靠休息速成招法提高水平,轻者一事无成,重者走火入魔,害人害己。所以很多武林前辈告诫后来者,先要打基础培养内力,然后才是学习招式,方为武学正道。
为何一篇讲系统架构的文章,却开篇扯起毫无关系的武侠小说呢,看官莫急,这里面有莫大的关联。如果把系统比做人,功力比作系统性能,则自从计算机发明以来,无数仁人志士一直想尽办法提高系统的性能。而提高系统性能的方法,同武术之道一样,也有两条路线,一条是靠内力深厚(单机/核计算能力),另一条是靠招式精妙(分布式/并行架构设计)。
前者的技术路线,是系统架构的核心功能逻辑实体以单机部署为中心,辅以HA主备等技术实现故障切换(failure over),系统性能的提升靠着硬件性能的向上扩展(scale-up)实现,也就是俗称的硬件扩容和升级换代;后者的技术路线,是系统架构的核心功能逻辑实体部署在多个服务器上,通过多个服务器处理能力的协同工作来实现单台服务器远远无法达到的性能,系统性能的提升靠着横向增加服务器节点(scale-out)来实现。
稍微有点计算机系统架构知识的人都可以直观感觉到,scale-up的架构实现简单,容易维护;而scale-out的架构需要付出很多额外的设计和开发工作来实现多个节点的协调和控制。笼统地看起来,不管是系统规划、建设、设计还是开发者,采用scale-up架构都比scale-out架构更省事更省心,那么真是这样的么?
回顾计算机的发展历史,自从1945年冯•诺依曼研制出EDVAC,奠定了现代计算机的基础;随后,蓝色巨人开始引领计算机的发展事业,并在1964年推出了划时代的System/360大型计算机,宣告了现在计算机在商业企业领域应用时代的来临;1981年,IBM又推出了世界上第一台个人电脑,又宣告了个人使用计算机时代的来临。随着计算机在商用领域的发展,系统架构设计的理论和实践也急速发展。
从20世纪70年代开始,计算机先驱们开始关注scale-out架构的技术,一系列关于分布式架构的基础理论研究开始奠基。但是从20世纪70年代到21世纪初叶,整整30年计算机工业的高速发展,scale-up架构牢牢占据了商业企业领域计算机系统架构的绝对主流,scale-out架构则只在另外一个平行世界——高性能计算(HPC)领域守住阵地默默发展。这到底是为什么呢?
要知道这个问题的答案,要从这个鼎鼎大名的人物说起:Gordon·Moore(戈登·摩尔),计算机行业的传奇人物,科学家中的富豪,富豪中的科学家。
1965年的一天,摩尔正在仙童半导体公司捣鼓芯片技术,他离开硅晶体车间坐下来,拿了一把尺子和一张纸,画了个草图。纵轴代表芯片的复杂度,横轴为时间,结果是很有规律的几何增长。他把这一发现发表在当年第35期《电子》杂志上,他预计芯片中的晶体管和电阻器的数量每年会翻番,半导体的性能与容量将以指数级增长,并且这种增长趋势将继续延续下去,这就是大名鼎鼎的“摩尔定律”。1975年,摩尔又修正了摩尔定律,他认为每隔24个月,晶体管的数量将翻番。这本是摩尔本人大胆假设的一句话,但是后来计算机工业的发展轨迹却与这个预测十分吻合。
看看下面这张图,“1971年-2011年处理器芯片发展情况统计”,纵轴表示微处理器芯片中晶体管的数量,横轴表示时间。从计算机工业实际发展的曲线来看,“摩尔定律”得到了惊人的“贯彻”。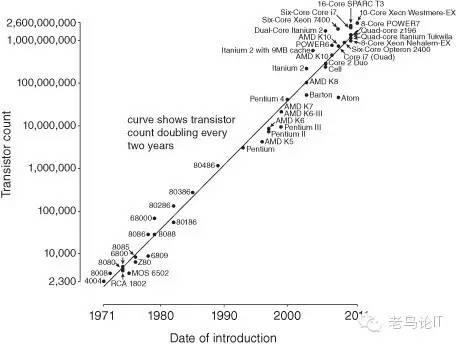
正是因为计算机芯片的稳定发展速度,使得单机的性能每18个月性能提升一倍,价格下降到二分之一,因此采用scale-up架构设计的系统可以稳定地享受“摩尔定律”的性能红利,通过硬件的升级换代稳定地提高性能。而每18个月性能翻倍的速度,也足以满足当时商业生产和个人拥护使用需求的发展速度。各位跟着PC成长起来的这一代人,还记得各大城市曾经生意兴隆的电脑组装卖场,买电脑,升级电脑,换新电脑曾经是每个学生的头等大事,微软和Intel的Wintel联盟也赚得盆满钵满。在企业级市场,scale-up架构成就了IBM、SUN、HP、Oracle、SAP几大服务器巨头和企业软件巨头,计算机的世界就像武林一样在各大门派的控制下秩序井然,一片欣欣向荣。
但是,就像江湖总是暗流涌动,计算机的世界也不会一直按照“摩尔定律”线性发展,30多年稳步前进的计算机工业到了21世纪初,遇到了两个新的幽灵,老革命遇到新难题。
第一个幽灵是摩尔定律的失效,从21世纪开始,人们发现芯片的速度就开始减慢,新款产品的迭代时间开始变长,晶体管成本也不再下降。若按现在的速度继续发展,到21世纪20年代中期,晶体管的尺寸将仅有单个分子大小,晶体管也将变得非常不稳定,若没有新的技术突破,摩尔定律将会彻底终结。“最近的两次技术转换已经表明我们的更新周期(摩尔定律周期)从两年延长到了两年半。”从技术的角度看, 随着硅片上线路密度的增加,其复杂性和差错率也将呈指数增长,同时也使全面而彻底的芯片测试几乎成为不可能。一旦芯片上线条的宽度达到纳米(10-9米)数量级时,相当于只有几个分子的大小,这种情况下材料的物理、化学性能将发生质的变化,高温和漏电问题将会十分突出,致使采用现行工艺的半导体器件不能正常工作。
在几十年的PC大发展中,Intel建立了Tick-Tock芯片技术发展的战略模式,也被称为嘀嗒模式或者钟摆模式。每一个嘀嗒代表着2年一次的工艺制程进步。每个Tick-Tock中的“Tick”,代表着工艺的提升、晶体管变小,并在此基础上增强原有的微架构,而Tick-Tock中的“Tock”,则在维持相同工艺的前提下,进行微架构的革新,这样在制程工艺和核心架构的两条提升道路上,总是交替进行。Tick-Tock不仅仅是Intel的发展模式,企业级市场的芯片巨头如IBM、SUN也一样是采用这种模式。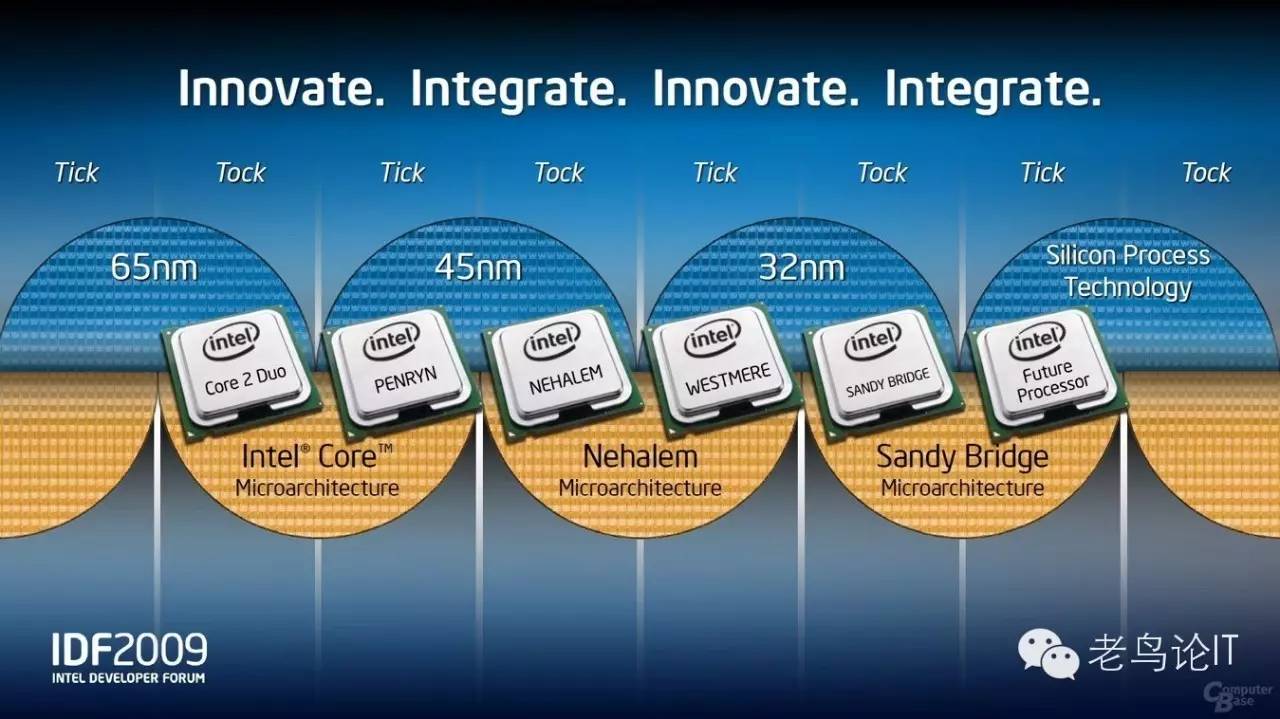
但是随和半导体工艺从65nm,45nm趋向于10nm,越来越逼近工艺和硅基芯片的物理极限,Tick-Tock的发展模式也面临终结。更快的计算速度就需要更快地CPU主频,自从几年前CPU的最高主频的桂冠由IBM Power6芯片摘下后,再也无人打破纪录。2002年1月摩尔在Intel开发者论坛上提出摩尔定律预计会在2017年终结, 一旦晶体管体积进入皮米级别, 晶体管将不得不接近原子大小, 我们很快将无法突破物理的基础限制. 事实上从2012年开始晶体管密度和主频速度的提高速度明显放慢.下图显示了在2012年出现了晶体管体积缩小速度的突然放缓。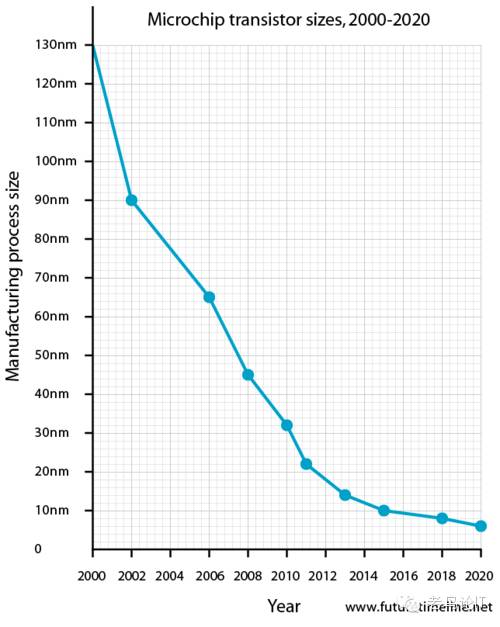
既然靠工艺和架构设计提高CPU单核的难度越来越大,另一种以前为大家所不屑的方法开始大行其道,那就是多核架构。单个CPU内封装的核心数量,从单核发展到到双核,4核,8核,15核,20核甚至32核。然而核心的增多是有代价的,多个CPU要沟通要协作,面临本地cache和远程cache访问延迟的巨大差异,操作系统和应用代码需要管理多核上的作业并行运行,要付出很多额外的工作机制和开销管理作业的并行性和一致性,所以更多的核往往并不会带来应用更快地执行。从应用代码执行的的角度来看,一个多核的单机和多个单核的机器并无本质不同。这也就是为何Apple的A9 CPU采用双核架构,其性能却可以秒杀高通/华为/MTK的8核甚至10核CPU的原因。
最早在PC市场CPU芯片上转向多核路线的是AMD,起初Intel对此也是嗤之以鼻的,后来发现这是一条“多快好省”的发展道路,Intel也义无反顾地扛起了多核的大旗。在企业级市场,SUN/Oracle是能力不行靠数量补的典型,其最新的M7 CPU已经堆砌到亮闪闪的32核心,比较矜持的如老牌公司蓝色巨人IBM,至今仍然苦苦坚持单核性能核和核心数量的均衡,其最新Power8仍然以8~12核心为主,却要提供不输更多核CPU的性能。
第二个幽灵是互联网的崛起。经历过2000年的第一波互联网泡沫,真正的互联网时代和移动互联网时代终于到来了。随着第一代互联网先驱Yahoo等门户网站的暗淡,以google,baidu,facebook和taobao为代表的互联网巨头成长起来,搜索引擎和社交网络面对史无前例的用户数和业务并发量,并且每年50%以上的快速增长速度,对原有的计算机系统处理能力带来了空前的挑战。原有的scale-up的系统架构无法适应互联网业务的快速增长对扩展性的需求,逼迫互联网新贵们探索更容易扩展的系统架构。互联网新贵们虽然白手起家从头创业,但是汇聚了大量的系统架构和技术研发高手,他们吸取过去几十年系统架构发展的经验,结合自身的业务需求,为自己量身定做了一套新的系统架构。一个以google为代表,为了解决全球数以万计网站页面的存储、排序和检索问题,发展了一套面向海量数据分析的系统架构,后来业界以这套的技术理论为基础,开发出了Hadoop,这就是大名鼎鼎的大数据技术的发端;另一个以Alibaba为代表,为了解决海量并发交易业务的支撑难题,发展了一套以分布式中间件加数据库的大并发交易系统,这就是Alibaba逢人必讲的“去IOE”架构。不论是google还是Alibaba的系统,其最核心的特点就是分布式scale-out架构,这套架构在google和Alibaba的成功,使得过去几十年偏安于HPC等特殊领域的分布式架构重新引起业界的注意,一时间人人效仿,分布式、轻量级、SOA化,大数据…等关键字成了流行词汇。
然而,分布式架构几十年前就产生了,为什么知道最近几年才开始在企业系统领域等到重视和流行,难点在那里?技术还是业务?scale-out架构能够在传统企业领域全面取代scale-up么?未来系统架构的发展走势是怎样的?笔者会在后续的文章中试着为各位一一解答。
今天笔者先谈一个简单的问题——分布式带来的好处到底有多大?换言之,是不是分得越多越好,性能增长的极限到底在哪里?如果我们只用廉价的机器,使用威力巨大的分布式架构,是不是可以实现任何我们想达到的性能目标?

要分析这个问题,我们得搞清楚分布式到底是怎么实现的,一个集中式的应用逻辑,变成分布式并发执行的过程是怎样的。这里笔者想起另外一个同样有趣的话题,把大象装进冰箱分成几步。第一步:把冰箱打开第二步:把大象塞进去第三步:把冰箱关上。
同样,把一段应用作业转换成分布式执行也需要三步:第一步,切分作业;第二步,分发作业并行执行;第三步,合并结果,返回完成。看似非常简单,但是做起来则学问很大。
第一步,切分作业。首先你的作业必须是可以切分成多个可以并行的子作业。比如,一个作业如果是对一篇100页的文章进行统计,可以切分成100个作业,每个作业统计其中的1页。但是如果作业是更加复杂的情况呢?比如100个窗口的业务办理请求。如果任何两个业务请求都是互相独立没有关联关系的,是可以很容易地切分成100个子作业并发处理业务请求。但是实际业务中可能会出现稍微复杂的情况,例如某两个以上的请求需要访问某一个共同的数据。比如挂号,每个医生每天只能挂一定数量的号,因此任何窗口进来的对某个医生的挂号请求都必须串行执行,以防止超过超额挂号。还有更加复杂的情况,比如订火车票,由于车票是按照区段销售的,任何两张票只要在区段线路上存在交叉,则都存在资源争抢,这种情况下需要集中管理每个区段的资源数量,对涉及到争抢的所有相关车票串行执行。然而,这还不是最复杂的,还有一种情况,不同的业务请求之间不仅存在资源争抢,还存在因果依赖,也就是某些请求是另外一些请求的前提,比如一笔合约规定A转账给B,然后B再转账给C,还比如付款和发货,这些业务都必须前一步成功了后一步才能执行,后一步如果失败了,前一步必须回滚。如果搞不清楚作业之间的资源争抢关系和因果依赖关系,贸然进行切分,还可能会造成资源互相等待,也就是死锁,不尽提高不了性能,反而会造成性能的急剧下降,如下图这种情况。
即使前面这个困难都解决了,切分的粒度和维度也是问题,综合考虑实际执行情况,以及子作业的资源争抢和依赖性,切分成多少个并发作业综合效果最优?假如后端执行阶段数量变化了,如何动态地改变切分粒度?采用哪个维度切分会更加平均更适合业务逻辑,姓名?手机号?订单编号还是商品编号,是采用按关键字区间切分还是hash算法,这些都对切分的效果有着莫大的影响。
第二步,分发作业并行执行。假设后端有100个节点,是平均地将子作业分发到所有节点执行么?即使后端所有节点配置相同,执行作业仍然会有快有慢,如何根据作业的表现动态调整作业分发策略以实现所有节点同时执行完成?如果出现长尾作业如何处理,如果某个节点的作业执行失败怎么办?是重新调度执行还是整体回滚?如果重新调度执行,如何保存和恢复原来执行的断点状态?如果后端增加或减少了节点数,如何动态地调整分发策略,使得所有节点仍然可以均衡执行?如何避免执行过程中出现的作业不均衡和数据倾斜?

第三步,合并结果,返回完成。第三步直接对结果负责,所以是确保业务正确性的最后一关。在这一步需要搜集所有子作业执行的结果并进行检查,确保所有子作业结果符合预定目标,然后对结果进行合并,返回给前端业务请求方。然而实际情况是,不可能所有的子作业都完全按照预期的结果和时间返回,这时为了总体的性能,如果在满足总体对业务安全性和一致性要求的前提下更快地返回结果?如果有子作业需要重新执行和回滚,如何告知分发和调度程序?返回结果之后如何将结果持久化保存?性能和安全如何平衡,这些同样是需要重点考虑的问题。

搞清楚了应用分布化的过程,我们就来研究一个各位比较关心的问题:到底用分布式架构+比较差的服务器,能不能获得比集中式架构+比较好的比较好的服务器的运行效能呢?
为了让大家更清楚的明白这个过程,我画图示意出来,见下图。图里有一个作业,可以分成12个子作业,我们比较两种情况的运行效果。一个是用一个4Ghz CPU单机来串行地执行,另一个是用4台750MHz CPU的机器并行地执行。为了简化,我们简单的假定12个子作业之间不存在资源争用,也不存在依赖关系。我们比较两边作业的执行时间,你会发现并行后不一定更快,为什么呢?
假设每个子作业在4Ghz CPU上执行需要1ms,总共串行执行下来约需要1×12=12ms。同样,每个子作业在750MHzCPU上执行时间为4ms,假设所有4个节点运行时间完全一致,则总的执行时间为:
Mater节点任务分解和汇总的时间+各节点通信的时间+子任务启动和停止的系统时间+子作业执行时间(4ms×3=12ms )
这个总的执行时间肯定是远超过单机运行的时间的。
所以,即使在这种理想情况下,不考虑真实环境子作业执行时间无法完全均衡造成长尾作业的等待延时,用5台服务器并行处理,是无法获得比单台服务器4倍的运行性能的。
如果再比较分布式架构的成本,我们很容易发现分布式架构要比集中式架构至少多出以下额外的cost:
更多的节点,意味着更多的附属不可压缩成本(如线缆、磁盘、端口、空间等的成本);
更多的节点和OS,意味着更多的运维工作量和成本;
更多的节点和OS,意味着更多的系统开销(OS系统常驻内存、系统进程);
更多的节点,意味着更难的资源均衡和更低的平均资源利用率;
更多的节点,意味着更多的数据倾斜、作业执行不均衡和更高的子任务长尾概率;
另外,还需要考虑应用并行化之后需要更多的软件开发、测试和优化成本。
经过上面的分析,我们很容易得出结论,分布式架构并不是万能的,如果单个CPU的性能太差,做分布式还不如用更强大的CPU做集中式架构划算。那么到底CPU的差距减小到多大的时候用分布式就会获得更好的效能了呢,我们可以参考google的研究结果。早在2009年,Google 负责工程的高级副总裁UrsHölzle在《The Datacenter as a Computer: An Introduction to the Design ofWarehouse-Scale Machines》一书中指出,即便是分布式架构,也是单个CPU(核)的能力越强越好——Scale-out(横向扩展)不代表单点的Scale不需要up(纵向扩展)。他甚至还把这一小节单独摘出来,以“Brawny cores still beat wimpy cores, most of the time”(绝大多数时候,强核就是比弱核好)为标题在2010年的IEEE Micro杂志上发表了一页半的文章。这篇文章的核心观点就是性能较弱但是功耗较低的“小号”处理器只有在它们的单核性能接近中档的“大号”处理器时才具有足够的竞争力,否则它们羸弱的单核性能会成为Google现有应用中的性能瓶颈。
接下来,我们试着回答第二个问题,即使不考虑硬件的处理能力的差异和成本,采用分布式架构将一个作业进行并行计算,性能会随着并行数量的增加线性增长么?性能增长的极限在哪里?
这个问题,实际上早在1967年就有了答案,这就是著名的Amdahl's Law。Amdahl曾致力于并行处理系统的研究。对于固定负载情况下描述并行处理效果的加速比s,阿姆达尔经过深入研究给出了如下公式:
S=1/(a+(1-a)/n)
其中,a为串行计算部分所占比例,n为并行处理结点个数。这样,当a=0时,最大加速比s=n;若a=1,则最小加速比。s=1。当n→∞时,极限加速比s→ 1/a,这也就是加速比的上限。例如,若串行代码占整个代码的25%,则并行处理的总体性能不可能超过4。这一公式已被学术界所接受,并被称做“阿姆达尔定律”(Amdahl's Law)。
下图是阿姆达尔定律并行曲线。
横轴表示并行节点个数(CPU数量),纵轴表示并行后性能加速比,从图中可以看到,即使应用95%的部分都可以并行,在理想情况下128个节点之后并行加速的增益也区域平缓,增加更多的并行节点对提高性能不再有实际意义。
OK,到这里,本系列的第一回写完了,为了吸引大家的兴趣和铺垫,前面花了不少的篇幅讲述历史。分布式系统架构是个庞大的话题,笔者的文章只是试图帮助读者鸟瞰式地了解一些基本概念和热点问题。本回作为序章,后面会展开论述一些更加具体的问题,欢迎各位届时收看。
因为时间仓促,行文如有不周全之处,欢迎指正。本文所引用图片部分来源于网络,版权归原作者所有。
后续章节预告:
第二回美丽的Hash环
第三回一致性的魔咒“CAP”
第四回皇冠上的明珠“分布式事物”
第五回终极奥义“拜占庭算法”
第六回民主还是专制?从计算机系统到社会形态
以上是关于分布式架构的那些事儿之一:1+1=2么?的主要内容,如果未能解决你的问题,请参考以下文章