FlinkWhat is Apache Flink?
Posted HouseOfWisdom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkWhat is Apache Flink?相关的知识,希望对你有一定的参考价值。

Apache Flink是一个分布式的框架和计算引擎,针对有边界和无边界的( unbounded and bounded)流数据进行状态计算。Flink的设计使得它可以运行在常见的集群环境上,同时可以达到与内存计算相同的速度,并支持进行任何规模的计算(即流式处理和批处理)。
这里我们介绍几个重要Flink架构中几个重要的概念:
Process Unbounded and Bounded Data
任何类型的数据都是作为事件流(Stream of events)产生的,例如:信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互,这些数据都是以流的形式生成的。
数据可以分为无边流(UNbounded)和有边界流(bounded streams)。
Unbounded streams:有起始点但是没有定义明确的结束点。在数据生成过程中,不会被终止。Unbounded streams必须连续的处理,也就是说,事件被捕捉到之后必须被尽快的处理掉。因为数据是无边界的,且一直都在生产并被捕获,不会有完成的时间点,所以不可能等待所有输入数据到达。在处理unbounded 数据时通常需要以特定的顺序处理事件,例如,时间的发生顺序,以便对时间的完整性进行推测。
Bounded Stream:有明确的开始和结束。有边界数据流可以先捕获所有的数据之后再执行计算。在处理bounded数据时,由于bounded数据总是可以被排序的,所以不需要顺序捕获时间。有界流的处理也称为批处理。
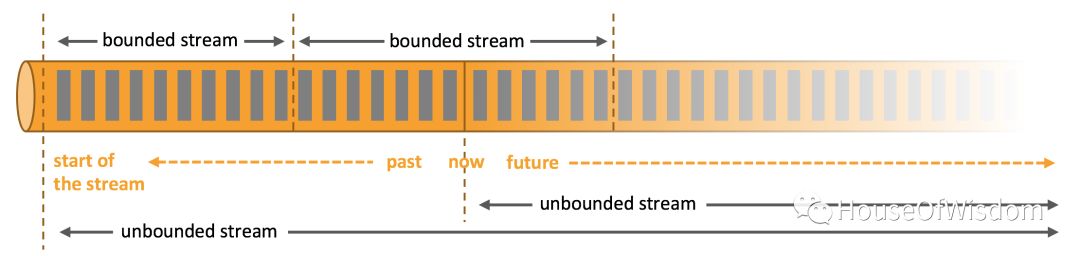
Apache Flink对bounded data和unbounded data的处理都擅长。 对时间和状态的精确控制使得Flink支持对unbounded stream的任何类型数据的处理。使用为固定大小的数据集特别设计的算法和数据结构来处理Bounded stream,以达到更好的性能。
Deploy Applications Anywhere
Apache Flink是一个分布式的系统,且需要计算资源才可以便执行应用程序。Flink与常用的集群资源管理器可以很好的结合,如Hadoop YARN,Apache Mesos,以及Kubernetes,同时也可以设置作为独立的集群运行。
Flink在前面列出的资源管理器(Hadoop YARN,Apache Mesos,以及Kubernetes)上都可以很好的运行。之所以可以实现这样的效果是因为Flink本身特殊的资源管理器模型使得Flink得以与其他资源管理器流畅交互。
当开发Flink应用时,Flink会基于应用的并行设置和需求,自动确定需要向资源管理器申请的资源的大小。如果失败,Flink会请求新的资源来替换失败的container。所有提交任务和控制应用的信息交互都是基于REST调用实现的。这使得Flink在许多环境中的集成得到很大的简化。
Run Applications at any Scale
Flink的设计适用于任何规模的有状态的流应用。应用程序被并行化为上千个task并且分布在集群中并发执行。因此,一个应用程序可以使用几乎无限的CPUs,内存,磁盘和网络IO。此外,Flink对保持非常大的应用状态也可以很好的支持。它的异步增量检查点算法确保计算的延迟最小,同时保证可 exactly-once状态的一致性。
用户报告了在生产环境中运行的Flink应用程序是令人印象深刻的一些数字,例如:
每天应用处理数以万亿的数据;
应用维护这几个TB的状态;
应用运行在近千个内核上。
Leverage In-Memory Performance
有状态的Flink应用程序针对本地(local state access)状态进行了优化。任务状态维护在内存中,如果状态大小超过了可用内存,会存储到磁盘上一种存取高效的数据结构中。因此,task执行所有的计算时通过访问本地状态(通常是内存中的状态)使得处理的延迟很低。Flink通过定期和异步检查本地状态并持久化存储,从而保证了在发生事故时 exactly-once状态一致性。
未完待续
图/来源Adobe Stock images
文/翻译
一
只
程序猿
我是雨钓
一只被硅基虫子调戏的
碳基猿
文章来源:https://flink.apache.org/flink-architecture.html
以上是关于FlinkWhat is Apache Flink?的主要内容,如果未能解决你的问题,请参考以下文章
Flink实战系列Sort on a non-time-attribute field is not supported
Flink实战系列Sort on a non-time-attribute field is not supported
Flink producer attempted to use a producer id which is not currently assigned to its transaction(代码片
ByteArraySerializer is not an instance of org.apache.kafka.common.serialization.Serializer