第一次有人把Apache Flink说的这么明白!
Posted 大数据技术汇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次有人把Apache Flink说的这么明白!相关的知识,希望对你有一定的参考价值。
Apache Flink(以下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注。本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解,对其他大数据系统开发者也能有所裨益。本文假设读者已对MapReduce、Spark及Storm等大数据处理框架有所了解,同时熟悉流处理与批处理的基本概念。
Flink简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
为什么选择 Flink?
Flink 是一个开源的分布式流式处理框架:
①提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
②它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
③大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
更早的时候,我们讨论了数据集类型(有界 vs 无穷)和运算模型(批处理 vs 流式)的匹配。Flink 的流式计算模型启用了很多功能特性,如状态管理,处理无序数据,灵活的视窗,这些功能对于得出无穷数据集的精确结果是很重要的。
除了提供数据驱动的视窗外,Flink还支持基于时间,计数,session等的灵活视窗。视窗能够灵活的触发条件定制化从而达到对复杂的流传输模式的支持。Flink的视窗使得模拟真实的创建数据的环境成为可能。
Flink的容错能力事轻量级的,允许系统提供高并发,同时在同一时间提供强一致性保证。Flink以零数据丢失的方式从故障中恢复,但没有考虑可靠性和延迟之间的折中。
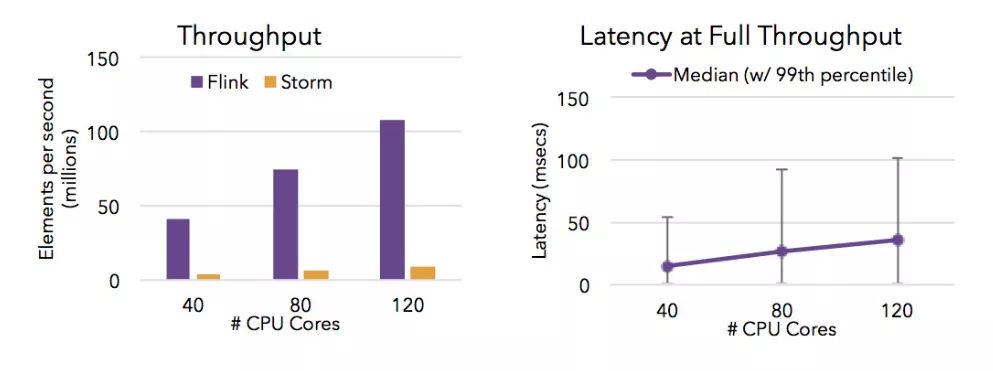
Flink可以满足高并发和低延迟(计算大量数据很快)。下图显示了Apache Flink与Apache Storm在完成流数据清晰的分布式的性能对比
Flink保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短时间的停机方式更新应用和回退历史数据。
Flink被设计成用上千个点在大规模集群上运行。除了支持独立集群部署外,Flink还支持YARN和Me'sos方式部署。
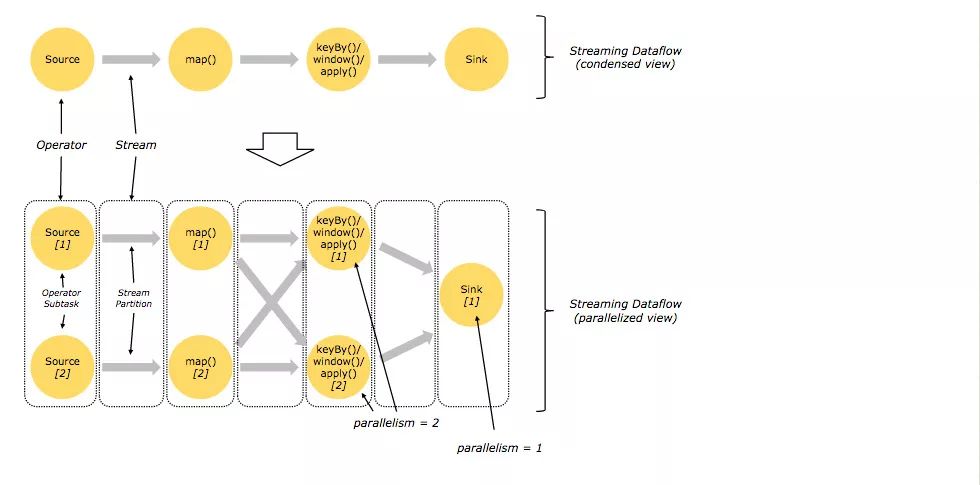
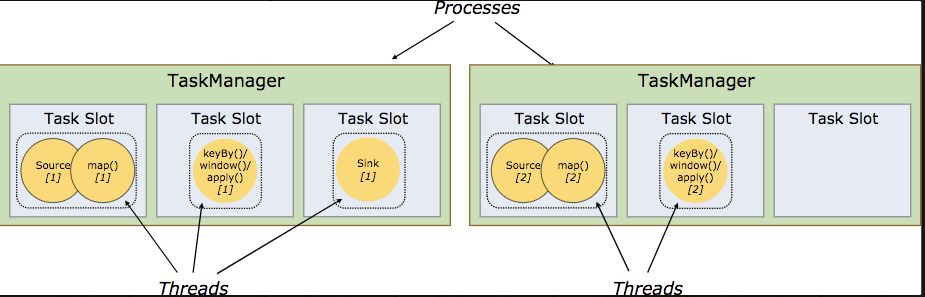
Flink的程序内在事并行和分布式的,数据流可以被分区成stram partitions,operators被划分为operator subtasks;这些subtasks在不同的机器火容器中分不同的西城独立运行;operator subtasks的数量在具体的operator就是并行计算数,程序不同的operator 阶段可能有不同的并行数;如下图所示,source operator 的并行书为2,但是最后的sink operator 为1;
分布式运行
flink 作业提交架构流程可见下图:
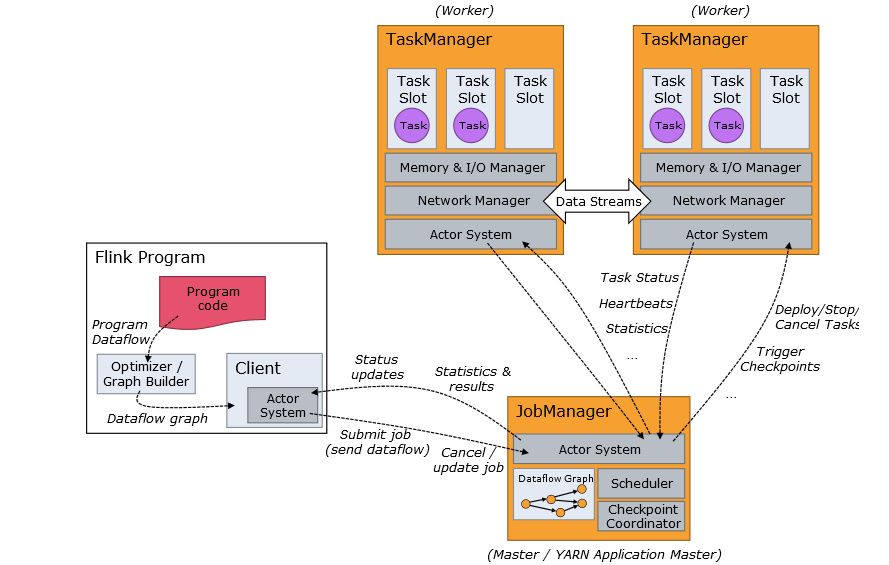
1、Program Code:我们编写的 Flink 应用程序代码
2、Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
、Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件
4、Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
最后
以上是关于第一次有人把Apache Flink说的这么明白!的主要内容,如果未能解决你的问题,请参考以下文章