大数据分析引擎Apache Flink: What, How, Why, Who, Where?
Posted 大数据DT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据分析引擎Apache Flink: What, How, Why, Who, Where?相关的知识,希望对你有一定的参考价值。
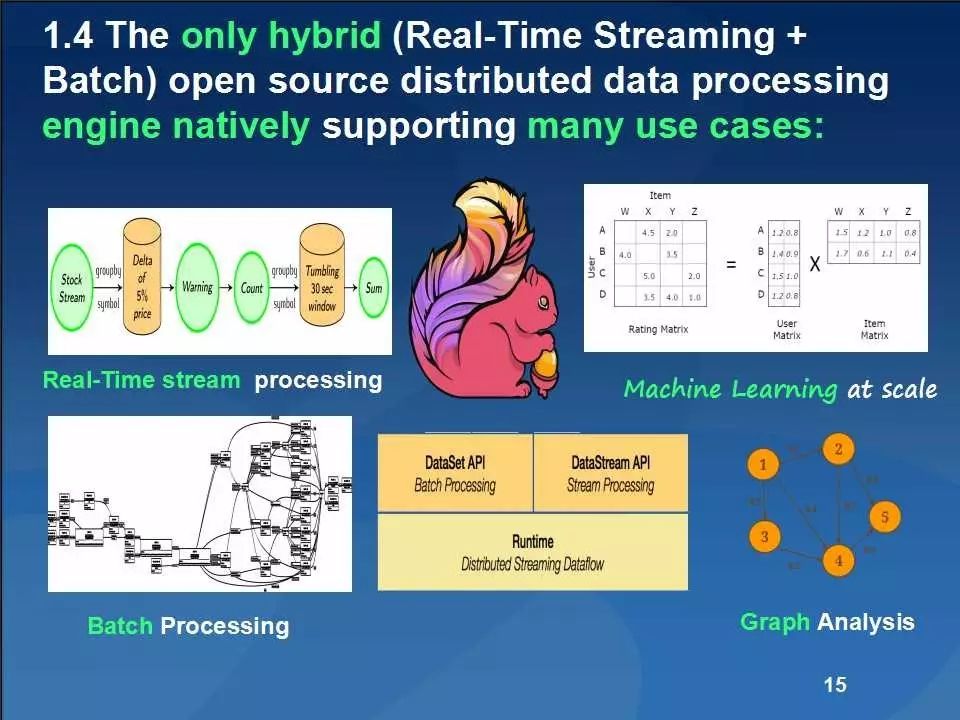
Apache Flink是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
从Flink官网得知,其具有如下主要特征:
1. 快速
Flink利用基于内存的数据流并将迭代处理算法深度集成到了系统的运行时中,这就使得系统能够以极快的速度来处理数据密集型和迭代任务。
2. 可靠性和扩展性
当服务器内存被耗尽时,Flink也能够很好的运行,这是因为Flink包含自己的内存管理组件、序列化框架和类型推理引擎。
3. 表现力
利用Java或者Scala语言能够编写出漂亮、类型安全和可为核心的代码,并能够在集群上运行所写程序。开发者可以在无需额外处理就使用Java和Scala数据类型
4. 易用性
在无需进行任何配置的情况下,Flink内置的优化器就能够以最高效的方式在各种环境中执行程序。此外,Flink只需要三个命令就可以运行在Hadoop的新MapReduce框架Yarn上,
5. 完全兼容Hadoop
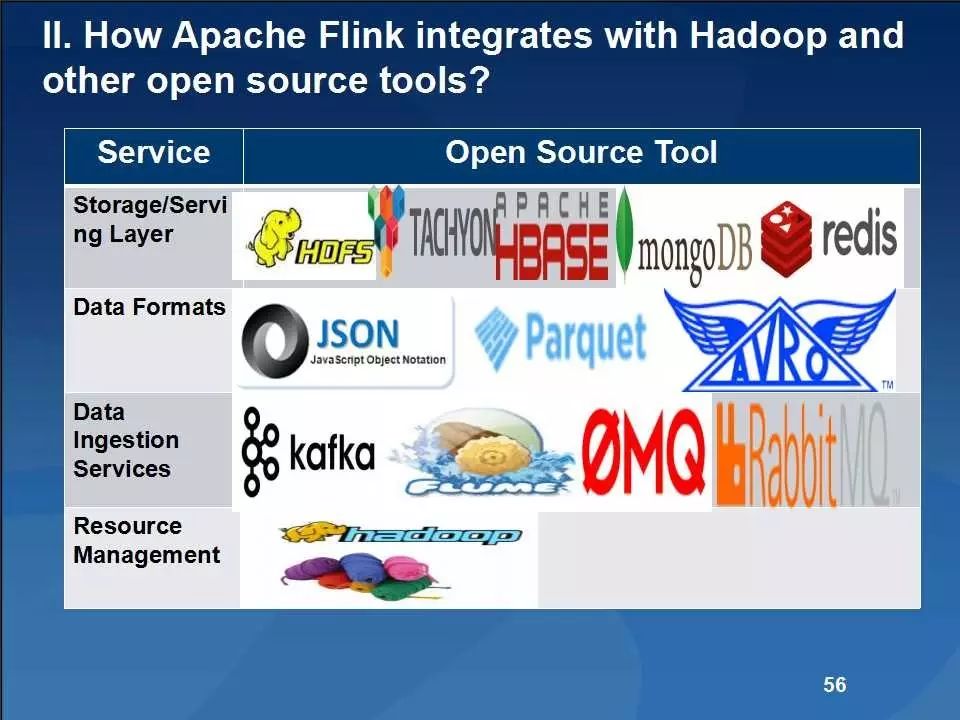
Flink支持所有的Hadoop所有的输入/输出格式和数据类型,这就使得开发者无需做任何修改就能够利用Flink运行历史遗留的MapReduce操作
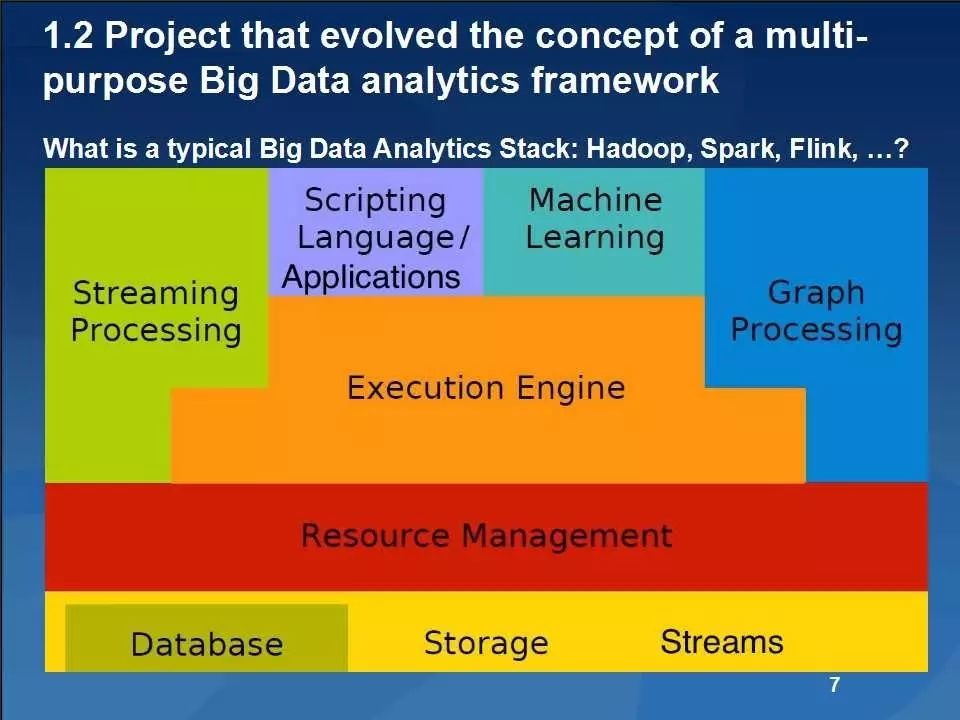
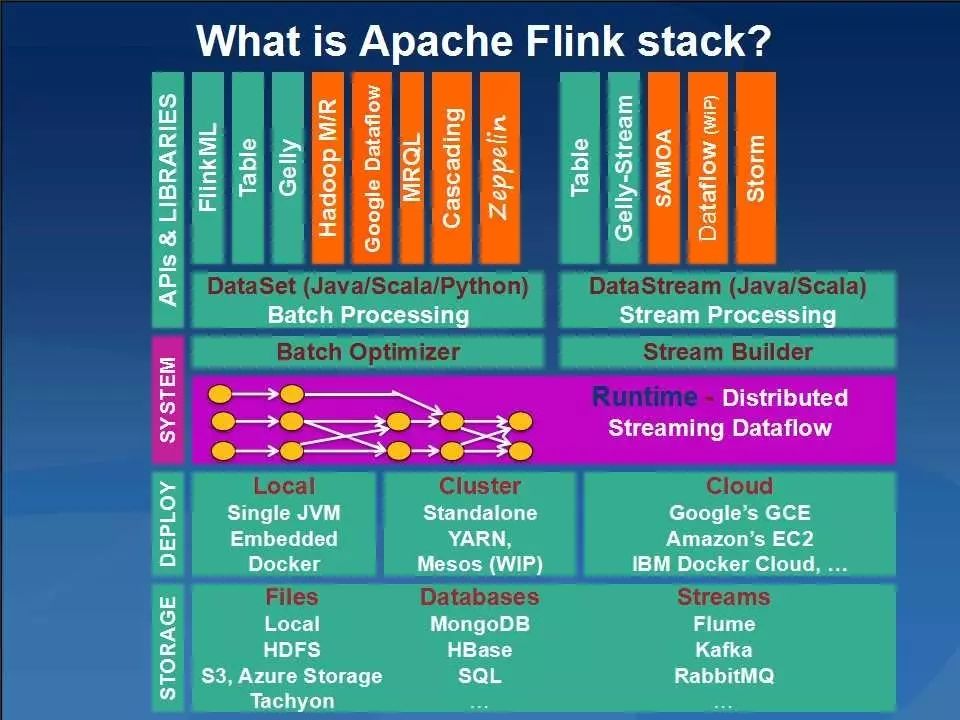
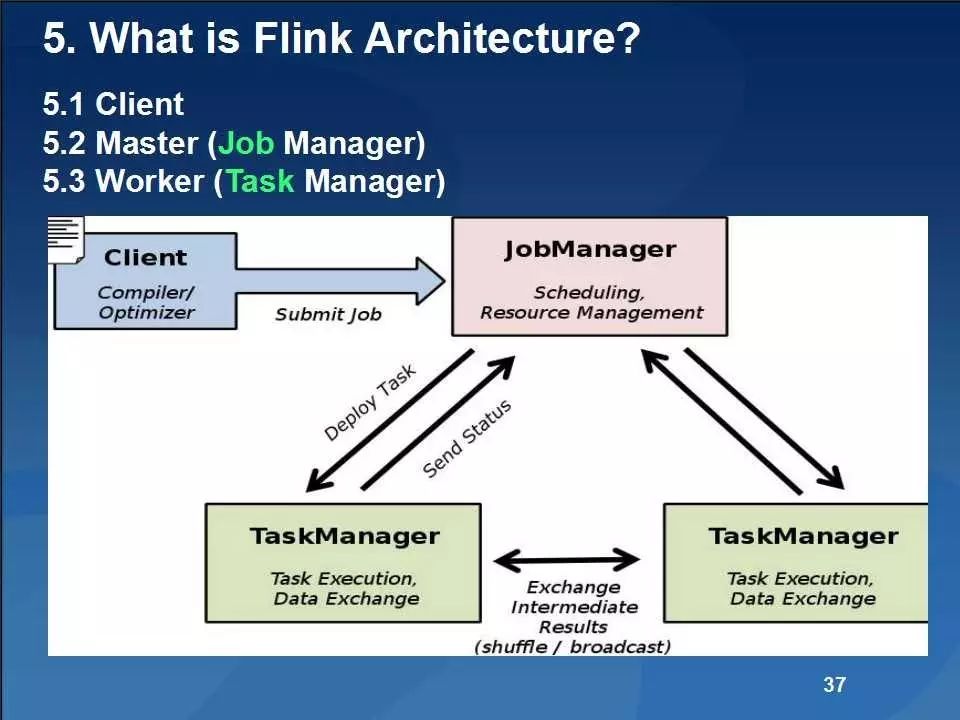
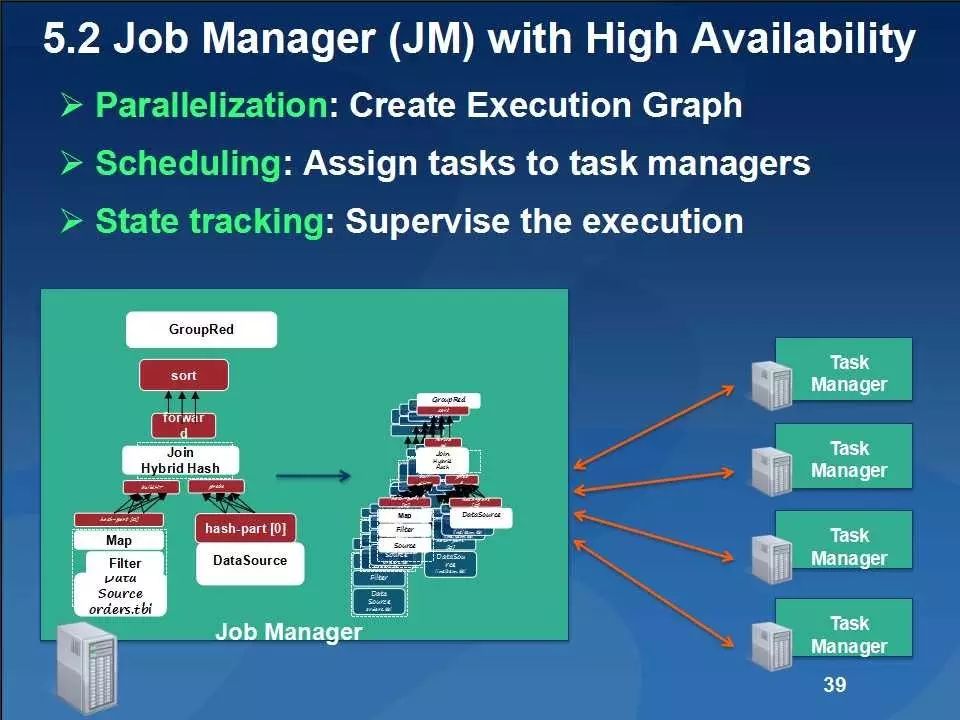
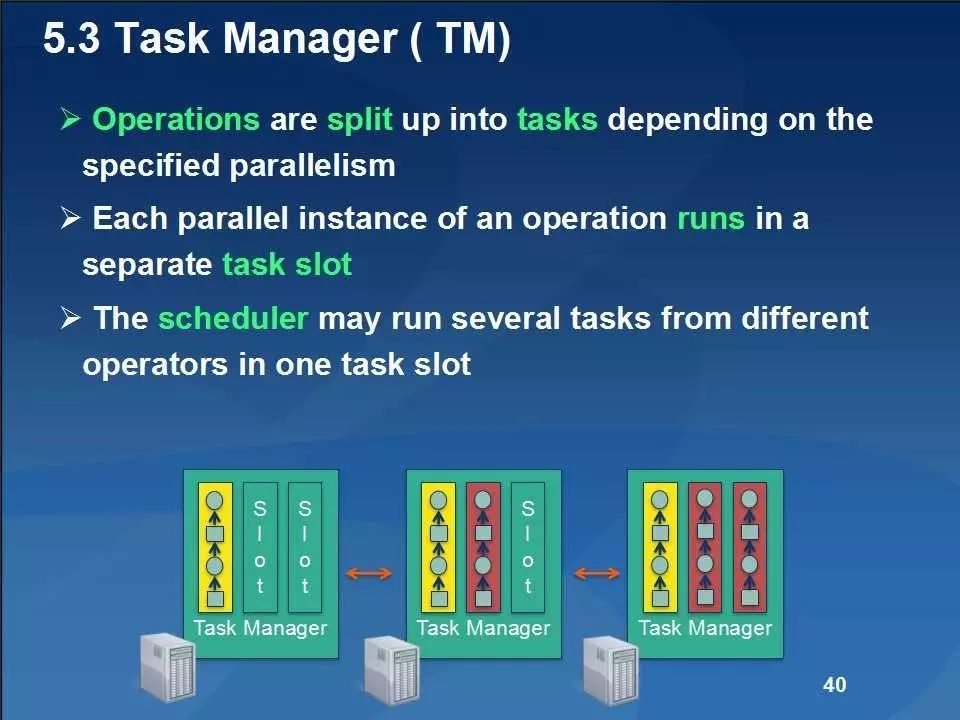
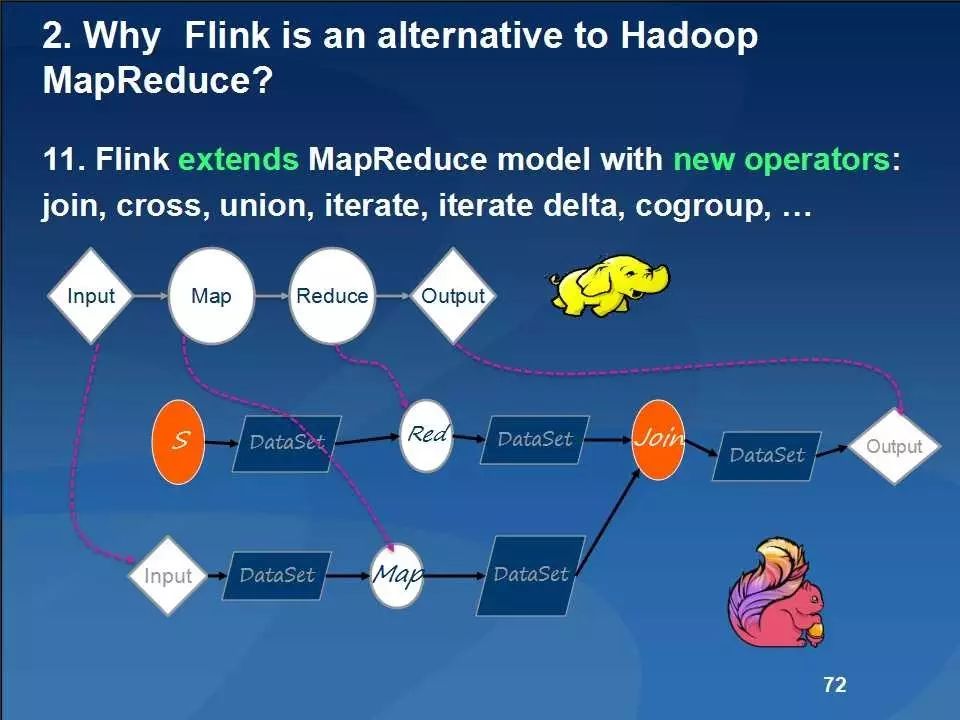
Flink主要包括基于Java和Scala的用于批量和基于流数据分析的API、优化器和具有自定义内存管理功能的分布式运行时等,其主要架构如下
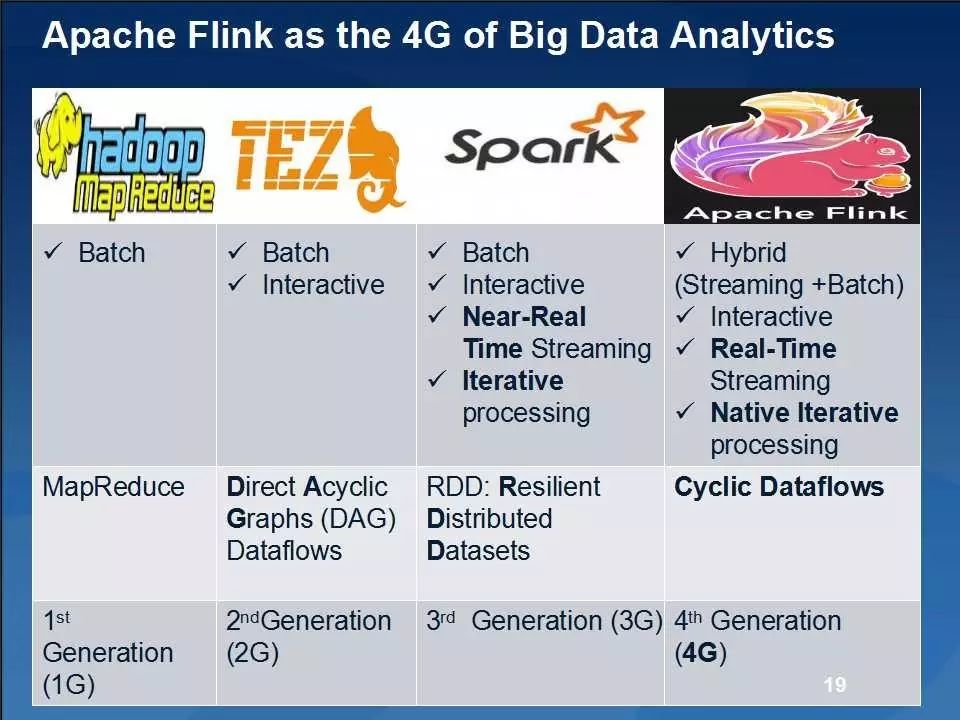
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处,但它们也有着巨大的差异。近日,MapR Technologies产品经理Balaji Mohanam在公司内部的白板演示中比较了Apache Spark和Apache Flink的不同之处,用户可以参考这种比较做出选择。
为了方便说明,Mohanam首先对批处理、微批处理和连续流操作符等三种计算模式进行了解释。批处理基本上处理静态数据,一次读入大量数据进行处理并生成输出。微批处理结合了批处理和连续流操作符,将输入分成多个微批次进行处理。从根本上讲,微批处理是一个“收集然后处理”的计算模型。连续流操作符则在数据到达时进行处理,没有任何数据收集或处理延迟。
Apache Spark和Apache Flink的主要差别就在于计算模型不同。Spark采用了微批处理模型,而Flink采用了基于操作符的连续流模型。因此,对Apache Spark和Apache Flink的选择实际上变成了计算模型的选择,而这种选择需要在延迟、吞吐量和可靠性等多个方面进行权衡。
随着数据处理能力的提高,企业开始认识到,信息的价值在数据产生的时候最高。他们希望在数据产生时处理数据,这就是说需要一个实时处理系统。但也不是所有情况都需要实时系统。Mohanam分别例举了一些适合微批处理或实时流处理的场景。
点击“阅读原文”,查看完整版PPT。此部分资料来源于Youtube。






















大数据杂谈
ID:BigdataTina2016
▲长按二维码识别关注
专注大数据和机器学习,
分享前沿技术,交流深度思考。
欢迎加入社区!
以上是关于大数据分析引擎Apache Flink: What, How, Why, Who, Where?的主要内容,如果未能解决你的问题,请参考以下文章
征服阿里,大数据计算引擎Apache Flink靠的是什么?