Flink中task之间的数据交换机制
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink中task之间的数据交换机制相关的知识,希望对你有一定的参考价值。
Flink中的数据交换构建在如下两条设计原则之上:
数据交换的控制流(例如,为实例化交换而进行的消息传输)是接收端初始化的,这非常像最初的MapReduce。
数据交换的数据流(例如,在网络上最终传输的数据)被抽象成一个叫做IntermediateResult的概念,它是可插拔的。这意味着系统基于相同的实现逻辑可以既支持流数据,又支持批处理数据的传输。
数据传输包含多个对象,它们是:
JobManager master节点,用于响应任务调度、恢复、协作,以及通过ExecutionGraph数据结构来hold住job的整个图结构。
TaskManager worker节点,一个TaskManager(TM)在多线程中并发执行多个task。每一个TM也包含一个CommunicationManager(CM - 任务之间共享),以及一个MemoryManager(MM - 也在任务之间共享)。TM之间彼此可以进行数据交换通过标准的TCP连接,这些连接在需要通信时被创建。
注意,在Flink中,是TaskManager而不是task在网络上交换数据。比如,处于同一个TM内的task,他们之间的数据交换是在一个网络连接(TaskManager创建并维护)上基于多路复用的。
ExecutionGraph: 执行图是一个包含job计算的“ground truth”的数据结构。它包含节点(ExecutionVertex,表示计算任务),以及中间结果(IntermediateResultPartition,表示任务产生的数据)。节点通过ExecutionEdge(EE)来连接到它们要消费的中间结果:
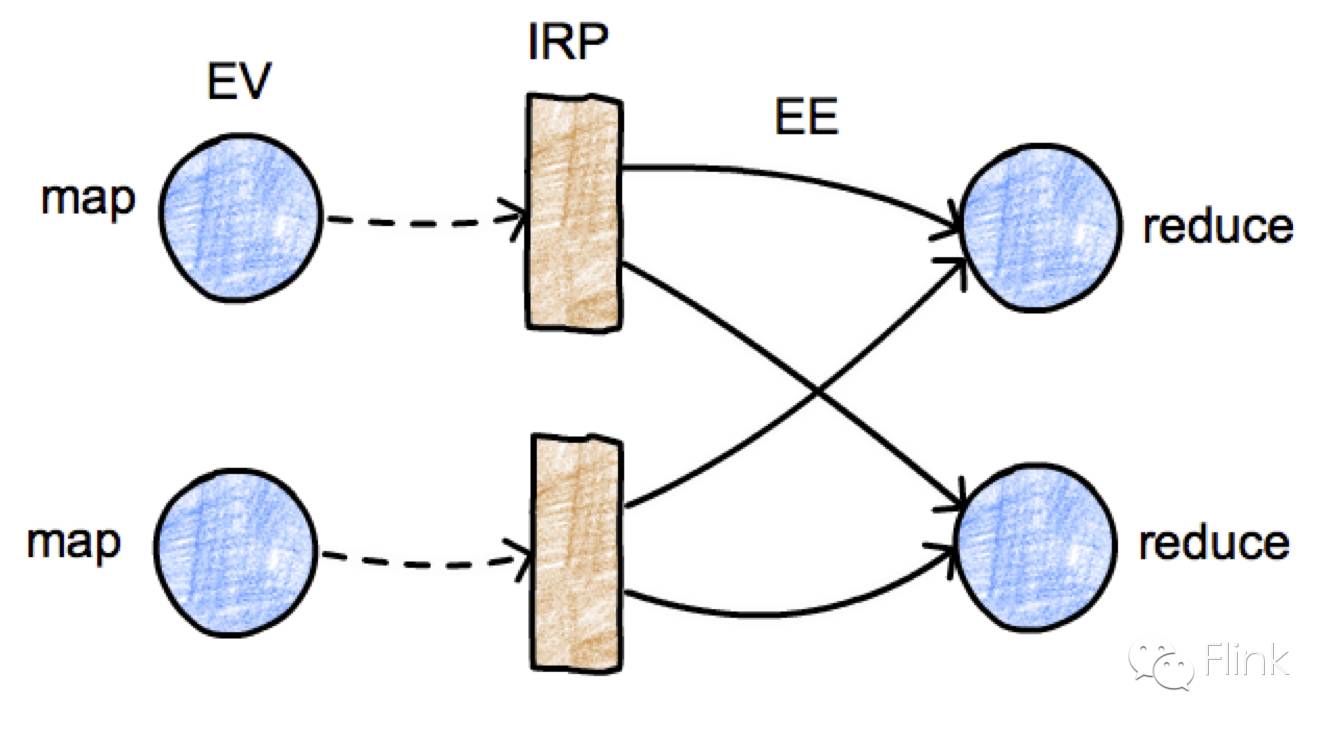
这些都是存活在JobManager中的逻辑数据结构。它们在TaskManager中存在运行时等价的数据结构,用来应对最终的数据处理。在运行时,IntermediateResultPartition的等价数据结构被称为ResultPartition。
ResultPartition(RP)表示BufferWriter写入的data chunk。一个RP是ResultSubpartition(RS)的集合。这是为了区别被不同接收者定义的数据,例如针对一个reduce或一个join的分区shuffle的场景。
ResultSubpartition(RS)表示一个operator创建的数据的一个分区,跟要传输的数据逻辑一起传输给接收operator。RS的特定的实现决定了最终的数据传输逻辑,它被设计为插件化的机制来满足系统各种各样的数据传输需求。例如,PipelinedSubpartition就是一种支持流数据交换的pipeline的实现。而SpillableSubpartition是一个支持批处理的块数据实现。
InputGate: 在接收端,逻辑上等价于RP。它用于处理并收集来自上游的buffer中的数据。
InputChannel: 在接收端,逻辑上等价于RS。用于接收某个特定的分区的数据。
Buffer: 参见memory-management
序列化器、反序列化器用于可靠得将类型化的数据转化为纯粹的二进制数据,处理跨buffer的数据。
数据交换的控制流
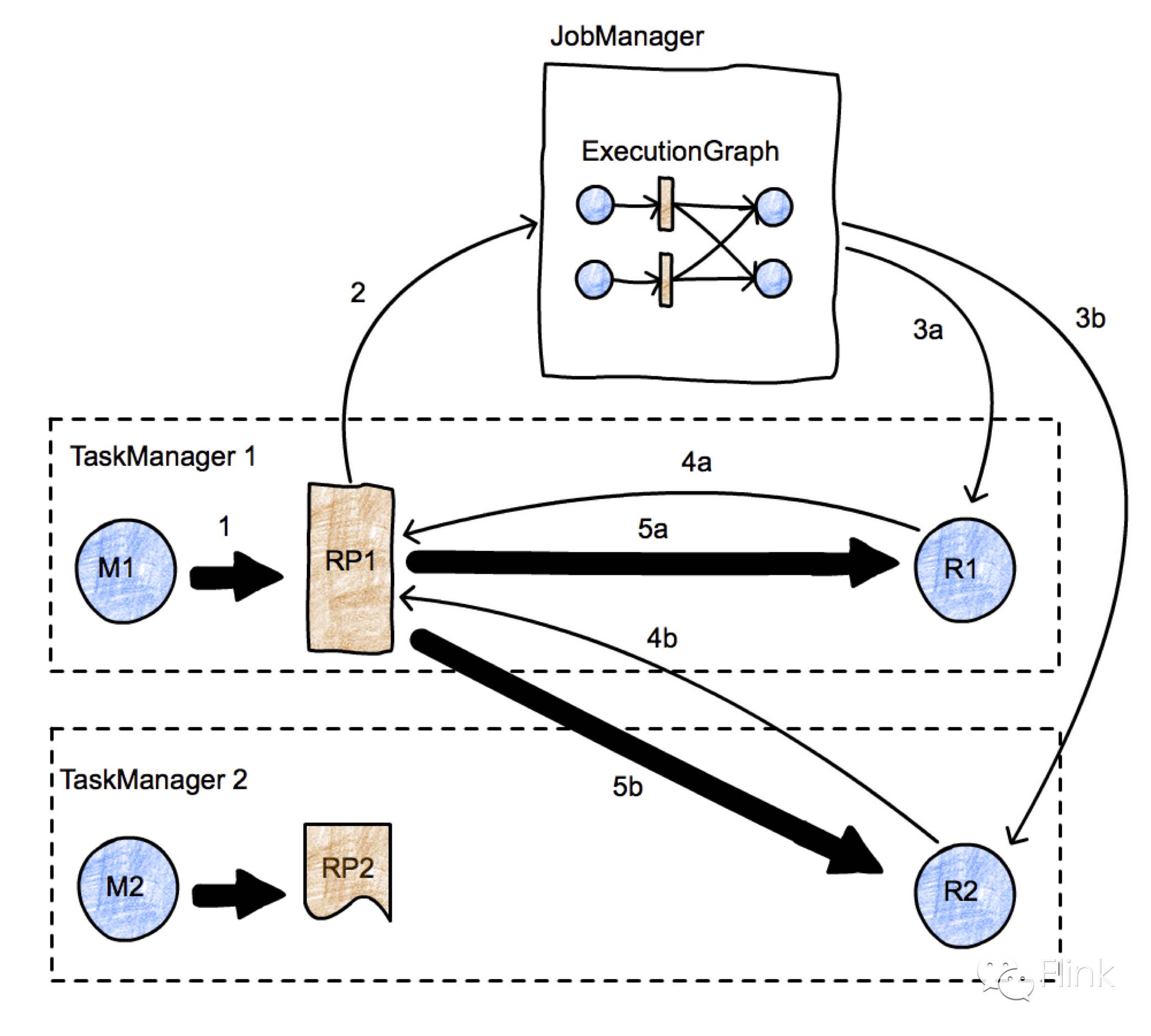
上图表示一个简单的map-reduce job并具有两个并行的task。我们有两个TaskManager,每个TaskManager都有两个task(一个map,一个reduce),这两个TaskManager运行在两个不同的节点上,有一个JobManager运行在第三方节点上。我们聚焦在task M1和R2之间的传输初始化。数据传输使用粗箭头表示,消息使用细箭头表示。首先,M1生产一个ResultPartition(RP1)(箭头1)。当RP对于消费端变得可访问(我们后面会讨论),它会通知JobManager(箭头2)。JobManager通知想要接收这个分区数据的接收者(task R1和R2)分区当前已经准备好了。如果接收者还没有被调度,这将会触发task的deployment(箭头3a,3b)。然后接收者将会向RP请求数据(箭头4a,4b)。这将会初始化任务之间的数据传输(5a,5b),这个初始化要么是本地的(5a),或者通过TaskManager的网络栈传输(5b)。这种机制给了RP在决定什么时候通知JobManager自己已经处于准备好状态的时机上拥有充分的自由度。例如,如果RP1希望在通知JM之前,等待数据完整地传输完(比如它将数据写到一个临时文件里),这种数据交换机制粗略来看等同于批处理数据交换,就像在Hadoop中实现的那样。而如果RP1一旦在其第一条记录准备好时就通知JobManager,那么我就拥有了一个流式的数据交换。
字节缓冲区在两个task之间的传输
上面这张图展示了一个更细节的过程,描述了数据从生产者传输到消费者的完整生命周期。最初,MapDriver生产数据记录(通过Collector收集),这些记录被传给RecordWriter对象。RecordWriter包含一组序列化器(RecordSerializer对象)。消费者task可能会消费这些数据。一个ChannelSelector选择一个或者多个序列化器来处理记录。如果记录在broadcast中,它们将被传递给每一个序列化器。如果记录是基于hash分区的,ChannelSelector将会计算记录的hash值,然后选择合适的序列化器。
序列化器将数据记录序列化成二进制的表示形式。然后将它们放到大小合适的buffer中(记录也可以被切割到多个buffer中)。这些buffer首先会被传递给BufferWriter,然后被写到一个ResulePartition(RP)中。一个RP包含多个subpartition(ResultSubpartition - RS),用于为特定的消费者收集buffer数据。在上图中的这个buffer是为TaskManager2中的reducer定义的,然后被放到RS2中。既然首个buffer进来了,RS2就对消费者变成可访问的状态了(注意,这个行为实现了一个streaming shuffle),然后它通知JobManager。
JobManager查找RS2的消费者,然后通知TaskManager 2一个数据块已经可以访问了。通知TM2的消息会被发送到InputChannel,该inputchannel被认为是接收这个buffer的,接着通知RS2可以初始化一个网络传输了。然后,RS2通过TM1的网络栈请求该buffer,然后双方基于netty准备进行数据传输。网络连接是在TaskManager(而非特定的task)之间长时间存在的。
一旦buffer被TM2接收,它会穿过一个类似的对象栈,起始于InputChannel(接收端 等价于IRPQ),进入InputGate(它包含多个IC),最终进入一个RecordDeserializer,它用于从buffer中还原成类型化的记录,然后将其传递给接收task,这个例子中是ReduceDriver。
本文翻译自:https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
以上是关于Flink中task之间的数据交换机制的主要内容,如果未能解决你的问题,请参考以下文章