Flink概念:编程模型上
Posted 合格的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink概念:编程模型上相关的知识,希望对你有一定的参考价值。
抽象级别
Flink 提供了三种抽象级别来开发流式/批量的数据应用。
最低层级的抽象仅仅提供了有状态的流。它通过处理函数的方式内嵌在DataStream API。它允许用户自由的处理一个或多个流,并且使用一致的容错状态。另外令用户可以注册事件时间或者处理时间回调,这允许用户程序实现复杂的计算。
实际上,大部分的应用不需要上面描述的底层抽象,而是针对Core APIS 编程,比如DataStream API(有边界的/无边界的流)以及DateSet API(有边界的数据集)。这些流畅的API为数据处理提供了常用的构建模块,比如各种各样的用户指定的转换,joins、aggregations、windows、state等等。这些API处理的数据类型在各自的编程语言中表现为“类”。
Table API是以tables为中心的描述性DSL,它可以动态的改变表(当表示流的时候)。Table API 遵循关系(广义的)模型:表有附加的schema(与关系型数据库相似),并且也提供了配套的操作,比如 select、project、join、group-by以及aggravate等等。Table API 程序明确的定义了什么逻辑操作应该被执行而不是而不是精确指定操作看起来怎么样。虽然Table API对于用户定义的各种类型是可扩展的,但是它比Core API要昂贵,然而使用起来更加简洁(编码更少)。除此之外,Table API程序在执行之前会经过一个优化器来执行优化。
Flink可以无缝的在table和DataStream/DataSet之间转换,并且允许混合使 用Table API与DataStream和DataSet APIs来编程。
SQL是Flink提供的最高层级的抽象概念,它在语法与表现力上与Table API都很像,但是呈现出来的程序跟SQL查询表达式一样。SQL抽象概念可以与Table API紧密的交互,并且可以在Table API定义的表上执行SQL查询。
程序和数据流
Flink 程序的基本构建模块是流(streams)和转换(transformations)。(注意:使用Flink的DataSet API的数据集内部也是流,后续会介绍更多。)从概念上来说,流是(可能永不停止的)源源不断的数据记录,而转换是把一个或者多个流作为输入并且生产一个或者多个输出流作为结果。
当执行的时候,Flink程序被映射成流媒体数据流(streaming dataflow),它由流和转换操作(operators)构成。每个数据流始于一个或多个 sources 并且终于一个或多个sinks。数据流类似于任意的有向无环图(DAGs)。尽管通过迭代(iteration)构念可以允许特殊形式的循环,但为了简单起见,我们将在大多数情况下忽略它。
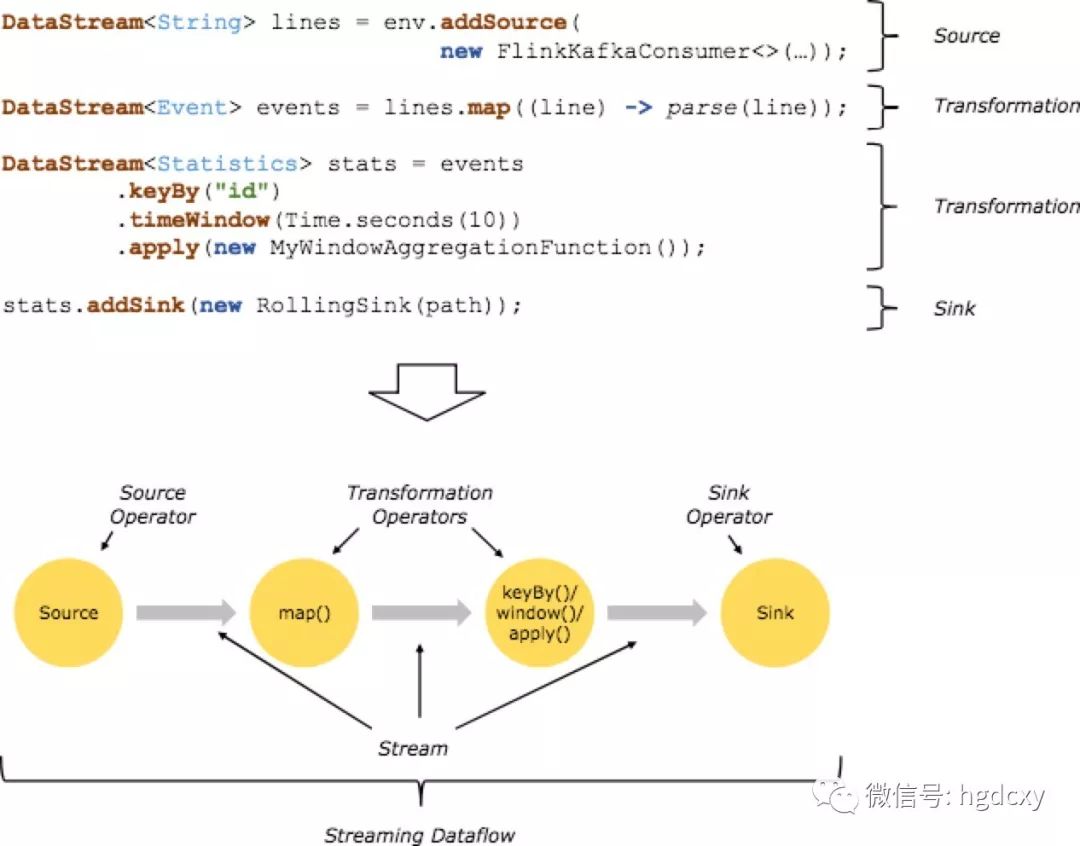
通常,程序中的转换与数据流中的操作符之间存在一对一的对应关系。然而,有时一个转换可能由多个转换操作符组成。在流连接器( streaming connectors )和批处理连接器( batch connectors)文档中记录了源和接收。在DataStream operators和DataSet transformations中记录了transformations。
并行数据流
Flink 程序内部是并行和分布式的。在执行期间,流有一个或多个流分区(stream partitions),并且每一个操作有一个或多个操作子任务(operator subtasks)。每一个操作子任务与其他的都是相互独立的,并且在不同的线程中执行,也有可能在不同的机器或者container中。
操作子任务的数量是该操作符的并行度。流的并行度总是它的生产操作符的并行度。相同程序的不痛操作符可能会有不同程度的并发。
流可以在两个操作符之间以一对一(或转发)模式或者重新分配的模式传输数据:
一对一(one-to-one)的流(比如上图中的Source和map()操作符之间)会保存元素的分区和排序。这意味着map() 操作的subtasks[1]看到的元素以及其排序与Source操作的subtasks[1]生成的数据一模一样。
重新分配(Redistributing)流(比如上面的map() 和 keyBy/window之间,或者keyBy/window 与 Sink之间)会改变流的分区。每个操作子任务(operator subtask)会发送数据道不同的目标子任务,这取决于选择的转换。例子有keyBy()(它通过对key进行hash重新分区)、broadcast()、或rebalance()(它随机的进行重新分区)。在重新分配的交换中,元素之间的顺序只在每一对发送和接收的子任务之间有保证(比如map() 的subtasks[1] 与 keyBy()/window() 的subtasks[2])。所以,在这个例子中每一个key的顺序保留下来了,但是并行性确实引入了关于不同键的聚合结果到达汇聚点(sink)的顺序的不确定性。
关于配置和控制并行性的详细信息可以在并行执行(parallel execution)的文档中找到。
相关阅读:
以上是关于Flink概念:编程模型上的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记Flink—— Flink数据流模型时间窗口和核心概念