Flink内存管理源码解读之基础数据结构
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink内存管理源码解读之基础数据结构相关的知识,希望对你有一定的参考价值。
概述
在分布式实时计算领域,如何让框架/引擎足够高效地在内存中存取、处理海量数据是一个非常棘手的问题。在应对这一问题上Flink无疑是做得非常杰出的,Flink的自主内存管理设计也许比它自身的知名度更高一些。正好最近在研读Flink的源码,所以开两篇文章来谈谈Flink的内存管理设计。
Flink的自主内存管理的亮点体现在作为以Java为主的(部分功能用Scala实现,也是一种遵循JVM规范并依赖JVM解释执行的函数式编程语言)的程序却自主实现内存的管理而不完全依赖于JVM的内存管理机制。它的优势在于灵活、为大数据场景而生、避免(不受控的)频繁GC导致的性能波动,某种程度上跳出了JVM的限制,是一种思路上的开拓。
基本上我们将Flink的内存设计分为两个部分(遵循package的划分方式):
基础数据结构(package:org.apache.flink.core.memory)
内存管理机制(package:org.apache.flink.runtime.memory)
我们将分开来进行讲解,本篇主要关注基本数据结构。内存管理机制请等待后续文章分析。
下图是该package中所有类的关系图:
其中:MemorySegment,HeapMemorySegment,HybridMemorySegment是最为关键的三个类,我们将重点分析。
Flink抽象出的内存类型
Flink将其管理的内存抽象为两种类型(主要的抽象依据内存的位置):
HEAP:JVM堆内存
OFF_HEAP:非堆内存
这在Flink中被定义为一个枚举类型:MemoryType。
MemorySegment
Flink所管理的内存被抽象为数据结构:MemorySegment
据此,Flink为它提供了两种实现:
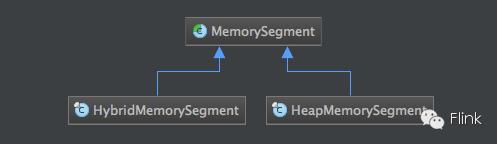
HeapMemorySegment : 管理的内存还是JVM堆内存的一部分
HybridMemorySegment : Hybrid(on-heap or off-heap)MemorySegment,内存可能为JVM堆内存,也可能不是。
MemorySegment的相关字段:
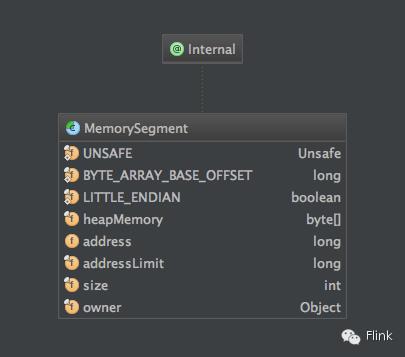
UNSAFE : 用来对堆/非堆内存进行操作,是JVM的非安全的API
BYTE_ARRAY_BASE_OFFSET : 二进制字节数组的起始索引,相对于字节数组对象
LITTLE_ENDIAN : 布尔值,是否为小端对齐(涉及到字节序的问题)
heapMemory : 如果为堆内存,则指向访问的内存的引用,否则若内存为非堆内存,则为null
size : 内存段的字节数
其中,LITTLE_ENDIAN获取的是当前操作系统的字节顺序,它是布尔值,后续的很多put/get操作都需要先判断是bigedian(大端)还是littleedian(小端)。
关于字节序的问题,如果不明白请自行Google
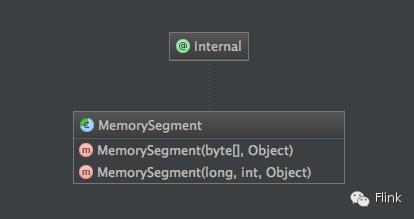
进入代码主题,针对on-heap内存和off-heap内存提供了两个构造器:
并且,提供了一大堆get/put方法,这些getXXX/putXXX大都直接或者间接调用了unsafe.getXXX/unsafe.putXXX。这些处理不同内存类型公共的方法在`MemorySegment`中实现。
当然不止这么多,这只是部分。
而特定的内存访问实现在两个各自类中。
在MemorySegment类中还有三个值得关注的方法:
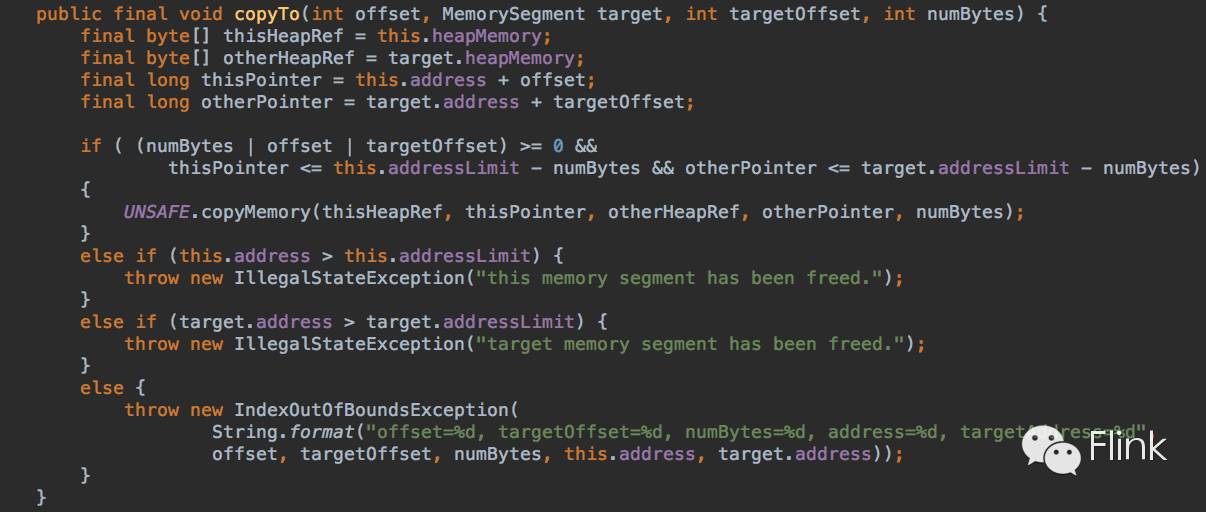
这是一个批量拷贝方法,用于从当前memory segment的offset偏移量开始拷贝numBytes长度的字节到target memory segment中从targetOffset起始的地方。
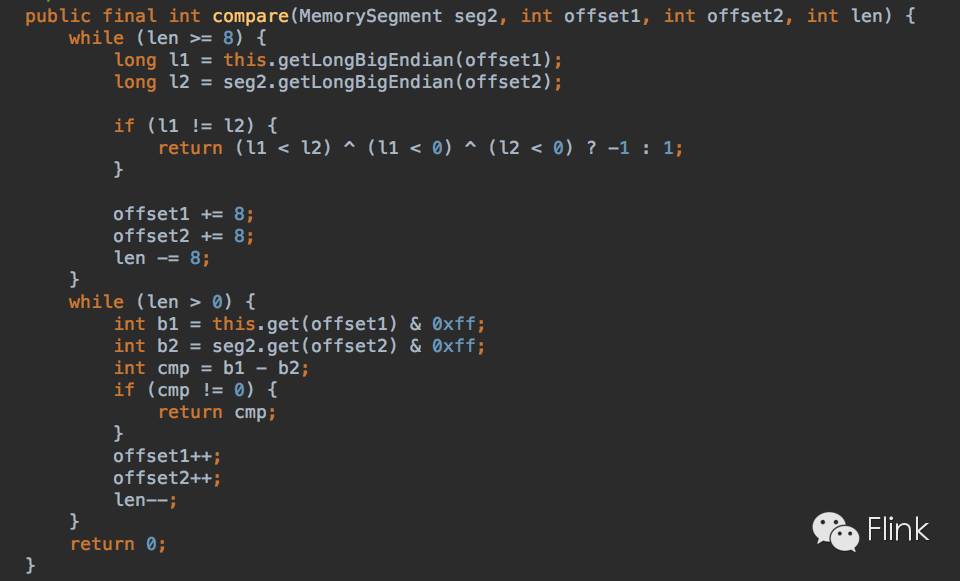
自实现的比较方法,用于对当前memory segment偏移offset1长度为len的数据与seg2偏移起始位offset2长度为len的数据进行比较。
这里有两个while循环:
第一个while是逐字节比较,如果len的长度大于8就从各自的起始偏移量开始获取其数据的长整形表示进行对比,如果相等则各自后移8位(一个字节),并且长度减8,以此循环往复。
第二个循环比较的是最后剩余不到一个字节(八个比特位),因此是按位比较
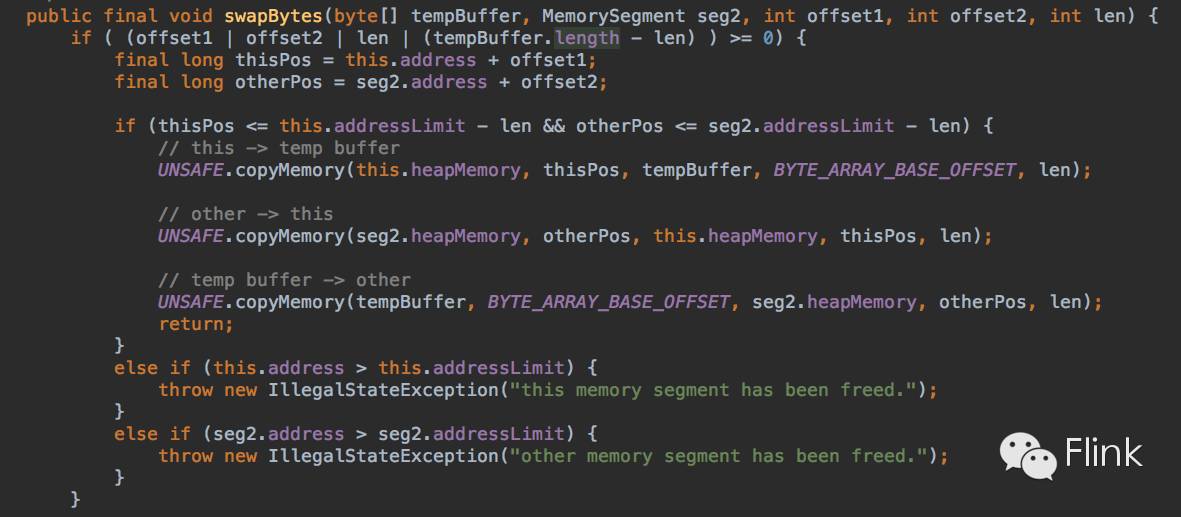
这个方法用于对两个memory segment中的一段数据进行交换。除了一些边界值判断,就是一个借助于临时变量的数据交换,只不过用`unsafe.copyMemory`代替了赋值号而已。
下面我们将探讨Flink提供的对两种类型的内存管理:on-heap 以及 off-heap。
HeapMemorySegment
基于JVM堆内存(on-heap)实现的memory segment,这也是Flink最早的内存自管理机制。该类内部定义一个字节数组的引用指向该内存段,之前提到`MemorySegment`里的那些抽象方法在该类中的实现都基于该内部字节数组的引用进行操作的,以此来获得内建的而非额外的自实现检查(这些检查比如数组越界等)。这是什么意思呢?当你定义:
private byte[] memory;
该memory指向MemorySegment中的heapMemory时,实现类似如下这种方法时: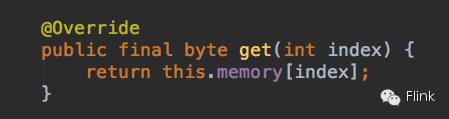
你就可以利用JVM自身的机制来判断index是否在0到length - 1之间。而不用去结合address等属性来判断索引范围了,比如上面这个方法在HybridMemorySegment里是这么实现的:
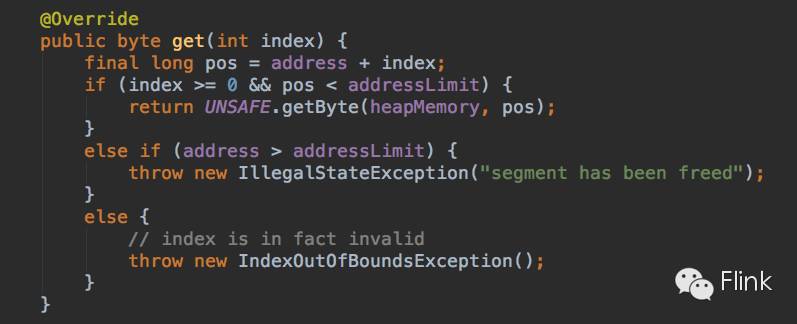
这个实现必须这么自行check边界值。
因为是JVM的堆内存,所以很多方法的调用可以直接利用JDK自带的方法,比如数组拷贝:
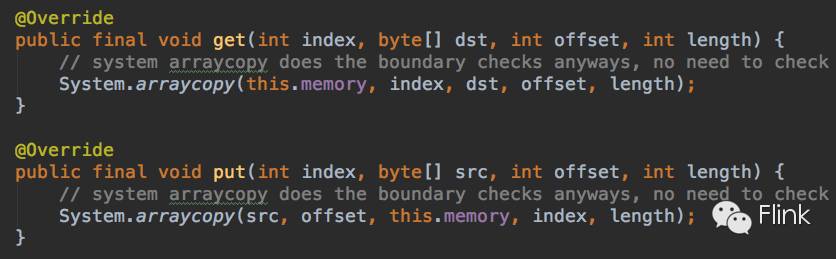
其他方法的实现都很常规,没有太多值得提点的地方。
HybridMemorySegment
这是另一种内存管理实现:它既支持on-heap内存也支持off-heap内存。乍一看,似乎有些匪夷所思,因为已经有一个对on-heap的实现了,为什么还要搞一个Hybrid的,而不是off-heap的? 而且在一个类中对两种不同的内存区域进行操作,也会显得混乱。
那么我们先来看看Flink是如何“优雅”地避免混乱的。这一切还要归功于JVM提供的非安全的操作类(unsafe)提供的一系列方法:
unsafe.XXX(Object o, int offset/position, ...)
这些方法有如下特点:
还记得我们在介绍`MemorySegment`类时,提到的两个属性:
heapMemory
address
这两个属性组合就可以适配上面的两种场景了。而且,MemorySegment的一个构造参数:offHeapAddress,已经基本指明了该构造器是专门针对off-heap的了。
MemorySegment给出了一些针对特定数据类型的公共实现,大部分也调用了unsafe的具有如上这种特性的方法,因此其实MemorySegment里已经具有Hybrid的意思了。
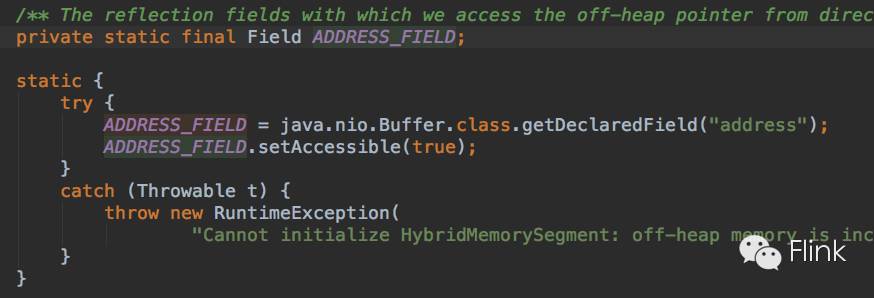
通过反射Buffer类获得 **address** 属性的Field表示,然后:
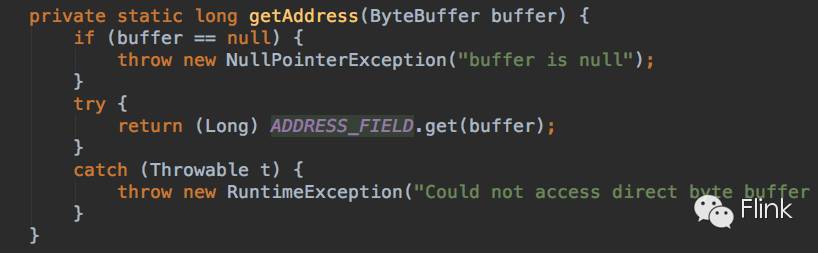
虽然通过如上的MemorySegment的两个属性再加上unsafe相关方法的特殊性,HybridMemorySegment的实现已经很清晰,简洁。但它内部还维护了一个指向它管理的off-heap数据的引用:offHeapBuffer。一方面是为了hold住那段内存空间不被释放,另一方面是为了实现自身的一些方法。
MemorySegmentFactory
MemorySegmentFactory是用来创建MemorySegment,而且Flink严重推荐使用它来创建`MemorySegment`的实例,而不是手动实例化。其目的是:为了让运行时只存在某一种MemorySegment的子类实现的实例,而不是MemorySegment的两个子类的实例都同时存在,因为这会让JIT有加载和选择上的开销,导致大幅降低性能。关于这一点,Flink官方博客专门开了一篇博文来解释他们的对比以及测试方案,请见最后的引用。
MemorySegmentFactory相关的类图,如下图:
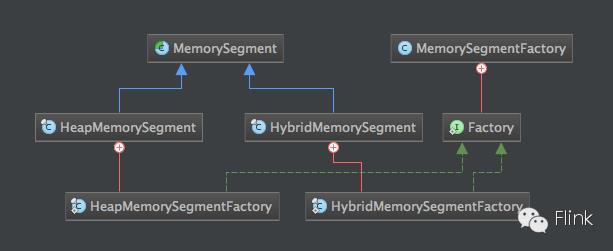
显而易见,这是设计模式中的工厂方法模式。
MemorySegmentFactory有个内部接口类Factory,MemorySegment的两个实现类的内部类各自实现了该接口,并定义了各自Factory的实现。这块并没有特别的,只是为了防止外部直接实例化HybridMemorySegmentFactory和HeapMemorySegmentFactory,它们各自的构造器都被设置为private。
MemorySegmentFactory类提供了跟Factory接口类似的方法,或者应该说包裹了一层用来指定Factory具体实例的逻辑(基本上每个方法都先调用了ensureInitialized方法):
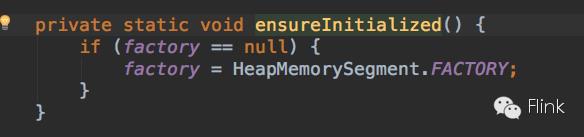
从上面可以看出,MemorySegmentFactory默认使用的是HeapMemorySegment类的实例来实现MemorySegment。
view:构建在MemorySegment之上的抽象
除了MemorySegment的相关实现,Flink的Core包还提供了建立在MemorySegment之上的更高的抽象:DataView(数据视图)。
数据视图相关的类关系图:
有两个接口,分别为输出视图`DataOutputView`(数据写相关),输入视图`DataInputView`(数据读相关)。两个接口下分别各有一个子接口提供基于position的seek动作(即指定位置的数据读写操作)。另外分别有两个实现类,它们各自包装了对应的Stream接口。这块也没什么特别的,不做过多说明。
以上是对Flink自主管理内存的数据结构部分的实现解读。
在线源码:https://github.com/apache/flink/blob/master/flink-core%2Fsrc%2Fmain%2Fjava%2Forg%2Fapache%2Fflink%2Fcore%2Fmemory%2FMemorySegment.java
引用
[1]https://flink.apache.org/news/2015/09/16/off-heap-memory.html
以上是关于Flink内存管理源码解读之基础数据结构的主要内容,如果未能解决你的问题,请参考以下文章