Flink CookBook—流式计算介绍
Posted data之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink CookBook—流式计算介绍相关的知识,希望对你有一定的参考价值。
在大数据时代,流式计算越来越发挥着巨大的商业价值:业务分析人员能够更及时洞察数据,辅助做出更有效的决策;在万物互联场景中,对海量无限数据集的处理成了常态化,使用流式系统更能满足现代数据的商业模型;在数据到达时就处理数据,可以更均衡的负载计算负荷。
在开篇前我们先聊聊和流式计算有关的概念,让大家对流计算有整体上的认识、相关术语有清晰的了解、流式计算在大数据架构里的定位。
一、背景知识

流式计算是在无限数据集上设计的一种计算引擎,像批处理一样,可以产生正确的、一致性的、可回放的结果集。这里介绍下和流计算相关的一些术语。
1.1 数据流
不管什么类型的数据从本质上看都是以流的方式产生的,包括交易数据、日志数据、用户交互数据、物联网数据等。数据集从基数大小、消费情况上可以概括的分为两类:
有界数据集:数据集大小是有限的,数据范围有明确的开始和结束边界,因此可以在处理数据时获取到所有数据。对有界数据集的处理称之为批处理,这也是最常见的一种数据处理方式.
无界数据集:数据集大小是无限的,数据范围只有开始、没有结束。因为数据的产生是源源不断、无止境的,所以我们不可能等到所有数据到达后才处理数据,而是数据达到后就及时处理,即连续的处理数据流,这种数据处理方式就是流式处理.
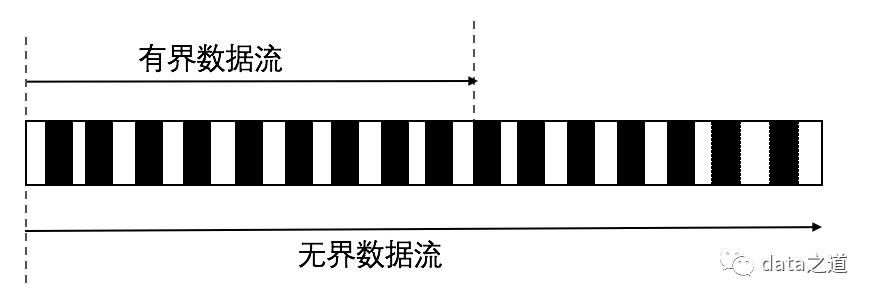
无界数据流更符合现实数据的产生方式,可以把有界数据流当做无界数据流的一个特例、一个子集.
1.2 时间域
处理时间:数据进入处理引擎并被程序处理的时间
摄取时间:事件到达处理引擎的时间时的时间
事件时间:数据流事件本身携带的时间,即事件真实的发生时间
在理想的状态下,三个时间是相同的:数据产生时就进入到处理系统并被及时处理。但现实世界有很多影响因素,比如网络、硬件资源、数据源的吞吐量以及计算平台本身的性能,三者之间会有差别,而且这个差值还是不确定的。
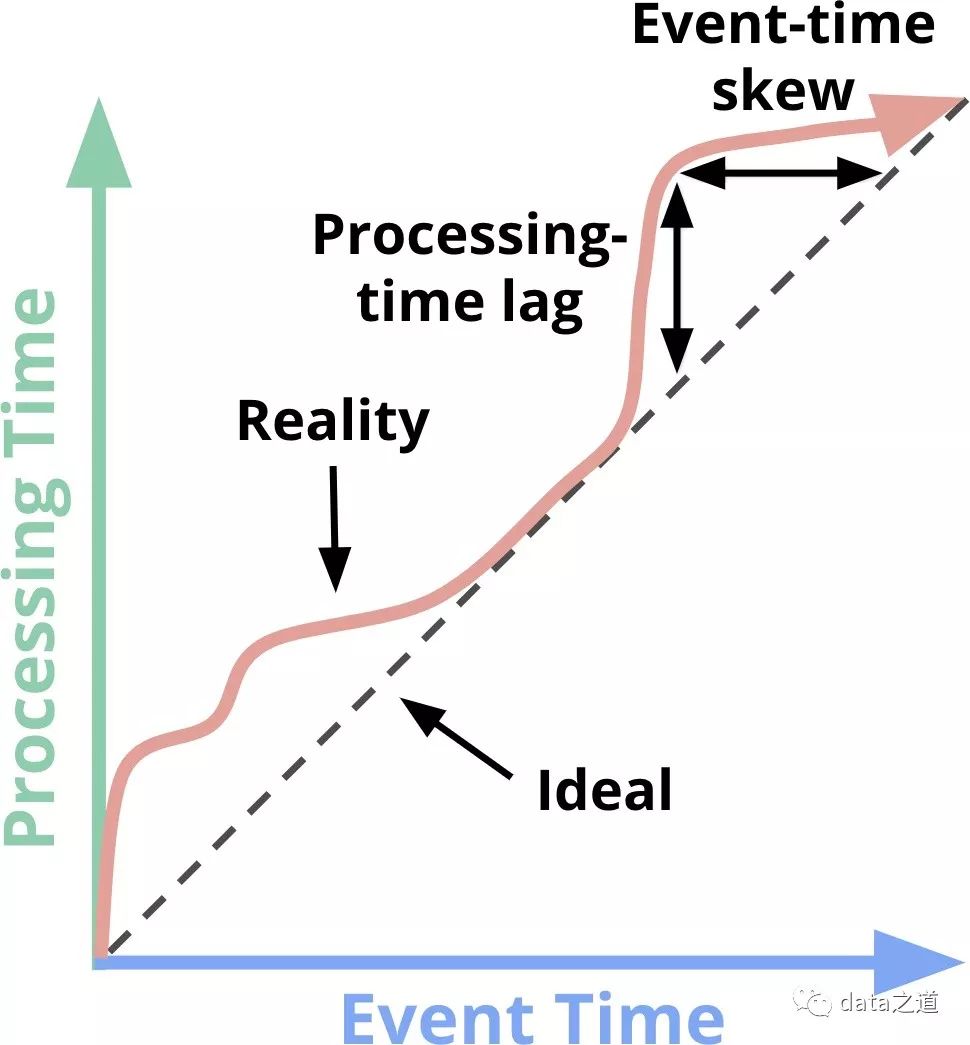
处理时间和事件时间在实际场景下的关系
如果对计算结果的准确性要求很高、对事件实际发生时间比较敏感,就要考虑用事件时间.使用处理时间保证了高性能和低延迟,但结果往往是不确定性的(当分析事件发生的状态时)。
1.3 窗口分类
窗口是应用程序获取数据的一种方式,它沿着时间线将数据流(不管是有限数据流还是无限数据流)切割成块,然后再在块之上进行处理。可将时间窗口当作切分数据的单位,同一时间窗口内的数据作为一个批次统一处理,将流式处理转换成批处理了。
滚动窗口:根据固定时间长度把数据流切割成相同时间长度的窗口;在滚动窗口中,窗口之间不重叠,事件不会同时属于两个窗口
滑动窗口:是滚动窗口的一般化形式。滑动窗口有两个属性:窗口长度和窗口步长,如果窗口步长小于窗口长度,窗口之间就会重叠;如果窗口步长等于窗口长度,就变成了滚动窗口;如果窗口步长大于窗口长度,那这些窗口上的数据只有部分数据,即一个事件可能不属于任何窗口。一般使用场景中,当窗口在数据流上滑动,窗口往往和其他滑动窗口重叠,也就是一个窗口中的数据流事件也同属于其他窗口
会话窗口:动态窗口的一种,指用户连续活动的时间区间,比如在淘宝上,用户从登录到最终离开,整个过程便是一个会话窗口。通过判断会话终止条件(相邻两个数据出现间隔不超过设置的会话时间)将连续事件拆分到不同会话窗口中。会话窗口的窗口长度是不固定的,每个会话窗口里的事件几乎不相同.
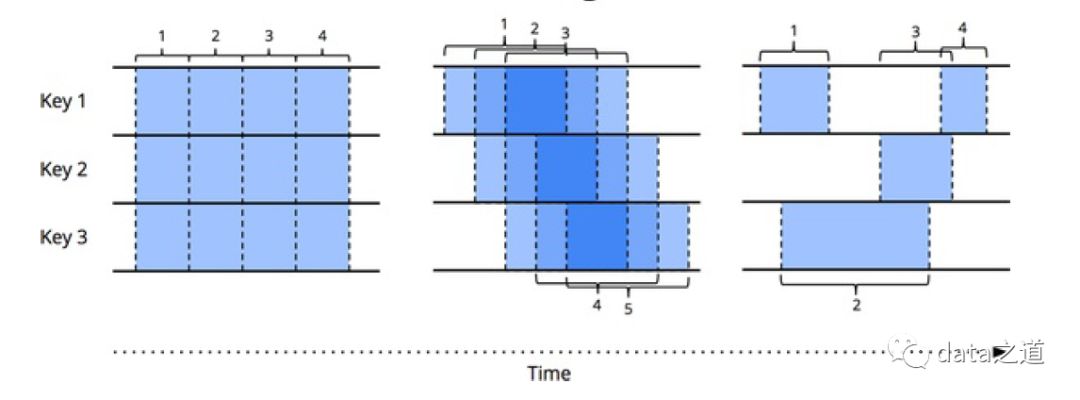
从左到右:滚动窗口、滑动窗口、session窗口
1.4 时间窗口
时间和窗口可以组成多种不同的窗口实现,比如处理时间的窗口函数,实现简单、窗口边界易于确定,只需要缓存数据,而不用担心数据发生改变;如果要反映事件实际发生的情况, 就必须以事件时间为基准处理数据,比如分析移动端在5分钟内的行为,APP一般先把收集到的数据缓存起来,等到一定数据量后再打包发送,手机在离线状态时会一直缓存,直到联网后才发送,这样处理时间和事件时间会有很大偏差,用处理时间分析不到真实的情况。而事件时间能解决这个问题,它会基于事件的发生时间将数据分到不同窗口:
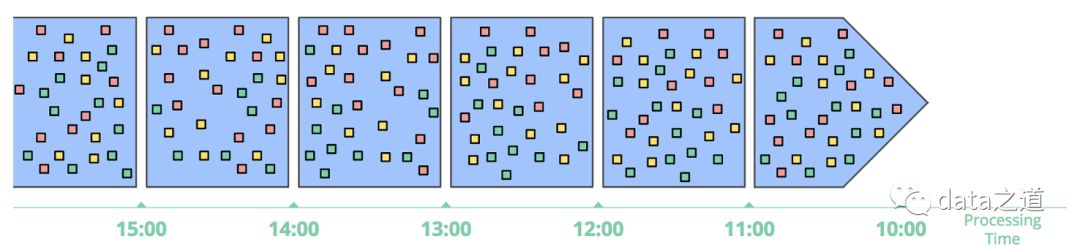
根据处理时间开滚动窗口的示意图
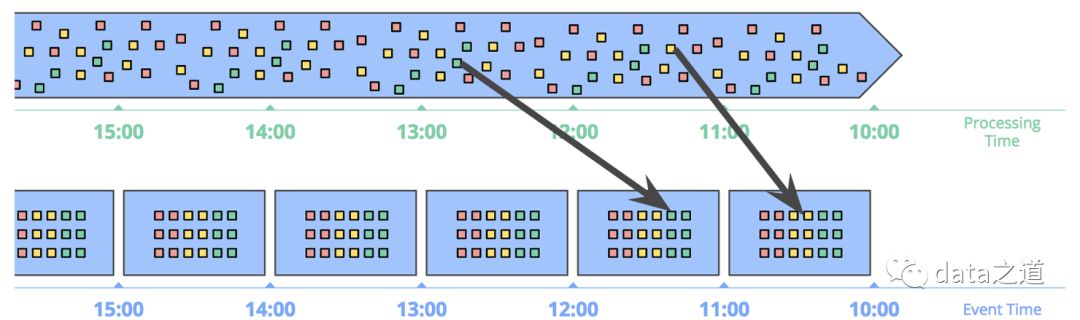
根据事件时间开滚动窗口的示意图
事件窗口函数的生命周期会比窗口实际长度长,但这里还有个疑问,当我们用事件窗口函数时,怎么断定在给定的窗口里,所有的事件都已经到达了呢?后面会有详细介绍。
1.5 有状态管理
如果处理一个事件(或一条数据)的结果只跟该事件本身有关,则称为无状态处理;反之计算结果还和之前处理过的事件有关,就称为有状态处理。稍微复杂一点的数据处理,比如说基本的聚合,都是有状态处理。
在批处理中,每次处理的都是全量数据,就不用考虑状态这个事情。在流式处理中,一般会借助外部存储系统实现状态保存。
1.6 流引擎分类
根据流式计算引擎的数据组织特点,可将其分为两类:基于行(row based)和基于微批处理(micro-batch based)。
基于行的流式实时处理系统以行为单位处理数据,其主要优点是处理延迟低,典型的代表是Storm;基于微批处理的流计算引擎则是将流式处理转化为批处理,即以批次为单位组织数据,通常以时间为单位将流式数据切割成连续的固定时间大小的数据(将数据流进行分片),并通过批处理的方式处理每批数据(分片数据),这类系统的优点是吞吐率高,而缺点也很明显:数据处理延迟较高,典型代表比如Spark Streaming。微批处理还存在跨session问题,session是一次用户的标识,当计算session时,通常会把一个session分割到多个微批次里,一般要用额外的逻辑处理,拼接会话,这增加了程序的复杂性。
1.7 数据一致性
一致性语义是指相同数据被传递或处理的次数,它可划分为以下三种:
at most once:即至多被处理一次,这意味着数据可能有丢失,一般不会在生产环境中使用
at least once:即至少被处理一次,这意味着数据可能被处理多次,这是最常用的一致性语义,其实现开销最小,但用户需要在业务逻辑层处理好重复数据
exactly once:即正好被处理一次,这是最理想的情况,但由于真实环境中服务故障、网络超时等问题的存在,实现一个通用的支持“exactly once”的系统是非常困难的,常规的是基于操作的幂等性实现
在之前的文章讨论过kafka的一致性,,可以作为一个阅读参考。
二、数据乱序
在流式系统中数据乱序是很常见,乱序是指事件并不严格按照事件发生的先后顺序到达,这点在上面讨论时间窗口时也谈到过。特别是在分布式的场景中更普遍,即使数据发送方能保证事件按先后数据发送,但因为计算系统分布式的特点可能导致数据乱序处理。
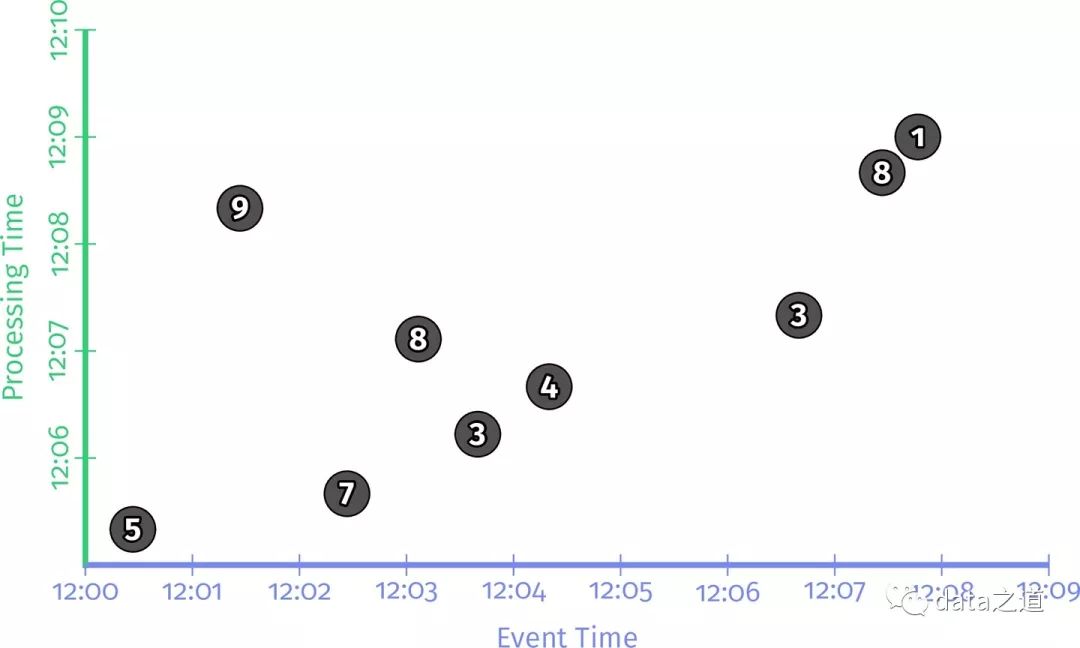
事件顺序发生异常,x:事件时间、y:事件处理时间
2.1 watermark
watermark用于界定何时(时间戳)认为一个时间窗口内的数据已经全部到齐,之后晚于该watermark到达的数据则为迟到数据。水印是衡量数据处理进度的一种手段,当达到watermark时,触发窗口操作。前面提到流式数据通常是基于时间窗口进行处理的,理想情况下,一个时间窗口内的数据全部到齐后才会处理,但现实世界总存在迟到数据,水印还会存在以下问题:
数据完整性:对于延迟到达的数据,由于到达时对应的时间窗口已经关闭,这些数据无法得到计算(可能被丢弃),这会影响最终结果的正确性
计算延迟:对于过早到达的数据,需要等待足够长的时间才能得到计算,对于这些数据而言,计算延迟过高,无法尽快看到结果
数据源空闲:如果一直没有数据到达,按照当前的水印生成方法,就会一直等待处理,窗口函数不会被执行,窗口不会输出任何结果
2.2 trigger
trigger是处理窗口数据的触发器,定义何时(时机)启动应用程序定义的数据处理任务、让一个窗口内聚集后的结果对外可见(比如写入文件系统)。流式数据进入计算引擎后按照时间窗口被切分并对其进行处理,一旦满足trigger触发条件,将对应窗口内的结果写入外部系统。为解决水印存在的问题而引入触发器的以下功能:
周期性触发:对于过早到达的数据,采用周期性的触发,可以使数据的结果尽快对外显现,不需要等到watermark时间戳触发计算
定量触发:对于延迟到达的数据,只要固定数目的延迟数据到达便触发计算
三、批处理和流处理优缺点
批处理是处理海量数据的传统手段之一,Hadoop作为一种大数据技术,因为其能满足批处理的各种要求而成为首选框架。
由于历史原因(流式计算不够成熟),流式处理通常提供低延迟、预测性质的结果集,然后和强大的批处理相结合,保证最终结果的正确性。企业的数据平台需要同时支持这两种处理方式,因为不同的处理方式服务于不同的场景。
四、Lambda架构
如前所述,在构建数据平台时,会遇到将批处理和流式处理相结合的的问题,幸运的是,该问题可由Lambda架构解决。
Lambda架构是技术无关性的通用架构规范,提供了在大数据集上执行可伸缩、高性能分布式计算的架构方法,清晰的把责任划分到不同功能模块中,任何技术只要满足需求都能在lamdba中应用。它允许在一个架构里同时处理流数据和批量数据,流式计算提供低延迟、近似的结果,一段时间后批处理再进行回滚补偿数据,保证最终数据的正确性,可以看出在Lambda架构里批处理和流处理是互补的关系。
Lambda架构图
Lambda提供了非常强大的功能,但是这种架构涉及到的框架太多,导致平台复杂度过高,运维成本过高:需要同时构建、维护两种独立的技术组件(分别是批处理层和流处理层),并且在最终结果集上还要合并这两个管道里的数据,保证结果的一致性;相同的计算工作需要实现两次(在批处理层和流处理层分别处理),如果能将批处理和流处理融合成一个系统,保留两者优点的同时具有灵活的扩展性,会是一个更完美的解决方案。
五、Kappa架构
Kappa架构和Lamdba架构相比有很多相似点,Kappa主要特点是去掉了Lambda架构中的批处理层,避免数据同时被两种任务处理,尝试把这些批处理计算完全放在实时计算层,解决Lamdba架构中必须编码并运行两次一样计算逻辑的问题。
有界数据流可以看成无界数据流的一个特例,所以从这个角度上看,如果一个作业能处理无限数据,那它也一定能处理有限数据,也就是当流处理输入的是有限数据集时就成了批处理,流计算是批处理的超集,这为实现Kappa架构提供了技术上的可能性。
「在一起看」 以上是关于Flink CookBook—流式计算介绍的主要内容,如果未能解决你的问题,请参考以下文章