Flink概念:编程模型下
Posted 合格的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink概念:编程模型下相关的知识,希望对你有一定的参考价值。
Window
对于流的聚合事件(如:counts、sum)的工作与批处理是不同的。例如,是不可能统计一个流的所有元素的数据量的,因为流通常是无限的(没有边界的)。取而代之地,流的聚合事件(如:counts、sum)是限制在窗口范围之内的,比如“统计最近五分钟的数量”或者“最近100个元素的和”。
窗口可以是时间驱动(比如:每30秒)或者数据驱动(比如:每100个元素)。通常有区分出几种不同类型的窗口,比如tumbling windows(没有重复)、sliding windows (有重复)以及session windows(中间有不活跃的间隙)。
更多window的例子,可以参考这边博客(https://flink.apache.org/news/2015/12/04/Introducing-windows.html)。更多细节可以参考 window docs(https://flink.apache.org/news/2015/12/04/Introducing-windows.html)。
Time
在流式程序中涉及到时间的时候(比如定义窗口),将会涉及到三种不同的时间概念:
Event Time 是一个事件创建的时间。它通常在事件中以时间戳的形式来描述,比如被传感器或者生产服务添加上去的。Flink 通过timestamp assigners(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/event_timestamps_watermarks.html)来访问时间。
Ingestion time 是事件在source操作中进入到Flink数据流中的时间。
Ingestion time 是执行基于时间操作的操作器的本地时间。
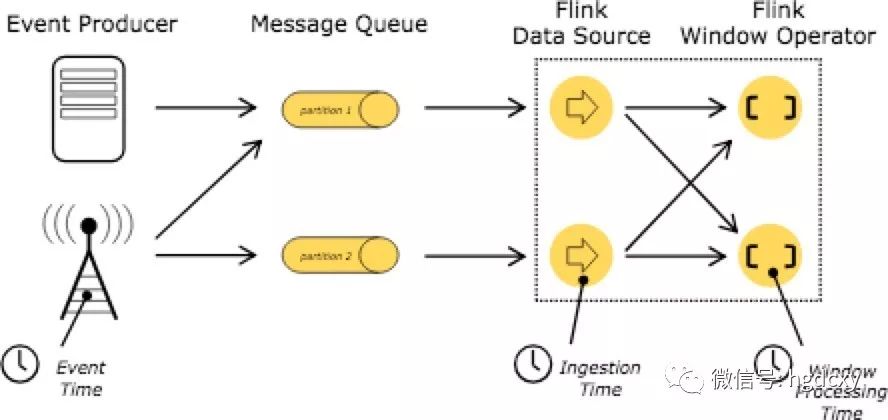
更多关于如何处理时间的细节在event time docs(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/event_time.html)。
Stateful Operations
在一个数据流中有很多操作在某个时间仅仅查看一个独立的事件(比如事件解析器),但是有些操作会记住多个操作的信息(比如窗口操作)。这些操作被称作有状态的。
这些有状态的操作符的状态是保存在可以认为是一个内嵌的key/value存储器中。状态与被有状态的操作符的读取的流是严格地分区和分布式的。因此,只有在 keyBy() 函数以后, keyed streams 才能访问 key/value 状态,但是只能访问当前事件key相关的值。调整流的键以及状态确保了所有的状态更新是本地操作,这保证了一致性而没有事务开销。这个调整可以让Flink很容易地重新分配留的状态和调整流的分区。
更多信息,可以查看State的文档(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/stream/state/index.html)
检查点的容错
Flink结合流重播(stream replay)和检查点来实现容错。检查点与每个输入流特定的点以及每个操作符对应的状态相关。通过从检查点恢复操作符的状态以及重新执行事件,可以使流式的数据流可以从检查点开始重新执行,以保持一致性(exactly-once 处理语义)。
检查点的间隔是一种平衡执行期间容错性开销和恢复时间的方式(需要重新执行的事件的数量)。
fault tolerance internals(https://ci.apache.org/projects/flink/flink-docs-release-1.5/internals/stream_checkpointing.html) 的描述中提供了更多关于Flink管理检查点的信息以及相关的话题。更多关于配置检查点的细节在 checkpointing API docs(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/stream/state/checkpointing.html)中。
批处理流媒体
Flink把其看成流式程序的一种特殊场景来执行批处理程序。这时候流是有边界的(有限的元素数量)。DataSet 内部是当做数据流来对待的。 因此,上述概念同样适用于批处理程序以及流处理程序,只有一些小的例外:
批处理的容错性(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/batch/fault_tolerance.html)不使用检查点。通过重新执行全部的流来进行恢复。这大概是由于输入是有限的吧。这使恢复的成本消耗更多,但是让常规的执行更加简单,因为它避免了检查点。
在DataSet API中有状态的操作使用简化的in-memory/out-of-core 数据结构,而不是key/value 索引。
DataSet API 介绍了特定的同步的(基于时序图的)操作,这仅仅在有限的流中才有可能。更多细节,请查看iteration 文档(https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/batch/iterations.html)。
相关阅读:
以上是关于Flink概念:编程模型下的主要内容,如果未能解决你的问题,请参考以下文章