Flink为何会在众多大数据框架中脱颖而出
Posted ItStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink为何会在众多大数据框架中脱颖而出相关的知识,希望对你有一定的参考价值。
大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。
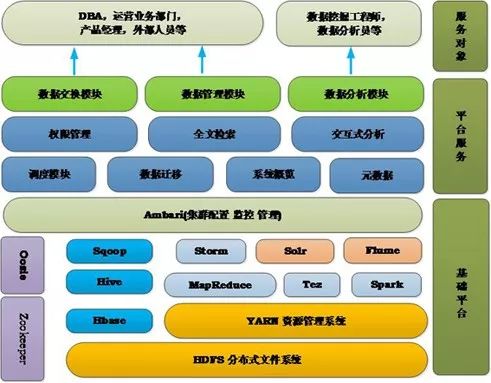
大数据处理框架
处理框架和处理引擎负责对数据系统中的数据进行计算。虽然“引擎”和“框架”之间的区别没有什么权威的定义,但大部分时候可以将前者定义为实际负责处理数据操作的组件,后者则可定义为承担类似作用的一系列组件。
那么在众多的大数据框架中,Flink、Hadoop和Apache Spark为何会脱颖而出。
首要,Hadoop和Apache Spark两者都是大数据结构,可是各自存在的意图不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将无穷的数据集分派到一个由一般计算机构成的集群中的多个节点进行存储,意味着您不需要采购和保护昂贵的服务器硬件。
Spark是一种包含流处理手法的下一代批处理框架。与Hadoop的MapReduce引擎依据各种一样原则开发而来的Spark首要侧重于经过完善的内存计算和处理优化机制加速批处理工作负载的工作速度。
Spark可作为独立集群安置(需要相应存储层的协作),或可与Hadoop集成并替代MapReduce引擎。
Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。
这种流处理为先的方法也叫做Kappa架构,与之相对的是更加被广为人知的Lambda架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa架构中会对一切进行流处理,借此对模型进行简化,而这一切是在最近流处理引擎逐渐成熟后才可行的。
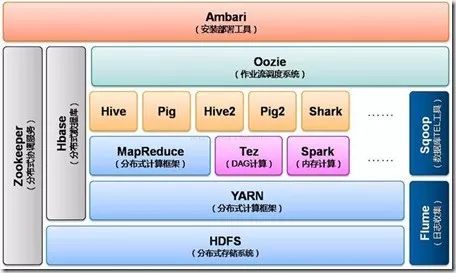
Hadoop多线程模型
每个Task运行在一个独立的JVM中运行,可单独为不同类型的task设置不同的资源量,目前支持内存和CPU两种资源
spark多线程模型
每个节点上可以运行一个或者多个Executr,一旦启用将一直运行。
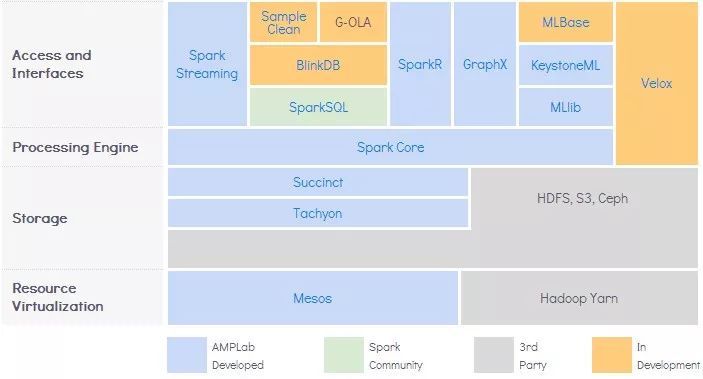
Spark多线程模型
运用Spark而非Hadoop MapReduce的首要原因是速度。在内存核算战略和先进的DAG调度等机制的协助下,Spark能够用更快速度处理一样的数据集。
Spark的另一个主要优势在于多样性。该商品可作为独立集群布置,或与现有Hadoop集群集成。该商品可运转批处理和流处理,运转一个集群即可处理不一样类型的使命。
除了引擎本身的能力外,围绕Spark还建立了包括各种库的生态系统,可为机器学习、交互式查询等使命供给十分好的支撑。
Spark是多元化作业负载处理使命的最好挑选。Spark批处理才能以更高内存占用为价值供给了无与伦比的速度优势。关于注重吞吐率而非推迟的作业负载,则对比合适运用Spark Streaming作为流处理解决方案。
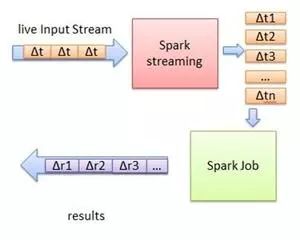
Flink流处理模型
Flink的流处理模型在处理传入数据时会将每一项视作真正的数据流。Flink提供的DataStream API可用于处理无尽的数据流。Flink可配合使用的基本组件包括:
· Stream(流)是指在系统中流转的,永恒不变的无边界数据集
· Operator(操作方)是指针对数据流执行操作以产生其他数据流的功能
· Source(源)是指数据流进入系统的入口点
· Sink(槽)是指数据流离开Flink系统后进入到的位置,槽可以是数据库或到其他系统的连接器
为了在计算过程中遇到问题后能够恢复,流处理任务会在预定时间点创建快照。为了实现状态存储,Flink可配合多种状态后端系统使用,具体取决于所需实现的复杂度和持久性级别。
此外Flink的流处理能力还可以理解“事件时间”这一概念,这是指事件实际发生的时间,此外该功能还可以处理会话。这意味着可以通过某种有趣的方式确保执行顺序和分组。
Flink批处理模型
Flink的批处理模型在很大程度上仅仅是对流处理模型的扩展。此时模型不再从持续流中读取数据,而是从持久存储中以流的形式读取有边界的数据集。Flink会对这些处理模型使用完全相同的运行时。
Flink可以对批处理工作负载实现一定的优化。例如由于批处理操作可通过持久存储加以支持,Flink可以不对批处理工作负载创建快照。数据依然可以恢复,但常规处理操作可以执行得更快。
另一个优化是对批处理任务进行分解,这样即可在需要的时候调用不同阶段和组件。借此Flink可以与集群的其他用户更好地共存。对任务提前进行分析使得Flink可以查看需要执行的所有操作、数据集的大小,以及下游需要执行的操作步骤,借此实现进一步的优化。
提醒大家,不管是Hadoop、Apache Spark还是Flink在潭州大数据学院小伙伴都可以学到,不止如此,大家还可以在学习期间考取阿里的相关证书,以此来增加自己的竞争优势,观望永远不如实践来的有意义!
猜你喜欢
以上是关于Flink为何会在众多大数据框架中脱颖而出的主要内容,如果未能解决你的问题,请参考以下文章