最全的Flink部署及开发案例(KafkaSource+SinkToMySQL)
Posted 若泽大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最全的Flink部署及开发案例(KafkaSource+SinkToMySQL)相关的知识,希望对你有一定的参考价值。
领取工程源代码
1.下载Flink安装包
https://archive.apache.org/dist/flink/flink-1.5.0/
因为例子不需要hadoop,下载flink-1.5.0-bin-scala_2.11.tgz即可
上传至机器的/opt目录下
2.解压
tar -zxf flink-1.5.0-bin-scala_2.11.tgz -C ../opt/
3.配置master节点
选择一个 master节点(JobManager)然后在conf/flink-conf.yaml中设置jobmanager.rpc.address 配置项为该节点的IP 或者主机名。确保所有节点有有一样的jobmanager.rpc.address 配置。
jobmanager.rpc.address: node1
(配置端口如果被占用也要改 如默认8080已经被spark占用,改成了8088)
rest.port: 8088
本次安装 master节点为node1,因为单机,slave节点也为node1
4.配置slaves
将所有的 worker 节点 (TaskManager)的IP 或者主机名(一行一个)填入conf/slaves 文件中。
5.启动flink集群
bin/start-cluster.sh
打开 http://node1:8088 查看web页面
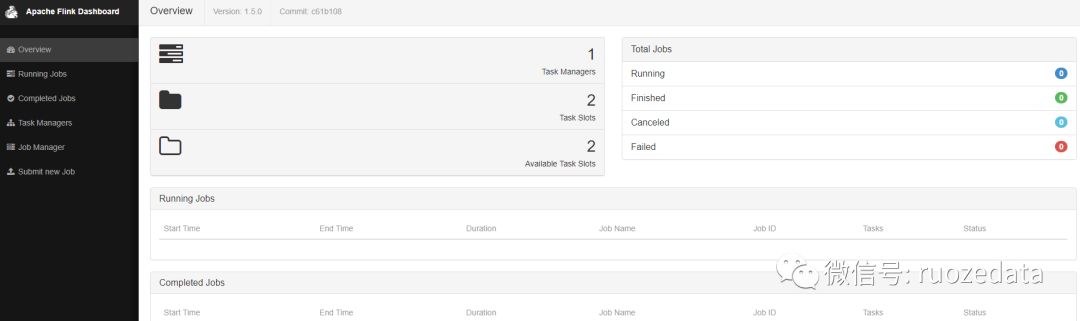
Task Managers代表当前的flink只有一个节点,每个task还有两个slots
6.测试
依赖
<groupId>com.rz.flinkdemo</groupId>
<artifactId>Flink-programe</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.binary.version>2.11</scala.binary.version>
<flink.version>1.5.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.11</artifactId>
<version>1.5.0</version>
</dependency>
</dependencies>7.Socket测试代码
public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the port to connect to
final int port; final String hostName; try { final ParameterTool params = ParameterTool.fromArgs(args);
port = params.getInt("port");
hostName = params.get("hostname");
} catch (Exception e) {
System.err.println("No port or hostname specified. Please run 'SocketWindowWordCount --port <port> --hostname <hostname>'"); return;
} // get the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // get input data by connecting to the socket
DataStream<String> text = env.socketTextStream(hostName, port, "
"); // parse the data, group it, window it, and aggregate the counts
DataStream<WordWithCount> windowCounts = text
.flatMap(new FlatMapFunction<String, WordWithCount>() { public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction<WordWithCount>() { public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count);
}
}); // print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
} // Data type for words with count
public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count;
} @Override
public String toString() { return word + " : " + count;
}
}
}打包mvn clean install (如果打包过程中报错java.lang.OutOfMemoryError)
在命令行set MAVEN_OPTS= -Xms128m -Xmx512m
继续执行mvn clean install
生成FlinkTest.jar
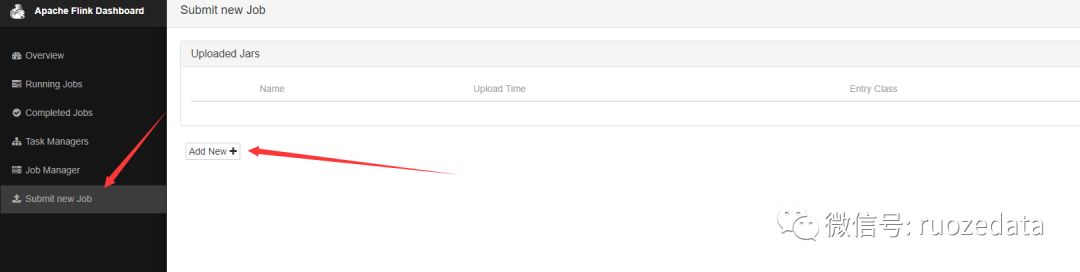
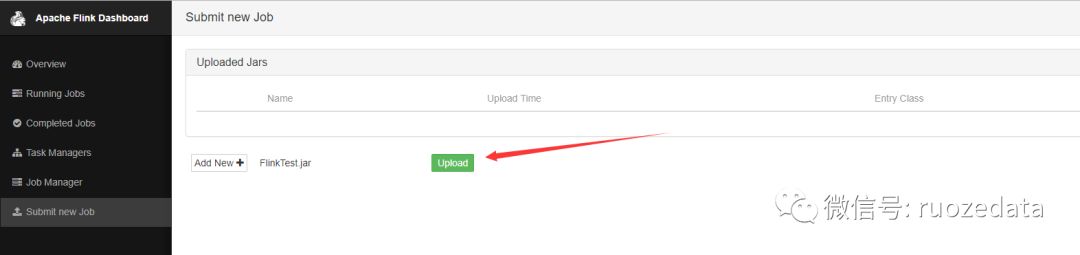
找到打成的jar,并upload,开始上传
运行参数介绍
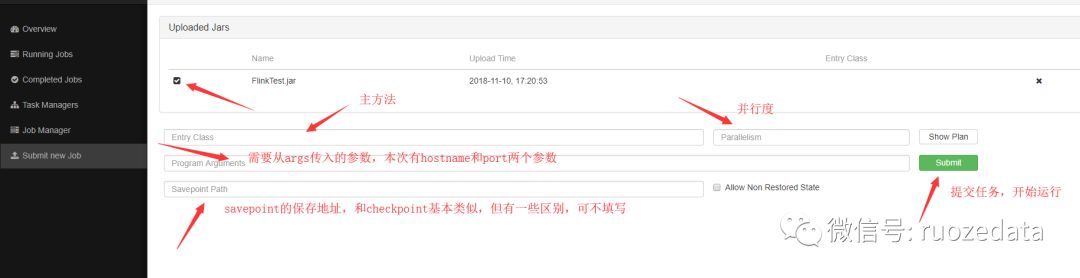
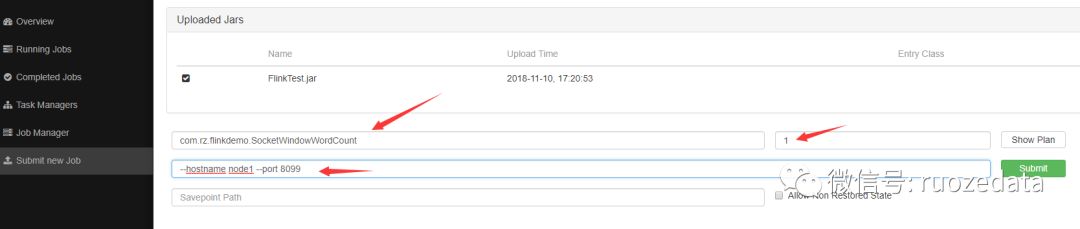
提交结束之后去overview界面看,可以看到,可用的slots变成了一个,因为我们的socket程序占用了一个,正在running的job变成了一个
发送数据
[root@localhost flink-1.5.0]# nc -l 8099
aaa bbb
aaa ccc
aaa bbb
bbb ccc点开running的job,你可以看见接收的字节数等信息
到log目录下可以清楚的看见输出
[root@localhost log]# tail -f flink-root-taskexecutor-2-localhost.out
aaa : 1
ccc : 1
ccc : 1
bbb : 1
ccc : 1
bbb : 1
bbb : 1
ccc : 1
bbb : 1
ccc : 1除了可以在界面提交,还可以将jar上传的linux中进行提交任务
运行flink上传的jar
bin/flink run -c com.rz.flinkdemo.SocketWindowWordCount jars/FlinkTest.jar --port 8099 --hostname node1其他步骤一致。
8.使用kafka作为source
加上依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.5.0</version></dependency>public class KakfaSource010 { public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","node1:9092");
properties.setProperty("group.id","test"); //DataStream<String> test = env.addSource(new FlinkKafkaConsumer010<String>("topic", new SimpleStringSchema(), properties));
//可以通过正则表达式来匹配合适的topic
FlinkKafkaConsumer010<String> kafkaSource = new FlinkKafkaConsumer010<>(java.util.regex.Pattern.compile("test-[0-9]"), new SimpleStringSchema(), properties); //配置从最新的地方开始消费
kafkaSource.setStartFromLatest(); //使用addsource,将kafka的输入转变为datastream
DataStream<String> consume = env.addSource(wordfre);
... //process and sink
env.execute("KakfaSource010");
}
}9.使用mysql作为sink
flink本身并没有提供datastream输出到mysql,需要我们自己去实现
首先,导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency>自定义sink,首先想到的是extends SinkFunction,集成flink自带的sinkfunction,再当中实现方法,实现如下
public class MysqlSink implements SinkFunction<Tuple2<String,String>> { private static final long serialVersionUID = 1L; private Connection connection; private PreparedStatement preparedStatement;
String username = "mysql.user";
String password = "mysql.password";
String drivername = "mysql.driver";
String dburl = "mysql.url"; @Override
public void invoke(Tuple2<String,String> value) throws Exception {
Class.forName(drivername);
connection = DriverManager.getConnection(dburl, username, password);
String sql = "insert into table(name,nickname) values(?,?)";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, value.f0);
preparedStatement.setString(2, value.f1);
preparedStatement.executeUpdate(); if (preparedStatement != null) {
preparedStatement.close();
} if (connection != null) {
connection.close();
}
}
}这样实现有个问题,每一条数据,都要打开mysql连接,再关闭,比较耗时,这个可以使用flink中比较好的Rich方式来实现,代码如下
public class MysqlSink extends RichSinkFunction<Tuple2<String,String>> { private Connection connection = null; private PreparedStatement preparedStatement = null; private String userName = null; private String password = null; private String driverName = null; private String DBUrl = null; public MysqlSink() {
userName = "mysql.username";
password = "mysql.password";
driverName = "mysql.driverName";
DBUrl = "mysql.DBUrl";
} public void invoke(Tuple2<String,String> value) throws Exception { if(connection==null){
Class.forName(driverName);
connection = DriverManager.getConnection(DBUrl, userName, password);
}
String sql ="insert into table(name,nickname) values(?,?)";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,value.f0);
preparedStatement.setString(2,value.f1);
preparedStatement.executeUpdate();//返回成功的话就是一个,否则就是0
} @Override
public void open(Configuration parameters) throws Exception {
Class.forName(driverName);
connection = DriverManager.getConnection(DBUrl, userName, password);
} @Override
public void close() throws Exception { if(preparedStatement!=null){
preparedStatement.close();
} if(connection!=null){
connection.close();
}
}
}Rich方式的优点在于,有个open和close方法,在初始化的时候建立一次连接,之后一直使用这个连接即可,缩短建立和关闭连接的时间,也可以使用连接池实现,这里只是提供这样一种思路。
使用这个mysqlsink也非常简单
//直接addsink,即可输出到自定义的mysql中,也可以将mysql的字段等写成可配置的,更加方便和通用proceDataStream.addSink(new MysqlSink());10.总结
本次的笔记做了简单的部署、测试、kafkademo,以及自定义实现mysqlsink的一些内容,其中比较重要的是Rich的使用,希望大家能有所收获。
本文是高级班3期Flink老师(我是谁)所写,非常赞。
欢迎有什么不懂的,可以留言私信交流。
获取源代码,看文章顶部。
回归原创文章:
以上是关于最全的Flink部署及开发案例(KafkaSource+SinkToMySQL)的主要内容,如果未能解决你的问题,请参考以下文章
2021年最新最全Flink系列教程_Flink快速入门(概述,安装部署)(建议收藏!!)