flink二三事:起家的技术
Posted 大数据和云计算技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink二三事:起家的技术相关的知识,希望对你有一定的参考价值。
上一篇聊到flink的历史,请看上篇《》。
可以说基本上是起了个大早,赶了个晚集,但是flink能做今天这种热度,没有被spark干死也是不容易。原来大家都在想办法突破MapReduce太慢的问题时候,除了spark,比如还有Tez等框架基本上销声匿迹了。14年flink在apache孵化能活下来并成为顶级项目的关键还是flink的有些自己的创新技术。
Spark的核心概念是RDD,抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。(不是指最新版本的structure streaming,讲的是历史。)
图1 RDD概念示意
spark相比M/R计算模型差不多,关键是把数据放到内存中迭代。天生的batch模型,对于流处理,最早思路是通过减少batch粒度,也就是mini batch来支持,但同时也限制spark streaming能支撑的时延只能到到秒级,而flink通过增量迭代的能力,支持一次一条数据的处理,处理时延迟可以做到毫秒。最新的structure streaming号称也可以支持毫秒级处理了。下面三个图,对比下几种计算模型的区别:
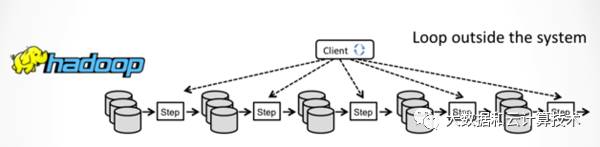
图2 M/R计算模型
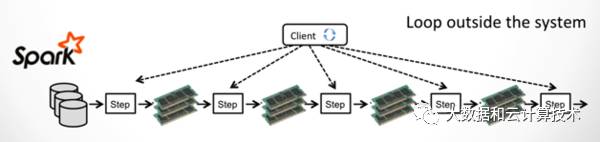
图3 Spark计算模型
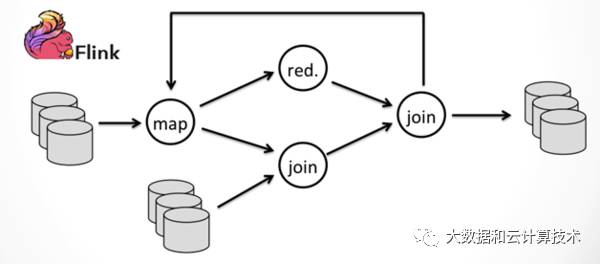
图4 Flink计算模型
除了steaming模型有很大区别之外,flink当时比较能拿得出手的就是内存管理了。下面简单讲讲flink的内存管理,基本思路就是放弃了jvm的内存管理,自己单独干。
flink/spark都用JVM。基于 JVM 的数据分析引擎都需要面对将大量数据存到内存中,这就不得不面对 JVM 存在的几个问题:
Java 对象存储密度低。一个只包含boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法。你可以把 MemorySegment 想象成是为 Flink 定制的java.nio.ByteBuffer。它的底层可以是一个普通的 Java 字节数组(byte[]),也可以是一个申请在堆外的 ByteBuffer。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
Flink 中的 Worker 名叫 TaskManager,是用来运行用户代码的 JVM 进程。TaskManager 的堆内存主要被分成了三个部分:
图5 flink内存分配
Network Buffers: 一定数量的32KB大小的buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过 taskmanager.network.numberOfBuffers 来配置。
Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合。Flink中的算法(如sort/shuffle/join)会向这个内存池申请MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。
Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
Flink 采用类似 DBMS 的 sort 和 join 算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。所以 Flink 的内部实现更像 C/C++ 而非 Java。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。如果要操作多块MemorySegment就像操作一块大的连续内存一样,Flink会使用逻辑视图(AbstractPagedInputView)来方便操作。
从上面我们能够得出 Flink 积极的内存管理以及直接操作二进制数据有以下几点好处:
减少GC压力。显而易见,因为所有常驻型数据都以二进制的形式存在Flink 的MemoryManager中,这些MemorySegment一直呆在老年代而不会被GC回收。其他的数据对象基本上是由用户代码生成的短生命周期对象,这部分对象可以被 Minor GC 快速回收。只要用户不去创建大量类似缓存的常驻型对象,那么老年代的大小是不会变的,Major GC也就永远不会发生。从而有效地降低了垃圾回收的压力。另外,这里的内存块还可以是堆外内存,这可以使得 JVM内存更小,从而加速垃圾回收。
避免了OOM。所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。在内存吃紧的情况下,算法(sort/join等)会高效地将一大批内存块写到磁盘,之后再读回来。因此,OutOfMemoryErrors可以有效地被避免。
节省内存空间。Java对象在存储上有很多额外的消耗(如上一节所谈)。如果只存储实际数据的二进制内容,就可以避免这部分消耗。
高效的二进制操作& 缓存友好的计算。二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对高速缓存更友好,可以从 L1/L2/L3 缓存获得性能的提升。
flink的这些技术,当年给spark造成了一定的压力,好在spark反应快,立刻放了一个Tungsten的大招来优化性能。
Tungsten项目将是Spark自诞生以来内核级别的最大改动,以大幅度提升Spark应用程序的内存和CPU利用率为目标,旨在最大程度上压榨新时代硬件性能。Project Tungsten包括了3个方面的努力:
Memory Management和BinaryProcessing:利用应用的语义(application semantics)来更明确地管理内存,同时消除JVM对象模型和垃圾回收开销。
Cache-aware computation(缓存友好的计算):使用算法和数据结构来实现内存分级结构(memoryhierarchy)。
代码生成(Codegeneration):使用代码生成来利用新型编译器和CPU。
第一条内存管理明显是有针对性的意味,不过tungsten的code generation也很有意思,根据databricks自己的总结,对于TPC-DS的查询,带来接近一个量级的性能的提升。
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
关于flink内存管理就简单聊到这,同学会问,怎么还没有到flink watermark?不急,慢慢来。:)
以上是关于flink二三事:起家的技术的主要内容,如果未能解决你的问题,请参考以下文章