flink笔记11 Flink Table API和SQL的简单实例
Posted Aurora1217
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink笔记11 Flink Table API和SQL的简单实例相关的知识,希望对你有一定的参考价值。
Apache Flink有两个关系应用编程接口——the Table API and SQL ,用于统一的流和批处理
The Table API and SQL 相互无缝集成,与Flink的DataStream API无缝集成
1.Table API & SQL简介
Table API是流处理和批处理通用的关系型API,Table API可以基于流输入或者批输入来运行而不需要进行任何修改
flink根据使用的便捷性提供了三种API,自下而上是:
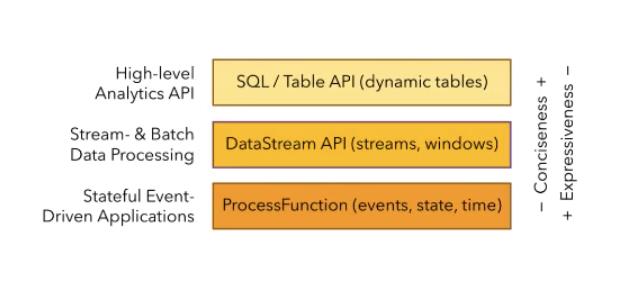
Flink的API是分层的,而Table API与SQL就位于最顶层。也就是说Table API和SQL是Flink中封装程度最高的API
Table API & SQL特点
- 声明行:用户只关心做什么,不用关心怎么做
- 高性能:支持性能优化,可以获取更好的执行性能
- 流批统一:相同的统计逻辑,既可以流模式运行,也可以批模式运行
- 性能稳定:语义遵循SQL标准,不易变动
- 易理解:语义明确,所见即所得
2.引入依赖
使用(写代码)之前,现在pom.xml里引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>3.Table ApI简单例子
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object example
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputstream = env.socketTextStream("localhost",7777)
val datastream = inputstream
.map(
data =>
var arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
//首先创建表执行环境
val tableEnv = StreamTableEnvironment.create(env)
//基于流创建一张表
val dataTable = tableEnv.fromDataStream(datastream)
//调用table API进行转换查询
val resultTable = dataTable
.select("id,temperature")
.filter("id =='sensor_2'")
//输出
resultTable.toAppendStream[(String,Double)].print("result")
env.execute("example test")
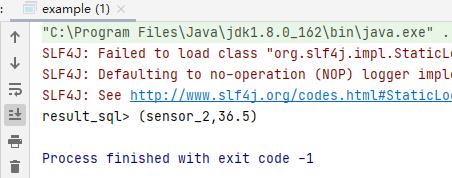
两个例子的执行结果相同:
4.SQL简单例子
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object example
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputstream = env.socketTextStream("localhost",7777)
val datastream = inputstream
.map(
data =>
var arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
//首先创建表执行环境
val tableEnv = StreamTableEnvironment.create(env)
//基于流创建一张表
val dataTable = tableEnv.fromDataStream(datastream)
//创建视图(虚拟的表)
tableEnv.createTemporaryView("dataTable",dataTable)
//查询转换 写到这里sqlQuery()里面敲三个双引号回车
val resultSqlTable = tableEnv.sqlQuery(
"""
|select id,temperature
|from dataTable
|where id = 'sensor_2'
|""".stripMargin)
//输出
resultSqlTable.toAppendStream[(String,Double)].print("result_sql")
env.execute("example test")
5.总结
在流处理环境中,进行Table API和SQL操作
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object test
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//中间写内容
env.execute("test")
也可以是批处理环境,Table API 和 SQL 查询可以很容易地集成并嵌入到 DataStream 或 DataSet 程序中
Table API和SQL步骤:
①创建 TableEnvironment
②在catalog中创建表
③转换表
④输出表
具体讲解在下一篇:[Table API和SQL] 创建表环境、创建表_Aurora1217的博客-CSDN博客
[Table API和SQL] 查询表、输出表_Aurora1217的博客-CSDN博客
以上是关于flink笔记11 Flink Table API和SQL的简单实例的主要内容,如果未能解决你的问题,请参考以下文章