Flink原理|Flink流式计算在节省资源方面剖析
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink原理|Flink流式计算在节省资源方面剖析相关的知识,希望对你有一定的参考价值。

信息流推荐业务是小米从Spark Streaming迁移到Flink流式计算最早也是使用Flink最深的业务之一,在经过一段时间的合作优化后,对方同学给我们提供了一些使用效果小结,其中有几个关键点:
-
对于无状态作业,数据处理的延迟由之前Spark Streaming的16129ms降低到Flink的926ms,有94.2%的显著提升(有状态作业也有提升,但是和具体业务逻辑有关,不做介绍); -
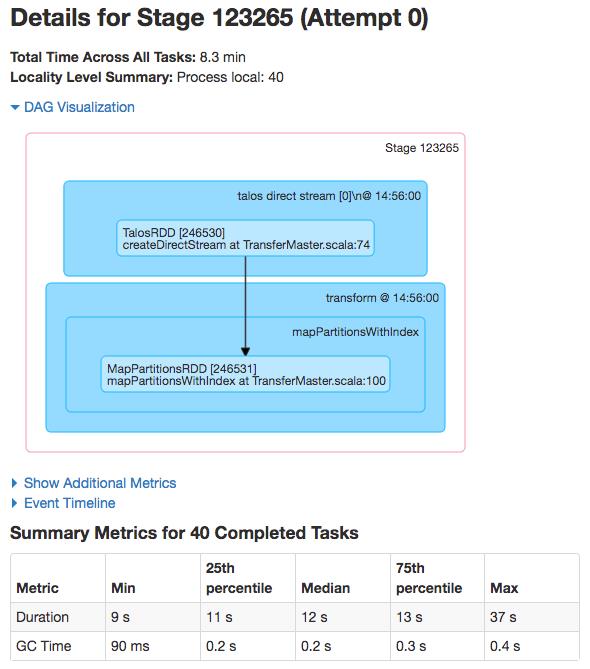
对后端存储系统的写入延迟从80ms降低到了20ms左右,如下图(这是因为Spark Streaming的mini batch模式会在batch最后有批量写存储系统的操作,从而造成写请求尖峰,Flink则没有类似问题): 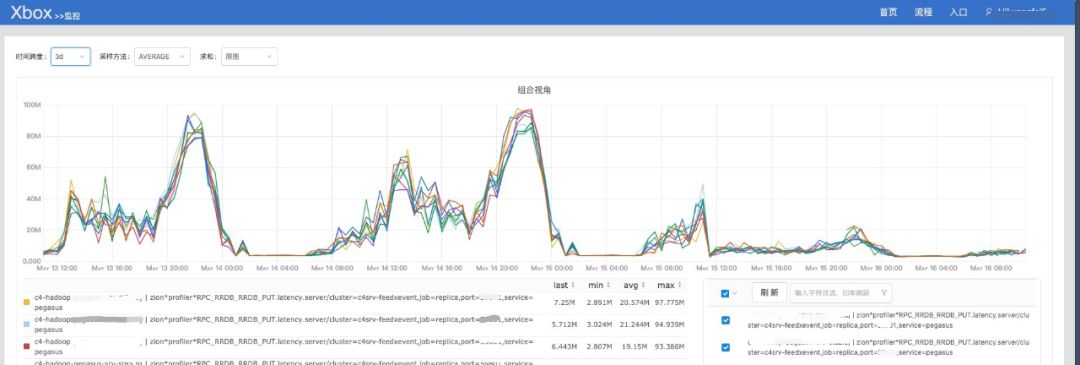
-
对于简单的从消息队列Talos到存储系统HDFS的数据清洗作业(ETL),由之前Spark Streaming的占用210个CPU Core降到了Flink的32个CPU Core,资源利用率提高了84.8%;
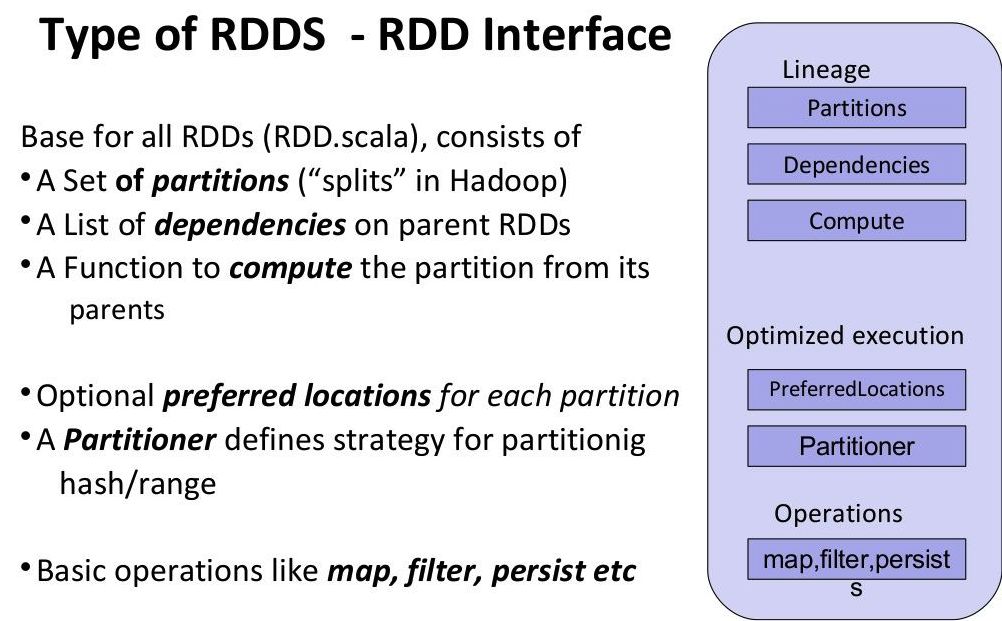
// RDD
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// KafkaRDDoverride def getPreferredLocations(thePart: Partition): Seq[String] = { val part = thePart.asInstanceOf[KafkaRDDPartition] Seq(part.host) // host: preferred kafka host, i.e. the leader at the time the rdd was created }
”调度计算”的方法在批处理中有很大的优势,因为“计算”相比于“数据”来讲一般信息量比较小,如果“计算”可以在“数据”所在的节点执行的话,会省去大量网络传输,节省带宽的同时提高了计算效率。但是在流式计算中,以Spark Streaming的调度方法为例,由于需要频繁的调度”计算“,则会有一些效率上的损耗。
首先,每次”计算“的调度都是要消耗一些时间的,比如“计算”信息的序列化 → 传输 → 反序列化 → 初始化相关资源 → 计算执行→执行完的清理和结果上报等,这些都是一些“损耗”。
另外,用户的计算中一般会有一些资源的初始化逻辑,比如初始化外部系统的客户端(类似于Kafka Producer或Consumer);每次计算的重复调度容易导致这些资源的重复初始化,需要用户对执行逻辑有一定的理解,才能合理地初始化资源,避免资源的重复创建;这就提高了使用门槛,容易埋下隐患;通过业务支持发现,在实际生产过程中,经常会遇到大并发的Spark Streaming作业给Kafka或HBase等存储系统带来巨大连接压力的情况,就是因为用户在计算逻辑中一直重复创建连接。
Spark在官方文档提供了一些避免重复创建网络连接的示例代码,其核心思想就是通过连接池来复用连接:
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}


// Not a POJO demo.public class Person { private Logger logger = LoggerFactory.getLogger(Person.class); public String name; public int age;}
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// register the serializer included with Apache Thrift as the standard serializer
// TBaseSerializer states it should be initialized as a default Kryo serializer
env.getConfig().addDefaultKryoSerializer(MyCustomType.class, TBaseSerializer.class);
以上是关于Flink原理|Flink流式计算在节省资源方面剖析的主要内容,如果未能解决你的问题,请参考以下文章