如图,各个包之间存在联系,说明每个联系的含义
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如图,各个包之间存在联系,说明每个联系的含义相关的知识,希望对你有一定的参考价值。
如图,各个包之间存在联系,说明每个联系的含义,若回答准确有追加分数。
请复制下面进行解释:
——————————————————
bean与dao的联系:
bean与servlet的联系:
bean与util的联系:
bean与service的联系:
dao与service的联系:
dao与util的联系:
dao与sql的联系:
service与dao的联系:
service与servlet的单向联系:
service与util的联系:
————————————————
若回答准确有追加分数。
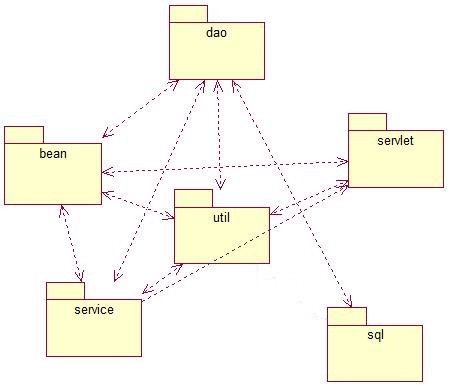
bean与servlet的联系:servlet对数据进行实体类整合(转型)或者创建bean
bean与util的联系:工具类是bean的基本操作
bean与service的联系:service业务层对bean进行数据转型
dao与service的联系:service从到dao哪里获取数据,在进行业务处理
dao与util的联系:dao是可以进行基本的事务操作,比如连接数据库之类的,获取相关数据结果
dao与sql的联系:dao是实体类bean与底层数据库事务操作
service与dao的联系:dao给service发送数据
service与servlet的单向联系:servlet从业务层获取相关业务处理结果
service与util的联系:service调用工具类进行基本工具操作,比如连接数据库之类的
bean--->连接数据库--->dao操作---->service操作----->servlet(或者action)-->jsp本回答被提问者和网友采纳 参考技术B MVC的东西啊,这个自己上网查下看看,不懂的再单独问吧追问
高手帮帮我!把懂的都告诉我,悬赏不是问题
追答额额,这样说很麻烦的,你首先知道每一层是什么意思先。我具体举个例子你理解吧
假设你做一个功能,那么你就要通过前台的jsp页面去访问action(你这里的话应该是servlet的吧),然后action再去调用service,service做业务逻辑处理后封装成bean对象就去调用dao,通过dao的方法存储到sql数据库里面,然后util是工具包,里面就写一些通用的方法。大概就这样吧,很详细的可以具体自己度娘里找找
nagios配置过程详解
一、nagios配置过程详解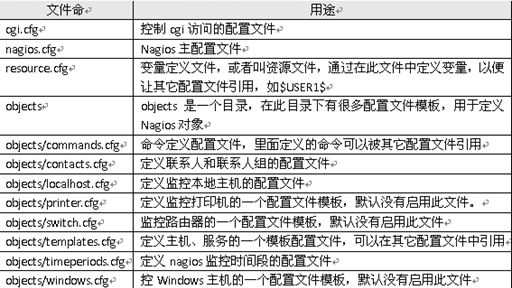
- define contact{
- name generic-contact #联系人名称,
- service_notification_period 24x7 #当服务出现异常时,发送通知的时间段,这个时间段“7x24"在timeperiods.cfg文件中定义
- host_notification_period 24x7 #当主机出现异常时,发送通知的时间段,这个时间段“7x24"在timeperiods.cfg文件中定义
- service_notification_options w,u,c,r #这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态,u即unknown,表示不明状态,c即criticle,表示紧急状态,r即recover,表示恢复状态。也就是在服务出现警告状态、未知状态、紧急状态和重新恢复状态时都发送通知给使用者。
- host_notification_options d,u,r #定义主机在什么状态下需要发送通知给使用者,d即down,表示宕机状态,u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。
- service_notification_commands notify-service-by-email #服务故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件,其中“notify-service-by-email”在commands.cfg文件中定义。
- host_notification_commands notify-host-by-email #主机故障时,发送通知的方式,可以是邮件和短信,这里发送的方式是邮件,其中“notify-host-by-email”在commands.cfg文件中定义。
- register 0
- }
- define host{
- name generic-host #主机名称,这里的主机名,并不是直接对应到真正机器的主机名,乃是对应到在主机配置文件里所设定的主机名。
- notifications_enabled 1
- event_handler_enabled 1
- flap_detection_enabled 1
- failure_prediction_enabled 1
- process_perf_data 1
- retain_status_information 1
- retain_nonstatus_information 1
- notification_period 24x7 #指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。
- register 0
- }
- define host{
- name linux-server #主机名称
- use generic-host #use表示引用,也就是将主机generic-host的所有属性引用到linux-server中来,在nagios配置中,很多情况下会用到引用。
- check_period 24x7 #这里的check_period告诉nagios检查主机的时间段
- check_interval 5 #nagios对主机的检查时间间隔,这里是5分钟。
- retry_interval 1 #重试检查时间间隔,单位是分钟。
- max_check_attempts 10 #nagios对主机的最大检查次数,也就是nagios在检查发现某主机异常时,并不马上判断为异常状况,而是多试几次,因为有可能只是一时网络太拥挤,或是一些其他原因,让主机受到了一点影响,这里的10就是最多试10次的意思。
- check_command check-host-alive #指定检查主机状态的命令,其中“check-host-alive”在commands.cfg文件中定义。
- notification_period workhours #主机故障时,发送通知的时间范围,其中“workhours”在timeperiods.cfg中进行了定义,下面会陆续讲到。
- notification_interval 120 #在主机出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你觉得,所有的事件只需要一次通知就够了,可以把这里的选项设为0
- notification_options d,u,r #定义主机在什么状态下可以发送通知给使用者,d即down,表示宕机状态,u即unreachable,表示不可到达状态,r即recovery,表示重新恢复状态。
- contact_groups admins #指定联系人组,这个“admins”在contacts.cfg文件中定义。
- register 0
- }
- define service{
- name generic-service #定义一个服务名称
- active_checks_enabled 1
- passive_checks_enabled 1
- parallelize_check 1
- obsess_over_service 1
- check_freshness 0
- notifications_enabled 1
- event_handler_enabled 1
- flap_detection_enabled 1
- failure_prediction_enabled 1
- process_perf_data 1
- retain_status_information 1
- retain_nonstatus_information 1
- is_volatile 0
- check_period 24x7 #这里的check_period告诉nagios检查服务的时间段。
- max_check_attempts 3 #nagios对服务的最大检查次数。
- normal_check_interval 10 #此选项是用来设置服务检查时间间隔,也就是说,nagios这一次检查和下一次检查之间所隔的时间,这里是10分钟。
- retry_check_interval 2 #重试检查时间间隔,单位是分钟。
- contact_groups admins #指定联系人组,同上。
- notification_options w,u,c,r #这个定义的是“通知可以被发出的情况”。w即warn,表示警告状态,u即unknown,表示不明状态,c即criticle,表示紧急状态,r即recover,表示恢复状态。也就是在服务出现警告状态、未知状态、紧急状态和重新恢复后都发送通知给使用者。
- notification_interval 60 #在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟。如果你认为,所有的事件只需要一次通知就够了,可以把这里的选项设为0。
- notification_period 24x7 #指定“发送通知”的时间段,也就是可以在什么时候发送通知给使用者。
- register 0
- }
- $USER1$=/usr/local/nagios/libexec
其中,变量$USER1$指定了安装nagios插件的路径,如果把插件安装在了其它路径,只需在这里进行修改即可。需要注意的是,变量必须先定义,然后才能在其它配置文件中进行引用。
- define host{
- host_name ixdba
- address 192.168.12.246
- check_command check_ping
- ...
- }
- define command{
- command_name check_ping
- command_line /usr/local/nagios/libexec/check_ping -H $HOSTADDRESS$ -w 100.0,90% -c 200.0,60%
- }
- /usr/local/nagios/libexec/check_ping -H 192.168.12.246 -w 100.0,90% -c 200.0,60%
- define service{
- host_name linuxbox
- service_description PING
- check_command check_ping!200.0,80%!400.0,40%
- ...
- }
- define command{
- command_name check_ping
- command_line /usr/local/nagios/libexec/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$
- }
- /usr/local/nagios/libexec/check_ping -H 192.168.12.246 -w 200.0,80% -c 400.0,40%
- #下面是notify-host-by-email命令的定义
- define command{
- command_name notify-host-by-email #命令名称,即定义了一个主机异常时发送邮件的命令。
以上是关于如图,各个包之间存在联系,说明每个联系的含义的主要内容,如果未能解决你的问题,请参考以下文章