浅析 Flink Table/SQL API
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析 Flink Table/SQL API相关的知识,希望对你有一定的参考价值。
本文转载自:http://mtunique.com/flink_sql/
从何而来
关系型API有很多好处:是声明式的,用户只需要告诉需要什么,系统决定如何计算;用户不必特地实现;更方便优化,可以执行得更高效。本身Flink就是一个统一批和流的分布式计算平台,所以社区设计关系型API的目的之一是可以让关系型API作为统一的一层,两种查询拥有同样的语义和语法。大多数流处理框架的API都是比较low-level的API,学习成本高而且很多逻辑需要写到UDF中,所以Apache Flink 添加了SQL-like的API处理关系型数据–Table API。这套API中最重要的概念是Table(可以在上面进行关系型操作的结构化的DataSet或DataStream)。Table API 与 DataSet和DataStream API 结合紧密,DataSet 和 DataStream都可以很容易地转换成 Table,同样转换回来也很方便:
example使用的是Scala的API,Java版API也有同样的功能。
下图展示了 Table API 的架构:
从 DataSet 或 DataStream 创建一个 Table,然后在上面进行关系型操作比如 fliter、join、select。对Table的操作将会转换成逻辑运算符树。Table 转换回 DataSet 和 DataStream 的时候将会转换成DataSet 和 DataStream的算子。有些类似 'location.like("room%") 的表达式将会通过 code generation 编译成Flink的函数。
然而,最初传统的Table API 有一定的限制。首先,它不能独立使用。Table API 的 query 必须嵌入到 DataSet 或 DataStream的程序中。对批处理表的查询不支持outer join,sorting和很多SQL中常见的标量函数。对于流处理的查询只支持filtetr union 和 projection,不支持aggregation和join。而且,转换过程中没有利用太多查询优化技术,除了适用于所有DataSet程序的优化。
Table API 和 SQL 紧密结合
随着流处理的日益普及和Flink在该领域的增长,Flink社区认为需要一个更简单的API使更多的用户能够分析流数据。一年前Flink社区决定将Table API提升到一个新的层级,扩展Table API中流处理的能力以及支持SQL。社区不想重复造轮子,于是决定在 (一个比较流行的SQL解析和优化框架)的基础上构建新的 Table API。Apache Calcite 被用在很多项目中,包括 Apache Hive,Apache Drill,Cascading等等。除此之外,Calcite社区将 写入它的roadmap,所以Flink的SQL很适合和它结合。
以Calcite为核心的新架构图:
新架构提供两种API进行关系型查询,Table API 和 SQL。这两种API的查询都会用包含注册过的Table的catalog进行验证,然后转换成统一Calcite的logical plan。在这种表示中,stream和batch的查询看起来完全一样。下一步,利用 Calcite的 cost-based 优化器优化转换规则和logical plan。根据数据源的性质(流式和静态)使用不同的规则进行优化。最终优化后的plan转传成常规的Flink DataSet 或 DataStream 程序。这步还涉及code generation(将关系表达式转换成Flink函数)。
下面我们举一个例子来理解新的架构。表达式转换成Logical Plan如下图所示:
调用Table API 实际上是创建了很多 Table API 的 LogicalNode,创建的过程中对会对整个query进行validate。比如table是CalalogNode,window groupBy之后在select时会创建WindowAggregate和Project,where对应Filter。然后用RelBuilder翻译成Calcite LogicalPlan。如果是SQL API 将直接用Calcite的Parser进行解释然后validate生成Calcite LogicalPlan。
利用Calcite内置的一些rule来优化LogicalPlan,也可以自己添加或者覆盖这些rule。转换成Optimized Calcite Plan后,仍然是Calcite的内部表示方式,现在需要transform成DataStream Plan,对应上图第三列的类,里面封装了如何translate成普通的DataStream或DataSet程序。随后调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。现在就相当于我们直接利用Flink的DataSet或DataStream API开发的程序。
Table API的新架构除了维持最初的原理还改进了很多。为流式数据和静态数据的关系查询保留统一的接口,而且利用了Calcite的查询优化框架和SQL parser。该设计是基于Flink已构建好的API构建的,DataStream API 提供低延时高吞吐的流处理能力而且就有exactly-once语义而且可以基于event-time进行处理。而且DataSet拥有稳定高效的内存算子和流水线式的数据交换。Flink的core API和引擎的所有改进都会自动应用到Table API和SQL上。
新的SQL接口集成到了Table API中。DataSteam, DataSet和外部数据源可以在TableEnvironment中注册成表,为了是他们可以通过SQL进行查询。TableEnvironment.sql()方法用来声明SQL和将结果作为Table返回。下面的是一个完整的样例,从一个JSON编码的Kafka topic中读取流表,然后用SQL处理并写到另一个Kafka topic。
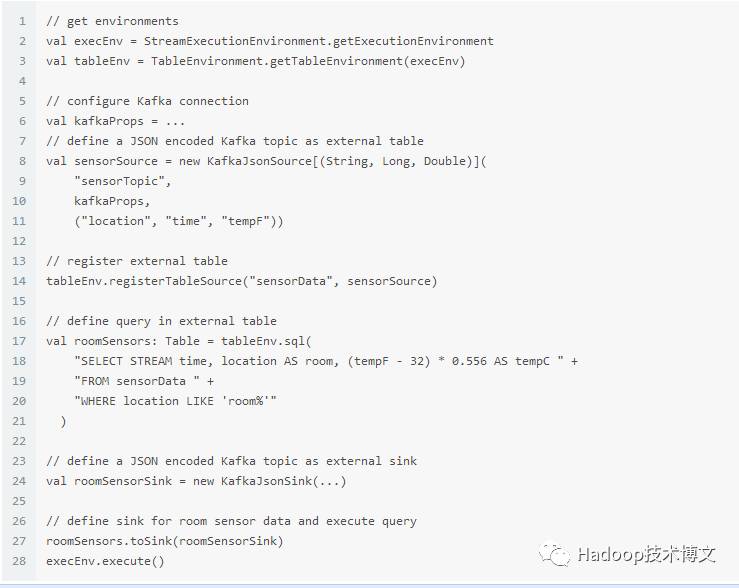
这个样例中忽略了流处理中最有趣的部分:window aggregate 和 join。这些操作如何用SQL表达呢?Apache Calcite社区提出了一个proposal来讨论的语法和语义。社区将Calcite的stream SQL描述为标准SQL的扩展而不是另外的 SQL-like语言。这有很多好处,首先,熟悉SQL标准的人能够在不学习新语法的情况下分析流数据。静态表和流表的查询几乎相同,可以轻松地移植。此外,可以同时在静态表和流表上进行查询,这和flink的愿景是一样的,将批处理看做特殊的流处理(批看作是有限的流)。最后,使用标准SQL进行流处理意味着有很多成熟的工具支持。
下面的example展示了如何用SQL和Table API进行滑动窗口查询:
SQL
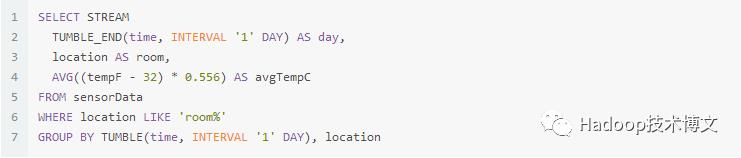
Table API
Table API的现状
Batch SQL & Table API 支持:
Selection, Projection, Sort, Inner & Outer Joins, Set operations
Windows for Slide, Tumble, Session
Streaming Table API 支持:
Selection, Projection, Union
Windows for Slide, Tumble, Session
Streaming SQL:
Selection, Projection, Union, Tumble
Streaming SQL案例
持续的ETL和数据导入
获取流式数据,然后转换这些数据(归一化,聚合…),将其写入其他系统(File,Kafka,DBMS)。这些query的结果通常会存储到log-style的系统。
实时的Dashboards 和 报表
获取流式数据,然后对数据进行聚合来支持在线系统(dashboard,推荐)或者数据分析系统(Tableau)。通常结果被写到k-v存储中(Cassandra,Hbase,可查询的Flink状态),建立索引(Elasticsearch)或者DBMS(mysql,PostgreSQL…)。这些查询通常可以被更新,改进。
即席分析
针对流数据的即席查询,以实时的方式进行分析和浏览数据。查询结果直接显示在notebook(Apache Zeppelin)中。
0、回复 spark_2017_all 获取 Spark Summit East 2017高清视频和PPT
1、回复 hive_es 获取 《基于 Hive/ES 金融大数据指标系统》PPT
2、回复 bigdata_e 获取 《大规模数据处理演变》PPT
3、回复 大数据分析 获取 《Big Data Analytics》电子书
4、回复 spark2电子书 获取 《Apache Spark 2 for Beginners》电子书
5、回复 spark2_data 获取 《Spark for Data Science》电子书
6、回复 架构师大会ppt 获取 《2016年中国架构师[大数据场]》 PPT
7、回复 intro_flink 获取 《Introduction to Apache Flink》 电子书
8、回复 learning_flink 获取《Learning Apache Flink》电子书
8、回复 Hadoop权威指南 获取 《Hadoop权威指南中文第三版》电子书
9、回复 flink未来 获取 《The Future of Apache Flink》
10、回复 Learning_PySpark 获取《Learning PySpark》电子书
以上是关于浅析 Flink Table/SQL API的主要内容,如果未能解决你的问题,请参考以下文章
Flink扩展 Table/SQL Scalar 函数实现文档
Flink扩展 Table/SQL Scalar 函数的实现
flink1.11报错:java.lang.IllegalStateException: No ExecutorFactory found to execute the application(代码片