第一次有人把HashMap的hash快速生成方法这么详细~
Posted Java架构没有996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次有人把HashMap的hash快速生成方法这么详细~相关的知识,希望对你有一定的参考价值。
第一次有人把HashMap的hash快速生成方法这么详细~
明人不说暗话~直接开干
解析hash的源码
static final int hash(Object key) {
int h;
return key==null? 0: (h=key.hashCode())^h>>>16;
// key.hashCode()是对象的hashcode,任何对象类都有自定义的hashcode
// ^h 异或操作:两个位相同为0,相异为1;>>> 无符号右移:忽略符号位,空位都以0补齐
// 注意>>> 优先级高于^,所以写成(h=key.hashCode())^(h>>>16)更容易理解
}
以下图为例,展示对一个32位的int整型做hash计算过程:
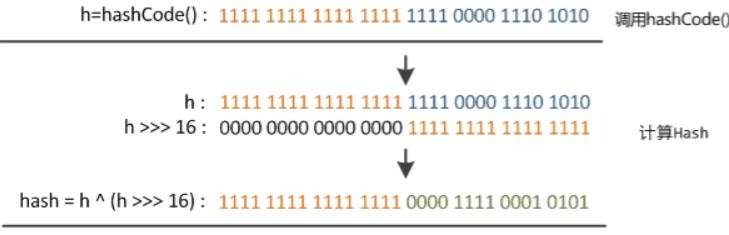
源码中对hashcode的再处理称之为“扰动函数”。
无符号右移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大随机性。
为什么使用扰动函数
【参考】:写在前面:我没在源码里找到indexFor。
理论上散列值是一个int型,如果直接拿散列值作为下标访问hashmap主数组的话,考虑2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
但是一个40亿长度的数组,内存是放不下的。所以源码中用indexFor函数将哈希码对数组的长度取模运算,得到的余数才能用来访问数组下标。
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
return h&(length-1);
}
indexFor以下为例说明:
bucketIndex = indexFor(hash, table.length);
到这里问题就是,就算散列值分步再松散,要是只取最后几位,碰撞也很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,会恰好使最后几个低位呈现规律性重复。【参考文献】
所以就引入了“扰动函数”来加大哈希码的随机性。
Java运算符优先级
| 优先级 | 运算符 | 结合性 |
|---|---|---|
| 1 | () [] . | 从左到右 |
| 2 | ! +(正) -(负) ~ ++ – | 从右向左 |
| 3 | * / % | 从左向右 |
| 4 | +(加) -(减) | 从左向右 |
| 5 | << >> >>> | 从左向右 |
| 6 | < <= > >= instanceof | 从左向右 |
| 7 | == != | 从左向右 |
| 8 | &(按位与) | 从左向右 |
| 9 | ^ | 从左向右 |
| 10 | | | 从左向右 |
| 11 | && | 从左向右 |
| 12 | || | 从左向右 |
| 13 | ?: | 从右向左 |
| 14 | = += -= *= /= %= &= |= ^= ~= <<= >>= >>>= | 从右向左 |


以上是关于第一次有人把HashMap的hash快速生成方法这么详细~的主要内容,如果未能解决你的问题,请参考以下文章