技术专栏 | flink关系型API: Table API 与SQL
Posted TalkingData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术专栏 | flink关系型API: Table API 与SQL相关的知识,希望对你有一定的参考价值。
本篇文章主要介绍flink的关系型API,整个文章主要分为下面几个部分来介绍:
一、什么是flink关系型API
二、flink关系型API的各版本演进
三、flink关系型API执行原理
四、flink关系型API目前适用场景
五、Table&SQL API介绍
六、Table&SQL API举例
七、动态表
八、总结
一
什么是flink关系型API
当我们在使用flink做流式和批式任务计算的时候,往往会想到几个问题:
需要熟悉两套API:DataStream/DataSetAPI,API有一定难度,开发人员无法focus on business
需要有Java或Scala的开发经验
flink同时支持批任务与流任务,如何让API层统一
flink已经拥有了强大的DataStream/DataSetAPI,满足流计算和批计算中的各种场景需求,但是关于以上几个问题,我们还需要提供一种关系型的API来实现Flink API层的流与批的统一,那么这就是flink的Table & SQL API。
首先Table & SQL API是一种关系型API,用户可以像操作mysql数据库表一样的操作数据,而不需要写java代码完成Flink Function,更不需要手工的优化java代码调优。另外,SQL作为一个非程序员可操作的语言,学习成本很低,如果一个系统提供SQL支持,将很容易被用户接受。
总结来说,关系型API的好处:
关系型API是声明式的
查询能够被有效的优化
查询可以高效的执行
“Everybody” knows SQL
Table&SQLAPI是流处理和批处理统一的API层,如下图。flink在runtime层是统一的,因为flink将批任务看做流的一种特例来执行,然而在API层,flink为批和流提供了两套API(DataSet和DataStream)。所以Table&SQL API就统一了flink的API层,批数据上的查询会随着输入数据的结束而结束并生成DataSet,流数据的查询会一直运行并生成结果流。Table&SQL API做到了批与流上的查询具有同样的语法语义,因此不用改代码就能同时在批和流上执行。
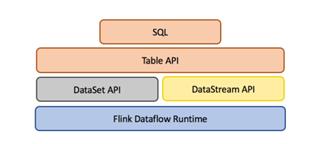
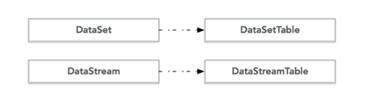
关于DataSet API和DataStream API对应的Table如下图:
二
flink关系型API的各版本演进
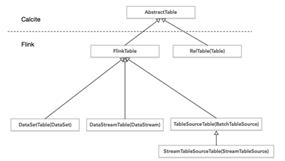
关于Table&SQL API,flink在0.9版本的时候,引进了TableAPI,支持Java和Scala两种语言,是一个类似于LINQ模式的API。用于对关系型数据进行处理。这系列 Table API的操作对象就是能够进行简单的关系型操作的结构化数据流。结构如下图。然而0.9版本的Table&SQL API有着很大的局限性,0.9版本Table API不能单独使用,必须嵌入到DataSet或者DataStream的程序中,对于批处理表的查询并不支持outer join、order by等操作。在流处理Table中只支持filters、union,不支持aggregations以及joins。并且,这个转化处理过程没有查询优化。整体来说0.9版本的Flink Table API还不是十分好用。
在后续的版本中,1.1.0引入了 SQL,因此在1.1.0版本以后,flink 提供了两个语义的关系型 API:语言内嵌的 Table API(用于 Java 和Scala)以及标准 SQL。这两种 API 被设计用于在流和批的任务中处理数据在API层的统一,这意味着无论输入是批处理数据还是流数据,查询产生完全相同的结果。
在1.20版本之后逐渐增加SQL的功能,并对Table API做了大量的Enhancement了。在1.2.0 版本中,flink 的关系 API在数据流中,支持关系操作包括投影、过滤和窗口聚合。
在1.30版本中开始支持各种流上SQL操作,例如SELECT, FROM, WHERE,UNION、aggregation和UDF能力。在2017年3月2日进行的Flink Meetup与2017年5月24日Strata会议,flink都有相应的topic讨论,未来在Flink SQL方面会支持更细粒度的join操作和对dynamic table的支持。
三
flink关系型API执行原理
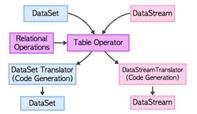
flink使用基于Apache Calcite这个SQL解析器做SQL语义解析。利用Calcite的查询优化框架与SQL解释器来进行SQL的解析、查询优化、逻辑树生成,得到Calcite的RelRoot类的一颗逻辑执行计划树,并最终生成flink的Table。Table里的执行计划会转化成DataSet或DataStream的计算,经历物理执行计划优化等步骤。但是,Table API 和 SQL最终还是基于Flink的已有的DataStream API和DataSet API,任何对于DataStream API和DataSet API的性能调优提升都能够自动地提升Table API或者SQL查询的效率。这两种API的查询都会用包含注册过的Table的catalog进行验证,然后转换成统一Calcite的logical plan。再利用 Calcite的优化器优化转换规则和logical plan。根据数据源的性质(流和批)使用不同的规则进行优化。最终优化后的plan转传成常规的Flink DataSet 或 DataStream 程序。结构如下图:
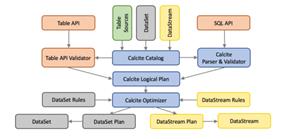
3.1 Translationto Logical Plan
每次调用Table&SQL API,就会生成flink 逻辑计划的节点。比如对groupBy和select的调用会生成节点Project、Aggregate、Project,而filter的调用会生成节点Filter。这些节点的逻辑关系,就会组成下图的一个flink自身数据结构表达的一颗逻辑树;根据这个已经生成的flink的logical Plan,将它转换成calcite的logicalPlan,这样我们才能用到calcite强大的优化规则。flink由上往下依次调用各个节点的construct方法,将flink节点转换成calcite的RelNode节点。
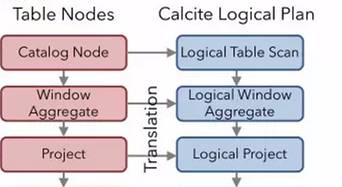
3.2 Translationto DataStream Plan
优化逻辑计划并转换成flink的物理计划,flink的这部分实现统一封装在optimize方法里头。这部分涉及到多个阶段,每个阶段都是用Rule对逻辑计划进行优化和改进。声明定义于派生RelOptRule的一个类,然后再构造函数中要求传入RelOptRuleOperand对象,该对象需要传入这个Rule将要匹配的节点类型。如果这个自定义的Rule只用于LogicalTableScan节点,那么这个operand对象应该是operand(LogicalTableScan.class,any())。通过以上代码对逻辑计划进行了优化和转换,最后会将逻辑计划的每个节点转换成Flink Node,既可物理计划。
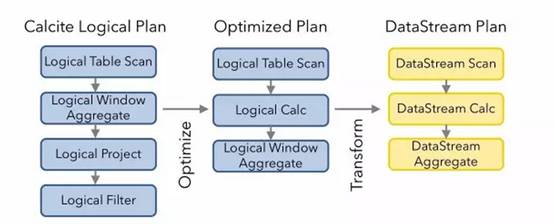
3.3 Translation to Flink Program
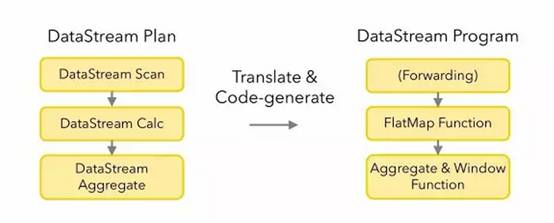
四
flink关系型API目前适用场景
4.1 目前支持范围
Batch SQL & Table API 支持:
Selection, Projection, Sort, Inner & Outer Joins, Set operations
Windows for Slide, Tumble, Session
Streaming Table API 支持:
Selection, Projection, Union
Windows for Slide, Tumble, Session
Streaming SQL:
Selection, Projection, Union, Tumble
4.2 目前使用场景

五
Table&SQL API介绍
Table API一般与DataSet或者DataStream紧密关联,可以通过一个DataSet或DataStream创建出一个Table,再用类似于filter, join, 或者 select关系型转化操作来转化为一个新的Table对象。最后将一个Table对象转回一个DataSet或DataStream。从内部实现上来说,所有应用于Table的转化操作都变成一棵逻辑表操作树,在Table对象被转化回DataSet或者DataStream之后,转化器会将逻辑表操作树转化为对等的DataSet或者DataStream操作符。
5.1 Table&SQLAPI的简单介绍
1.Create a TableEnvironment
TableEnvironment对象是Table API和SQL集成的一个核心,支持以下场景:
注册一个Table
注册一个外部的catalog
执行SQL查询
注册一个用户自定义的function
将DataStream或DataSet转成Table
一个查询中只能绑定一个指定的TableEnvironment,TableEnvironment可以通过来配置TableConfig来配置,通过TableConfig可以自定义查询优化以及translation的进程。
TableEnvironment执行过程如下:
1. TableEnvironment.sql()为调用入口;
2. flink实现了个FlinkPlannerImpl,执行parse(sql),validate(sqlNode),rel(sqlNode)操作;
3. 生成Table;
其中,LogicalRelNode是flink执行计算树里的叶子节点。
源码如下图:
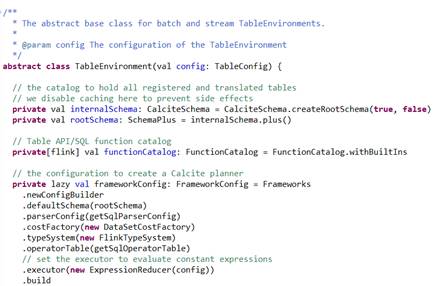

2.Register a Table
(1)将一个Table注册给TableEnvironment

(2)将一个TableSource注册给TableEnvironment,这里的TableSource指的是将数据存储系统的作为Table,例如mysql,hbase,CSV,Kakfa,RabbitMQ等等。
(3)将一个外部的Catalog注册给TableEnvironment,访问外部系统的数据或文件。
(4)将DataStream或DataSet注册为Table
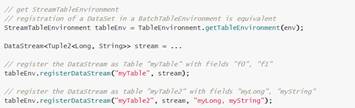
3. Query a Table
(1)Table API
Table API是一个Scala和Java的集成查询序言。与SQL不同的是,Table API的查询不是一个指定的sql字符串,而是调用指定的API方法。TableAPI中的每一个方法输入都是一个Table,输出也是一个新的Table。通过table API来提交任务的话,也会经过calcite优化等阶段,基本流程和直接运行sql类似:
1.table API parser: flink会把table API表达的计算逻辑也表示成逻辑树,用treeNode表示;
2.在这棵树上的每个节点的计算逻辑用Expression来表示。
3.Validate: 会结合catalog将树的每个节点的Unresolved Expression进行绑定,生成Resolved Expression;
4.生成Logical Plan: 依次遍历数的每个节点,调用construct方法将原先用treeNode表达的节点转成成用calcite 内部的数据结构relNode 来表达。即生成了LogicalPlan, 用relNode表示;
5.生成 optimized Logical Plan: 先基于calciterules 去优化logical Plan,
6.再基于flink定制的一些优化rules去优化logical Plan;
7.生成Flink Physical Plan: 这里也是基于flink里头的rules将,将optimized LogicalPlan转成成Flink的物理执行计划;
8.将物理执行计划转成Flink Execution Plan: 就是调用相应的tanslateToPlan方法转换。

(2)SQL
Flink SQL是基于Apache Calcite的实现的,Calcite实现了SQL标准解析。SQL查询是一个完整的sql字符串来查询。一条stream sql从提交到calcite解析、优化最后到flink引擎执行,一般分为以下几个阶段:
1. Sql Parser: 将sql语句解析成一个逻辑树,在calcite中用SqlNode表示逻辑树;
2. Sql Validator: 结合catalog去验证sql语法;
3.生成Logical Plan: 将sqlNode表示的逻辑树转换成Logical Plan, 用relNode表示;
4.生成 optimizedLogical Plan: 先基于calcite rules 去优化logical Plan,
5. 再基于flink定制的一些优化rules去优化logical Plan;
6.生成Flink PhysicalPlan: 这里也是基于flink里头的rules将,将optimized Logical Plan转成成flink的物理执行计划;
7.将物理执行计划转成FlinkExecution Plan: 就是调用相应的tanslateToPlan方法转换。
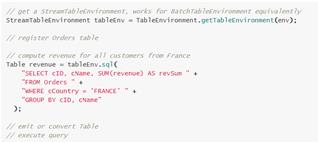
(3)Table&SQL API混合使用
Table API和SQL查询可以很容易的混合使用,因为它们的返回结果都是Table对象。一个基于Table API的查询可以基于一个SQL查询的结果。同样地,一个SQL查询可以被定义一个Table API注册TableEnvironment作为Table的查询结果。
4.输出Table
为了将Table进行输出,我们可以使用TableSink。TableSink是一个通用的接口,支持各种各样的文件格式(e.g. CSV, Apache Parquet, Apache Avro),也支持各种各样的外部系统(e.g., JDBC, Apache HBase, Apache Cassandra, Elasticsearch),同样支持各种各样的MQ(e.g., Apache Kafka, RabbitMQ)。
批数据的导出Table使用BatchTableSink,流数据的导出Table使用的是AppendStreamTableSink,RetractStreamTableSink和UpsertStreamTableSink.
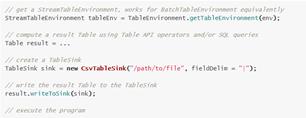
5.解析Query并执行
Table&SQL API查询被解析成DataStream或DataSet程序。一次查询就是一个 logical query plan,解析这个logical query plan分为两步:
优化logical plan,
将logical plan转为DataStream或DataSet
一旦Table&SQLAPI解析完毕, Table& SQL API的查询就会被当做普通DataStream或DataSet被执行。
5.2 Table转为DataStream或DataSet
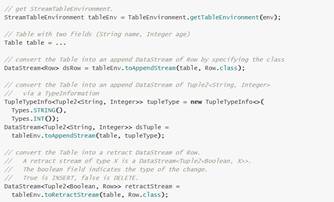
5.3 Convert a Table into a DataSet
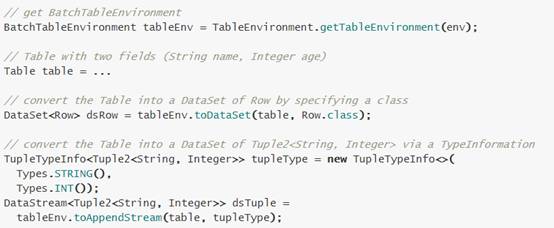
5.4 Table&SQL API与Window
Window种类
tumbling window (GROUP BY)
sliding window (window functions)
(1)TumblingWindow
SELECTSTREAM TUMBLE_END(rowtime,INTERVAL'1'HOUR)ASrowtime,
productId,
COUNT(*)ASc,
SUM(units)ASunits
FROMOrders
GROUPBYTUMBLE(rowtime,INTERVAL'1'HOUR), productId;
(1)SlidingWindow
SELECTSTREAM rowtime,
productId,
units,
SUM(units)OVER (ORDERBYrowtime RANGEINTERVAL'1'HOURPRECEDING) unitsLastHour
FROMOrders;
5.5 Table&SQL API与Stream Join
Joining streams to streams:
SELECTSTREAM o.rowtime, o.productId, o.orderId,s.rowtimeASshipTime
FROMOrdersASo
JOINShipmentsASs
ONo.orderId = s.orderId
ANDs.rowtime BETWEEN o.rowtimeANDo.rowtime +INTERVAL'1'HOUR
六
Table&SQL API举例
首先需要引入flink 关系型api和scala的相关jar包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.10</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.10</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.10</artifactId>
<version>1.3.2</version>
</dependency>
6.1 批数据的相关代码
List<DataPackage>data = new ArrayList<DataPackage>();
data.add(new DataPackage(1L,"Effy", 1, 100));
data.add(new DataPackage(2L, "Michael",2, 500));
data.add(new DataPackage(3L,"Alvin", 3, 9999));
data.add(new DataPackage(3L,"Alvin", 3, 190));
data.add(new DataPackage(1L,"Effy", 1, 550));
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
BatchTableEnvironment bTEnv =TableEnvironment.getTableEnvironment(env);
DataSource source =env.fromCollection(data);
try {
// convert DataSet to Table
Table table =bTEnv.fromDataSet(source);
// register topScore as a Table
bTEnv.registerTable("dataPackage",table);
// sql
Table resultTable = bTEnv
.sql("select id,sum(paymentAmount) as sum_total_payment_amount from dataPackage group by idorder by 2 desc");
// convert Table back to dataset
DataSet<Result> result =bTEnv.toDataSet(resultTable, Result.class);
// sink dataset map as tuple
result.map(newMapFunction<Result, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long,Integer> map(Result result) throws Exception {
long id =result.getId();
intsum_total_payment_amount = result.getSum_total_payment_amount();
return Tuple2.of(id,sum_total_payment_amount);
}
}).print();
} catch (Exception e) {
e.printStackTrace();
}
6.2 流数据的相关代码
StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
org.apache.flink.table.api.java.StreamTableEnvironmenttableEnv = TableEnvironment.getTableEnvironment(env);
try {
Properties consumerProperties =new Properties();
consumerProperties.load(
Thread.currentThread().getContextClassLoader().getResourceAsStream("KafkaConsumer.properties"));
String topic =consumerProperties.getProperty("topic");
Properties kafkaArguements = newProperties();
kafkaArguements.putAll(consumerProperties);
DataStream<String>sourceStream = env
.addSource(new FlinkKafkaConsumer08<String>(topic,new SimpleStringSchema(), consumerProperties));
DataStream<DataPackage> dataStreamOri= sourceStream.assignTimestampsAndWatermarks(newGenericTimestampsAndWatermarks());
DataStream<DataPackage>dataStream = dataStreamOri.flatMap(new ConvertflatMappOperator());
// register a Table in theCatalog
tableEnv.registerDataStream("dataPackage",dataStream);
// create a Table from a TableAPI query
Table tapiResult =tableEnv.scan("dataPackage").filter("id >0").groupBy("id")
.select("id,sum(paymentAmount) as sum_total_payment_amount");
// create a Table from a SQLquery
Table sqlResult =tableEnv.sql("SELECT id, sum(paymentAmount) as sum_total_payment_amount"
+ "FROMdataPackage " + "WHERE id > 0 " + "GROUP BY id");
WindowedTable windowedTable =tapiResult.window(Tumble.over("10.minutes").on("ts").as("tsWindow"));
DataStream<String> stream1= tableEnv.toAppendStream(tapiResult, String.class);
DataStream<String> stream2= tableEnv.toAppendStream(sqlResult, String.class);
Properties producerProperties =new Properties();
producerProperties.load(
Thread.currentThread().getContextClassLoader().getResourceAsStream("KafkaProducer.properties"));
Properties kafkaArguements2 = newProperties();
kafkaArguements2.putAll(producerProperties);
stream1.addSink(new FlinkKafkaProducer08<String>(producerProperties.getProperty("topic1"),
newSimpleStringSchema(), kafkaArguements2));
stream2.addSink(new FlinkKafkaProducer08<String>(producerProperties.getProperty("topic2"),
newSimpleStringSchema(), kafkaArguements2));
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
七
动态表
flink1.3以后,在flink sql上支持动态表查询,也就是说动态表是持续更新,并且能够像常规的静态表一样查询的表。但是,与批处理表查询终止后返回一个静态表作为结果不同的是,动态表中的查询会持续运行,并根据输入表的修改产生一个持续更新的表。因此,结果表也是动态的。在动态表中运行查询并产生一个新的动态表,这是因为流和动态表是可以相互转换的。
流被转换为动态表,动态表使用一个持续查询进行查询,产生一个新的动态表。最后,结果表被转换成流。上面所说的只是逻辑模型,并不意味着实际执行的查询查询也是这个步骤。实际上,持续查询在内部被转换成传统的 DataStream 程序去执行。
动态表查询步骤如下:
在流中定义动态表
查询动态表
生成动态表
7.1 在流中定义动态表
动态表上的 SQL 查询的第一步是在流中定义一个动态表。这意味着我们必须指定流中的记录如何修改现有的动态表。流携带的记录必须具有映射到表的关系模式。在流中定义动态表有两种模式:append模式和update模式。
在append模式中,流中的每条记录是对动态表的插入修改。因此,流中的所有记录都append到动态表中,使得它的大小不断增长并且无限大。下图说明了append模式。append模式如下图。
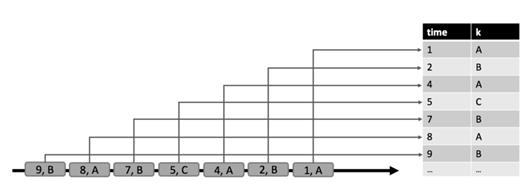
在update模式中,流中的记录可以作为动态表的插入、更新或者删除修改(append模式实际上是一种特殊的update模式)。当在流中通过update模式定义一个动态表时,我们可以在表中指定一个唯一的键属性。在这种情况下,更新和删除操作会带着键属性一起执行。更新模式如下图所示。
7.2 查询动态表
一旦我们定义了动态表,我们可以在上面执行查询。由于动态表随着时间进行改变,我们必须定义查询动态表的意义。假定我们有一个特定时间的动态表的snapshot,这个snapshot可以作为一个标准的静态批处理表。我们将动态表 A 在点 t 的snapshot表示为 A[t],可以使用 SQL 查询来查询snapshot,该查询产生了一个标准的静态表作为结果,我们把在时间 t 对动态表 A 做的查询 q 的结果表示为 q(A[t])。如果我们反复在动态表的snapshot上计算查询结果,以获取进度时间点,我们将获得许多静态结果表,它们随着时间的推移而改变,并且有效的构成了一个动态表。我们在动态表的查询中定义如下语义:查询q 在动态表 A 上产生了一个动态表 R,它在每个时间点 t 等价于在 A[t] 上执行 q 的结果,即 R[t]=q(A[t])。该定义意味着在批处理表和流表上执行相同的查询 q 会产生相同的结果。
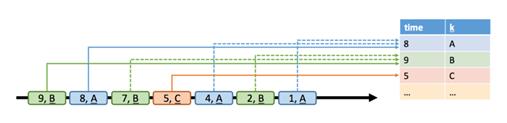
在下面的例子中,我们给出了两个例子来说明动态表查询的语义。在下图中,我们看到左侧的动态输入表 A,定义成append模式。在时间t=8 时,A 由 6 行(标记成蓝色)组成。在时间 t=9 和 t=12 时,有一行追加到A(分别用绿色和橙色标记)。我们在表 A 上运行一个如图中间所示的简单查询,这个查询根据属性 k 分组,并统计每组的记录数。在右侧我们看到了 t=8(蓝色),t=9(绿色)和 t=12(橙色)时查询q 的结果。在每个时间点 t,结果表等价于在时间 t 时再动态表 A 上执行批查询。
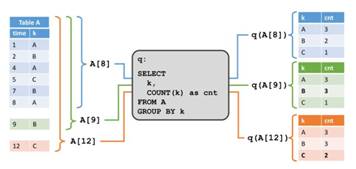
这个例子中的查询是一个简单的分组(但是没有窗口)聚合查询。因此,结果表的大小依赖于输入表的分组键的数量。此外,这个查询会持续更新之前产生的结果行,而不只是添加新行。
第二个例子展示了一个类似的查询,但是有一个很重要的差异。除了对属性 k 分组以外,查询还将记录每 5 秒钟分组为一个滚动窗口,这意味着它每 5 秒钟计算一次 k 的总数。 我们使用 Calcite 的分组窗口函数来指定这个查询。在图的左侧,我们看到输入表 A ,以及它在append模式下随着时间而改变。在右侧,我们看到结果表,以及它随着时间演变。
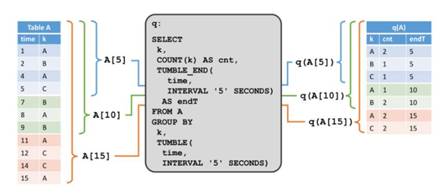
与第一个例子的结果不同的是,这个结果表随着时间而增长,例如每 5 秒钟计算出新的结果行。虽然非窗口查询更新结果表的行,但是窗口聚合查询只追加新行到结果表中。无论输入表什么时候更新,都不可能计算查询的完整结果。相反,查询编译成流应用,根据输入的变化持续更新它的结果。这意味着不是所有的有效 SQL 都支持,只有那些持续性的、递增的和高效计算的被支持。
7.3 生成动态表
查询动态表生成的动态表,其相当于查询结果。根据查询和它的输入表,结果表会通过插入、更新和删除持续更改,就像普通的mysql数据表一样。它可能是一个不断被更新的单行表,或是一个只插入不更新的表。
传统的mysql数据库在故障和复制的时候,通过日志重建表。比如 UNDO、REDO 和UNDO/REDO 日志。UNDO 日志记录被修改元素之前的值来回滚不完整的事务,REDO 日志记录元素修改的新值来重做已完成事务丢失的改变,UNDO/REDO 日志同时记录了被修改元素的旧值和新值来撤销未完成的事务,并重做已完成事务丢失的改变。基于这些日志,动态表可以转换成两类更改日志流:REDO 流和 REDO+UNDO 流。
通过将表中的修改转换为流消息,动态表被转换为 redo+undo 流。插入修改生成一条新行的插入消息,删除修改生成一条旧行的删除消息,更新修改生成一条旧行的删除消息以及一条新行的插入消息。行为如下图所示。
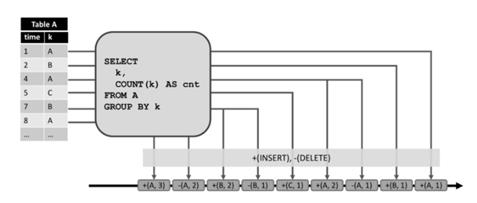
左侧显示了一个维护在append模式下的动态表,作为中间查询的输入。查询的结果转换为显示在底部的 redo+undo 流。输入表的第一条记录 (1,A) 作为结果表的一条新纪录,因此插入了一条消息 +(A,1) 到流中。第二条输入记录 k=‘A’(4,A) 导致了结果表中 (A,1) 记录的更新,从而产生了一条删除消息 -(A,1) 和一条插入消息 +(A,2)。所有的下游操作或数据汇总都需要能够正确处理这两种类型的消息。
在两种情况下,动态表会转换成 redo 流:要么它只是一个append表(即只有插入修改),要么它有一个唯一的键属性。动态表上的每一个插入修改会产生一条新行的插入消息到 redo 流。由于 redo 流的限制,只有带有唯一键的表能够进行更新和删除修改。如果一个键从动态表中删除,要么是因为行被删除,要么是因为行的键属性值被修改了,所以一条带有被移除键的删除消息发送到 redo 流。更新修改生成带有更新的更新消息,比如新行。由于删除和更新修改根据唯一键来定义,下游操作需要能够根据键来访问之前的值。下图描述如何将上述相同查询的结果表转换为 redo 流。
插入到动态表的 (1,A) 产生了 +(A,1) 插入消息。产生更新的 (4,A) 生成了 *(A,2) 的更新消息。
Redo 流的通常做法是将查询结果写到仅append的存储系统,比如滚动文件或者 Kafka topic ,或者是基于key访问的数据存储,比如 Cassandra、关系型 mysql。
切换到动态表发生的改变:
在1.2 版本中,flink 关系 API 的所有流操作,例如过滤和分组窗口聚合,只会产生新行,并且不能更新先前发布的结果。相比之下,动态表能够处理更新和删除修改。1.2 版本中的处理模型是动态表模型的一个子集, 通过附加模式将流转换为动态表,即一个无限增长的表。由于所有操作仅接受插入更改并在其结果表上生成插入更改(即,产生新行),因此所有在动态append表上已经支持的查询,将使用重做模型转换回 DataStreams,仅用于append表。
最后,值得注意的是在开发代码中,我们无论是使用Table API还是SQL,优化和转换程序并不知道查询是通过 Table API 还是 SQL 来定义的。由于 Table API 和 SQL 在语义方面等同,只是在样式上有些区别而已。
八
总结
本篇文章整理了flink关系型API的相关知识,整体上来说,Flink关系型API还是很好用的,其原理与实现结构清晰,存在很多可借鉴的地方。
Reference:
http://flink.apache.org/
Flink社区
2017Strata Meeting
2017 FlinkForward Meeting
本周的技术分享就到这里,感谢观看!
以上是关于技术专栏 | flink关系型API: Table API 与SQL的主要内容,如果未能解决你的问题,请参考以下文章
flink笔记11 Flink Table API和SQL的简单实例