Spark的竞争者——Flink浅析
Posted 畅游DT时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark的竞争者——Flink浅析相关的知识,希望对你有一定的参考价值。
简介
Apache Flink是一个开源的流式分布式处理框架,具有高效性与高可用性。其分布式处理引擎能够处理流式数据和批数据,Flink主要的应用场景是对流式数据的处理。Flink基于流式第一原则,将批数据看做是流式数据的一个特殊情况进行处理。换句话说,Flink将所有任务都视为流式数据任务。与Spark Streaming将流数据分隔成微批数据进行处理不同,Flink是真正的流式处理引擎,并且同样能够支持批处理操作。
架构
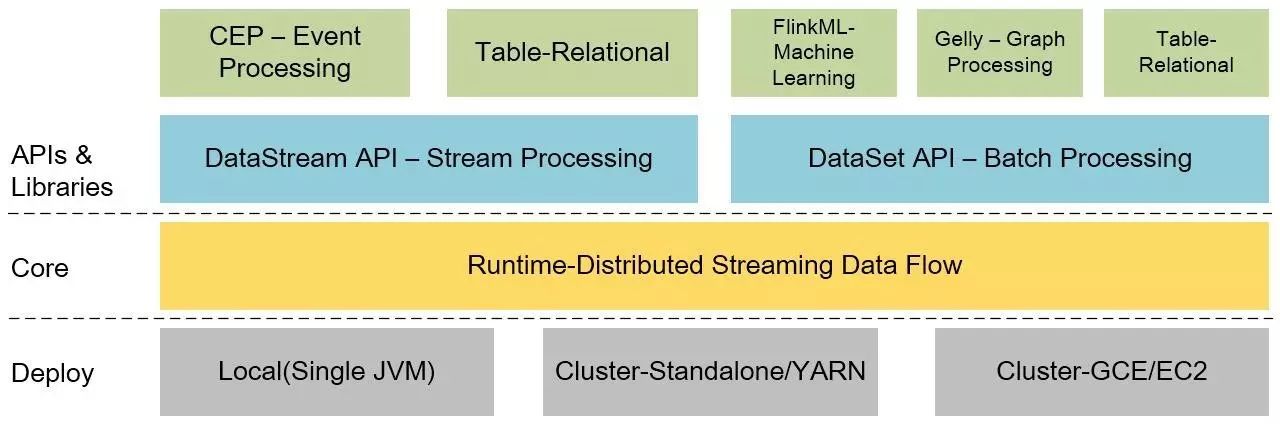
Apache Flink系统架构
Flink具有分层的架构,其中的每个组件都是某一层的特定组成部分,每层之间有所依赖。Flink可以在本地机器、Yarn集群或者在云上运行。Runtime是Flink的核心数据处理引擎,通过API接口以JobGraph的形式接受程序的提交。JobGraph是一个简单的并行数据流,由一组生成和使用数据流的任务组成。程序员可以通过DataStream和DataSet这两类API接口来定义具体Job。当程序被编译时,JobGraph由这些API定义生成,其中DataSet API使用优化器生成最佳执行计划,DataStream API使用流构建器来制定高效的执行计划。优化的JobGraph将根据具体的部署模式提交给执行器进行执行。
分布式执行
Flink的分布式执行包括两个重要进程,master与worker。当一个Flink程序执行时,各种进程参与到执行的过程中,包括Job Manager,Task Manager和Job Client。下图展示了具体的Flink程序执行过程。
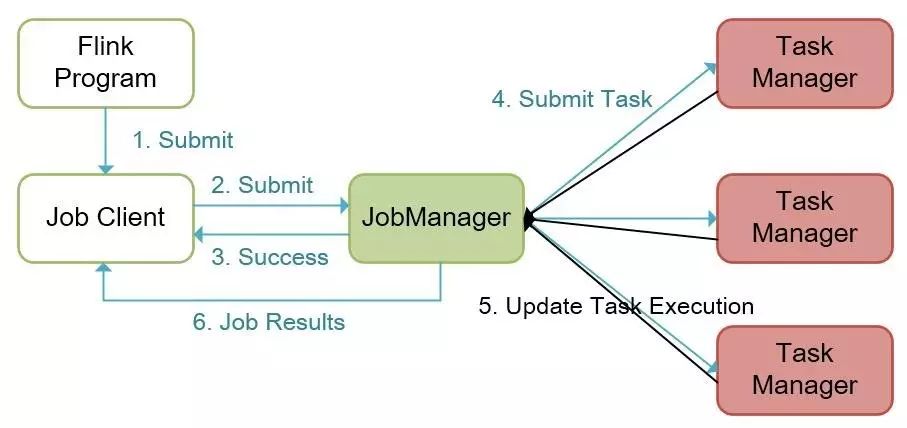
Flink程序执行流程
Flink程序通过Job Client提交给Job Manager,Job Manager负责资源分配与作业执行。Job Manager接收到任务后就会分配所需资源,并将task提交到相应的Task Manager上。Task Manager接收到task后就启动一个线程承载其任务,并将任务的执行状态实时汇报给Job Manager,包含的状态有:开始执行、正在进行、完成等。当一个Job对应的所有tasks都执行成功后,Task Manager将此Job生成的结果返回给客户端。
Job Manager
上文所提及的master进程(即Job Manager),负责协调和管理提交到集群中程序的执行,主要包括:任务调度、管理检查点、故障恢复等。一个集群中可以有多个Job Managers并行运行,分别承担以上职责,以提升系统的高可用性。其中一个Job Manager作为leader,如果leader故障则选举备用Job Manager为新的leader。Job Manager含有以下重要的组件:
Actor system
Scheduler
Check pointing
Flink系统内部Job Manager与Task Managers之间的通信采用Akka的actor system,其内部实现了多种角色,提供了多种服务,例如:调度、配置、日志记录等。Actor system有一个线程池负责启动所有actor,并且所有actor都处于层次结构中。假设有一个actor,如果它的功能过于复杂,为了降低复杂度,可以将这个功能划分成多个更小粒度的,更易管理的子任务,启动新的child actors。每一个actor的创建者,也是其监控者。Actor之间使用消息传递系统进行通信,从自己的邮箱中读取别的actor发送的消息。如果是本地的actor之间通信,消息通过共享内存进行传递,如果通信的actor之间是远程的,则消息通过RPC进行调用。
每一个Task Manager需要管理一个或者多个Slot,Flink通过Job Manager来管理哪些任务需要共享一个Slot进行执行,哪些任务需要单独的Slot执行。
为了保证系统的容错性,Flink引入了检查点机制。容错机制不断的为数据流创建轻量级的快照,因此分布式的数据流和Slot状态通过快照进行持久化。通常情况下,创建的快照被保存在用户指定的位置,例如HDFS。由于快照是轻量级的,所以对Flink系统性能的影响很小。Stream barrier是Flink快照的核心要素,在不影响流的前提下数据流中被插入了多个barrier(barrier的个数肯定不会超过记录的个数),barrier将对应的记录集融合成快照,并且每个barrier都有唯一的ID,下图显示了数据流中的barrier。
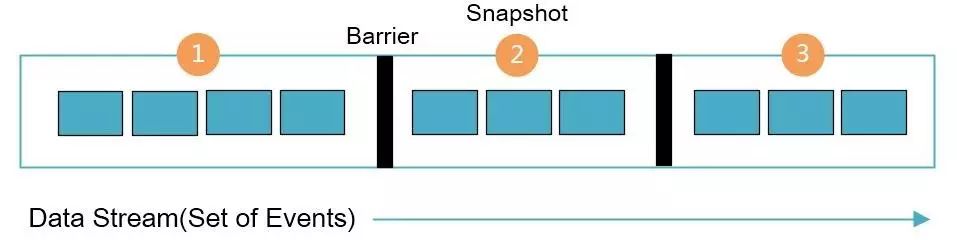
Flink的Barrier和快照
每个快照的状态都会报告给Job Manager的检查点协调器。当生成快照时,Flink为防止由于任何故障而重复处理相同的记录,会花费几毫秒对记录进行核查。对于一些对延迟敏感的任务,用户可以选择关闭对记录的核查,从而降低延迟。
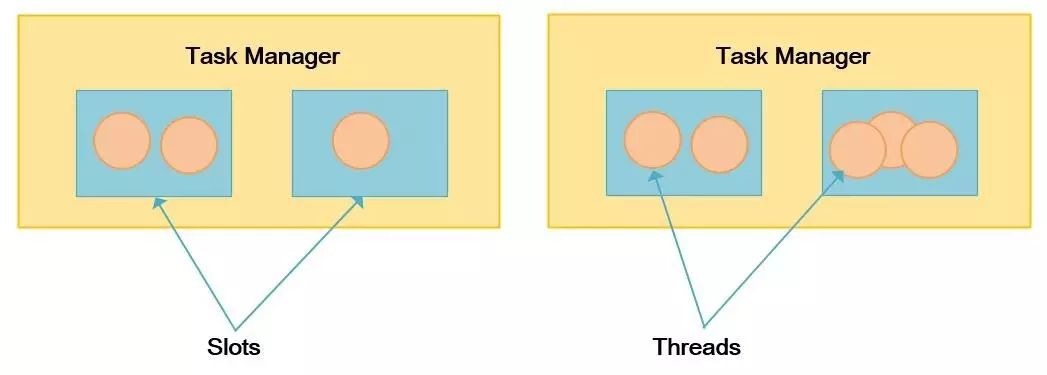
Task Manager
Task Manager是Flink集群中的工作节点,工作节点上可以有多个Slot,每个Slot单独由一个JVM承载,Slot可通过JVM中的一个或多个线程来执行任务。任务执行的并行性取决于Task Manager下可用的Slot个数。例如,一个Task Manager拥有4个Slot,则其将给每个Slot分配25%的系统资源(CPU、内存等)。
特性
高性能,Flink旨在实现高性能和低延迟,与其它流式处理框架(如Spark)不同,使用者无需执行更多的手动配置来达到最优的性能。因此,与其它同类型的技术相比,Flink对于流式数据的处理性能更优;
高容错性,Flink的分布式轻量级快照机制,能够保障集群拥有很强的容错性,并不影响系统性能;
高效内存管理,Flink在JVM内部实现了自己的内存管理功能,从而独立于JVM自带的垃圾回收机制,使得对于JVM内存的管理更加的高效;
灵活的流窗口,Flink支持数据驱动的窗口,用户可以根据时间、计数或者会话来设计一个窗口,可以在定制的窗口中检测事件流的特定模式,从而有助于处理无序到达的事件;
自动优化器,Flink的批处理API(DataSet API)被优化,以避免消耗内存的操作,例如:shuffle、排序等。并且使用缓存机制来避免重度的磁盘IO操作;
一个平台同时支持流处理和批处理,Flink分别为流处理和批处理提供了API接口,因此Flink可以同时轻松的承载流和批处理应用。实际上,Flink遵循流处理第一原则,其将批处理视为流处理的一种特殊情形来进行处理;
支持丰富的类库,Flink拥有丰富的类库来做机器学习、图形计算、关系型数据加工等任务。
结束语
Flink是一个类似Spark的“开源技术栈”,其也同样提供了批处理、流式计算、图计算、机器学习、交互式查询等。但是它们的不同之处在于,Spark的计算模型基于RDD,将流式计算看成是特殊的批处理,其DStream是微型的RDD,但还是RDD。而Flink是真正的流式处理引擎,并把批处理当成是特殊的流式计算。Flink在性能上的表现也相对很好,流式计算所耗延迟相对比Spark少,能做到真正的实时处理,而Spark只能称为准流式计算。而且在批处理场景上,当迭代次数变多时,Flink的速度比Spark还要更快。只不过,Flink的诞生时间要晚于Spark,所以如果Flink早一点出来,或许比现在的Spark更火。但是,从另外一个角度来说,正是由于Flink大量借鉴了Spark的特性,所以才有了目前的本领。当然,对于使用者来说除了产品自身特性外,还要考虑到对应社区的活跃和贡献度,并结合自身需求进行选择。
-END-
声明:
本文为中国联通网研院网优网管部IT技术研究团队独家提供。
如需转载或合作,请联系管理员(zhouyh@dimpt.com)
长按既可添加关注
以上是关于Spark的竞争者——Flink浅析的主要内容,如果未能解决你的问题,请参考以下文章