打赢数据安全攻坚战,从Hadoop-security治理说起!
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打赢数据安全攻坚战,从Hadoop-security治理说起!相关的知识,希望对你有一定的参考价值。
作者介绍
汪涉洋,来自美国视频网站hulu的工程师,毕业于北京理工大学计算机专业,目前从事大数据基础架构方面的工作,个人知乎专栏“大数据SRE的总结”:http://dwz.cn/7ygSgc。
前言
对于数据安全,不同的立场有不同的考量,本文主要关注公司立场的Hadoop数据安全。
对企业而言,做好Hadoop这个企业级最大的数据仓库的数据安全是重中之重,面临许多挑战,但遗憾的是目前大部分公司做的还不够完善,有的甚至形同虚设。
我最近正在实践Hadoop Security领域,希望能整理出一个体系,并且讲明白安全在大数据Hadoop体系中都有什么知识、有哪些可做的事情。对于不同“国情”的企业,为什么Hadoop安全方案难以实施;对于不同阶段的企业,应该把Hadoop的安全实施到什么程度。
Agenda
1.没有Hadoop-security会出什么问题?
2.为了有Hadoop-security,企业可以采取哪些手段?
3.Kerberos in Hadoop&分布式程序认证设计
4.企业方案选择
没有Hadoop-security会出什么问题?
关于这个话题,笔者觉得还是用案例来说明比较适合,因为太技术的表达不仅干,还没意思。
1.用户不经过认证,可以伪装成”任意其它用户“做任何事情,包括“恶意事件”。
可以 delete / update 任意的HDFS文件 和 Hive tables。
可以提交任意的Hadoop job到任意Queue,导致集群资源紧张时,管理员无从管治。
事实上很多公司的Hadoop集群都没有配置安全认证,都是裸跑,安全隐患非常大。而仅仅的一个好消息是——Hadoop集群往往都是供公司内部的数据分析师使用,因此大多部署在公司内网,外网的人很难直接访问。
但也有一些关于Hadoop被攻击的新闻,给大家参考:
How to secure ‘Internet exposed’ Apache Hadoop - Cloudera Engineering Blog
http://blog.cloudera.com/blog/2017/01/how-to-secure-internet-exposed-apache- hadoop/
Hadoop集群遭遇勒索软件攻击
http://toutiao.secjia.com/hadoop-cluster-under-ransomware-attack
全球大数据系统遭勒索,观数科技出手对抗Hadoop风险-CSDN.NET
https://www.csdn.net/article/a/2017-02-07/15817281
这是由于Hadoop集群有一些网络拓扑中的“边缘机器”,可以被外网访问,于是外网黑客找到了突破口,成功攻进了内网Hadoop集群。
那如何伪装成“超级用户”呢?笔者觉得这已经不是秘密了,就直接把链接放出来,毕竟做好安全才是正道:
客户端用户法:Impersonate as superuser on client shell. Author.. and Authen.. In Hadoop - Cloudera Blog
http://blog.cloudera.com/blog/2012/03/authorization-and-authentication-in-hadoop/
环境变量法:How to specify username when putting files on HDFS from a remote machine
https://stackoverflow.com/questions/11371134/how-to-specify-username-when-putting-files-on-hdfs-from-a-remote-machine
可能禁止环境变量法么?How to prevent users from modifying HADOOP_USER_NAME ?
https://community.hortonworks.com/questions/110020/how-to-prevent-users-from-modifying-hadoop-user-na.html
2.因此,Hadoop管理员会管不好Hadoop,严重时甚至会失控。
Admin不知道是否可以删除一个冷数据 ( UserA 伪装成“superuser”创建的文件 )
Admin不知道计算资源的使用情况,不知道谁滥用了资源。 ( userA 伪装成“teamXuser”把作业提交到别的队列 )
Admin 甚至不知道谁把重要的HDFS文件和Hive表删掉了!
3.一个普通的Hadoop User都能查询公司金融交易数据表,在财务知道前就了解公司这个月的流水、成交量,再把这些信息贩卖给竞争对手、把数据卖给金融机构...
看了这些是不是觉得可怕?但在真实世界里,作恶的手段只会比以上更高明。所以整体而言,公司的Hadoop管理员更应该防范的对象是内部的程序员/分析师!
企业可以采取哪些手段
目前在业界,Hadoop Security似乎还没一个“既方便实施,又操作简单、容易维护”的解决方案。
比如认证,Apache的官方社区Hadoop版本为了一站式地完美解决认证问题,使用了Kerberos。Kerberos是非常重的一种安全方案,一般人难以发挥好,但也是业界工程上在认证这一块最安全的方案。
所以一句话概括Hadoop Security的实施现状:安全和效率/易维护性是成反比的。
我们先来看看 Cloudera 和 Hortonworks 对Hadoop Security的定义
Cloudera:
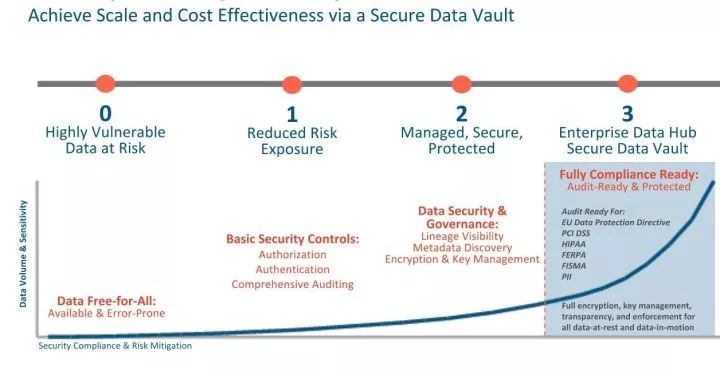
Cloudera把Hadoop的安全级别定义为4级:
Level 0:即没有任何安全,裸跑。大多数公司的集群都是从这里开始的,因为没有安全的集群搭建速度很快,容易上手,但也毫无安全可言。User可以伪装成任何其它User,甚至“超级用户”,去给Namenode/Datanode发送RPC请求,甚至可以直接向Datanode请求读取block。
Level 1:从这开始就有了基本的安全。首先,建立起认证机制,让每个用户在访问Hadoop集群时一定证明了“自己是自己”。然后再建立授权机制,给相应的User/Group予以不同的访问权限。当然最好还有审计工作,记录下来谁在什么时间,对集群做了什么操作,这些操作都会被严格纪录下来。
可是,Cloudera认为这还不够安全,因为这些措施可以“防住”普通的用户,但并不能防住“Hadoop-admin”自己,Hadoop-admin还可以像我上面说的,访问公司的敏感数据。走到这一步,对人的管理会称为瓶颈。
Level 2:要有更强的安全。整个集群的所有数据,或者至少是公司级的敏感数据,需要加密! 应该有统一的密钥管理中心管理着每一类数据的访问密钥。还有数据治理,也变得更加关键。数据治理要做到,哪些人访问过“Hive元数据”,这些行为应该被更严格的审计!
Level 3:最高级别的安全。全数据中心的所有数据都是加密的,而且密钥管理中心做到了高可用HA。使用/访问集群的任何行为,都会被审计,并且达到了行业的审计标准。审计还不光光包括Hadoop相关的组件,任何使用Hadoop的程序、与Hadoop相关的程序,都应该被严格的审计。
Hortonworks:
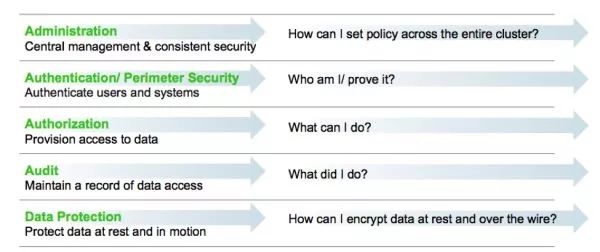
Hortonworks把Hadoop的安全定义为5个方面,但他并没有给出具体的安全级别:
1.管理中心。 用来统一设置集群的安全策略。
2.认证。 证明你是你。
3.授权。 你能干什么。
4.审计。 你干了什么。
5.数据保护,数据加密。 怎么加密,怎么管理加密。
纵观Cloudera & Hortonworks社区的Security文章,Hadoop Security的知识范畴,分为下面5个领域。它们之间既有相互的依赖,又有其解决相应问题的独到之处:
1.Authentication & Authorization (算法隔离,秘钥,加密算法)
2.Hadoop-client Management (物理隔离)
3.Audit(审计)
4.数据加密 (密钥管理中心及其高可用)
5.自动化管理后台
后文我会提到这几方面,讲述为什么不同的公司实施这些安全方面的工作如此之难。
Kerberos in Hadoop&分布式程序认证设计
Hadoop安全里最重要的一个组件是Kerberos,如果没有认证,绝对安全就无从谈起。
我们在使用IT系统,涉及系统内的私密个人信息时,都需要认证。认证是一个简单的信息交换过程, 即用户向服务证明你是你。
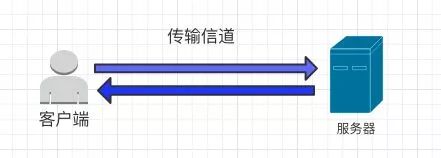
典型的认证过程中,有三个参与方面 : 客户端、传输信道、服务器。而所谓的“不安全”,在这三个参与方处都有可能发生。
1.认证问题很严重
在Web时代,网络总是很不安全,发生过很多问题。Owasp组织每年都会总结出每年互联网世界中Top10的安全问题,并给予建议。而身份认证,常常排名在前3名。

2.认证不安全的场景
客户端C:
C1.凭证填充,使用已知密码。你的浏览器是否开启了记住密码自动填充?他人是否可以在你不在时使用你的账号登陆某些网站?
C2.应用会话超时设置不正确。用户使用公共计算机访问应用程序后,用户直接关闭浏览器选项卡就离开,而不是选择“注销”。攻击者一小时后使用同一个浏览器浏览网页,而当前用户状态仍然是经过身份验证的。
服务器S:
S1. 服务器存储用户密码的数据库,使用明文存储。网站端工作人员可以盗破用户密码。
S2. 服务器要求的密码位数太短,太简单,导致用户密码,在分布式算力强大的时代背景下,容易被“暴力破解”。比如,著名的“彩虹表”。
S3. 服务器端网络不安全,被攻破,被拖库。
信道Channel:
CH1. 黑客监听/截获网络数据包。黑客已经攻入网络,可以监听到用户到server端的发送报文。黑客如果截获的信息是明文,就是最坏的情况。黑客如果截获的是密文,仍可以采取“破解密码” or “篡改并重发报文”等作恶手段,达到目的。
3.Kerberos特征及解决认证的问题
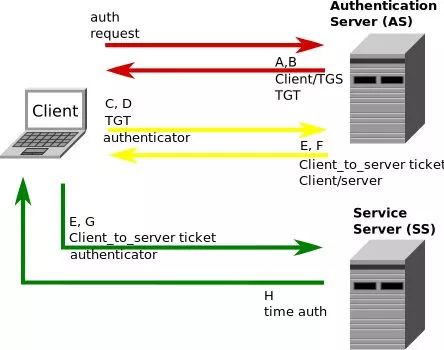
Kerberos解决了以上所有问题:
1.登陆会话及过期,保证登陆状态有时效性。时效性短,但客户端可以refresh。极大的改善了C1、C2。
2.Kerberos存储密码的KDC数据库及其技术可信,被证明过是“可信的第三方”。
3.密码不用在信道传输,从根本上去除CH1中的密码被截获的可能性。
4.信道传输的东西是加密的,且信道传输的信息也是有时效性的。
信息还是有被暴力破解的可能性。但只要使time(session-key 过期) < time(破解sessionkey加密的信息)就够了。信息被黑客破解只在理论上成立,现实中不可能。因为你破解的信息已经过时了,新的信息又是用最新的Session-key进行加密。
这一章节的目的不是去讲Kerberos细节,而是讲Kerberos与Hadoop的结合,以及Hadoop当中涉及Kerberos的设计思路,给我们设计“安全的分布式程序“的启发。
在分布式的场景下,绝对安全很复杂。分布式意味着“结点”以及“进程”的分散。
在企业级这个level,公司集群动辄几百上千的机器,公司内又有无数的程序员在用开发机器作为客户端在访问这些集群,那么结点进程互相之间的认证就是一个更加复杂的网。
Hadoop可以算是分布式安全领域的top开源项目,那么其在分布式背景下的安全框架设计,肯定有值得我们琢磨的地方。
1.Kerberos Principals
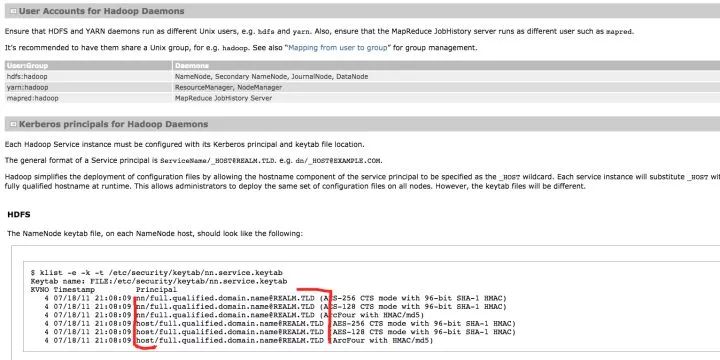
Kerberos中最重要的概念是Principal,可以把它理解为用户或服务的名字,是全集群唯一由三部分组成的:username(or servicename)/instance@realm。
例如:nn/host001@TEST.COM,host001为集群中的一台机器;或admin/admin@TEST.COM,管理员账户。
Username or Servicename:在本文里为服务,HDFS的2个服务分别取名为nn和dn,即NameNode和Datanode。
Instance:在本文里为具体的FQDN机器名,用来保证全局唯一(比如多个Datanode节点,各节点需要各自独立认证)。
Realm:域,我这里为http://TEST.COM(全大写哟)。
Hadoop 会为每一个host每一个process都生成Principal。比如为HDFS的 NameNode和 Yarn的ResourceManager都生成各自的principal。这让整个Hadoop的Security达到了一个高水准,细节请看: Hadoop in Secure Mode(https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SecureMode.html#Introduction)。
2.分布式中的认证场景
在一个绝对安全的分布式场景下,每两台Server之间互相联系,都需要认证彼此。如果一个Cluster有N台机器,理论上是要有 N平方对的请求需要获取Kerberos Ticket。
我们按系统的部署复杂度,渐近式地罗列认证场景:
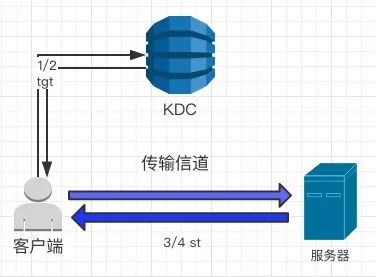
最简模型
要求认证者只有一台服务器,这是最简模型,没什么好说的。标准的Kerberos模版。
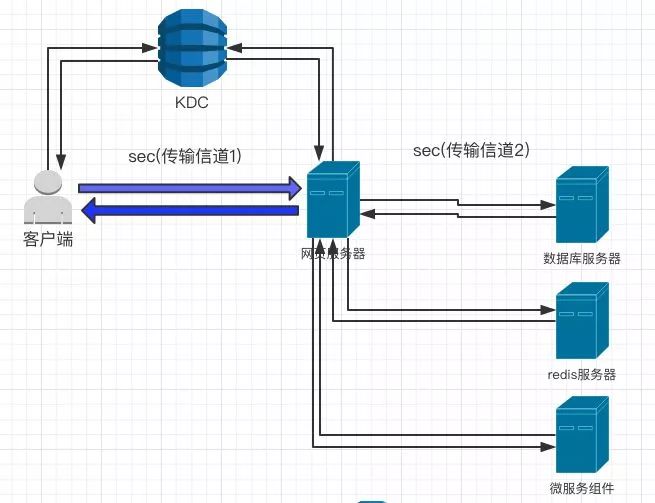
简单的分布式部署场景
参与者是一个“链”,甚至是一颗“树”。比如一个大型应用系统 、web服务器与数据库/缓存服务器的分离,以及大型公司内部微服务化的部署。
复杂的分布式部署场景
在Hadoop系技术栈下,基本都是复杂的分布式部署场景,组件的“种类”多,组件的“数量”也多。两两之间在通信(发送RPC请求)时,都需要彼此“认证”。
3.Hadoop认证场景的特点Scenario
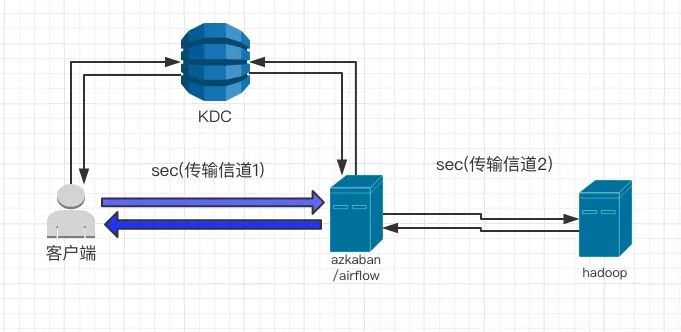
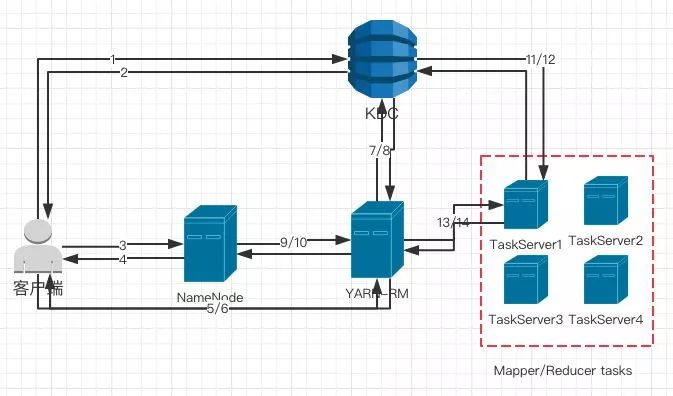
S1.某些门户服务器,负责接受用户请求,然后代用户,向后方真正的集群进行交互。
比如在用户使用诸如Hive/ Oozie / Azkaban 提交job时,用户希望真正提交到 Yarn 里的 job 的User还是用户自己。
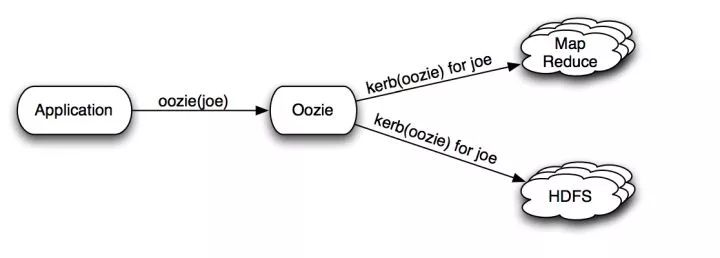
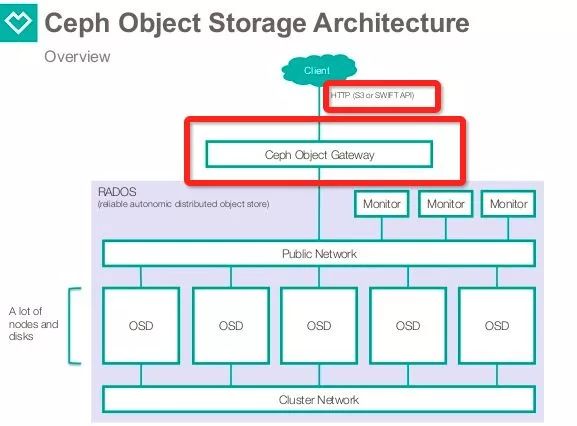
比如在Ceph中,Client端可以通过 http-api/s3-api / swift-api 等方式访问 Ceph os Gateway。而Gateway server这个跳板,又会模拟用户去真正的调用librados。
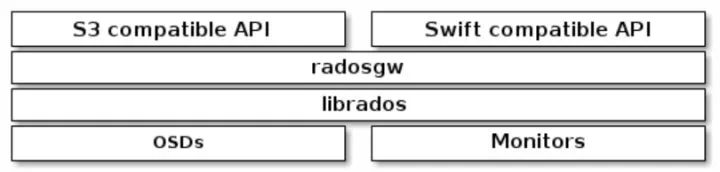
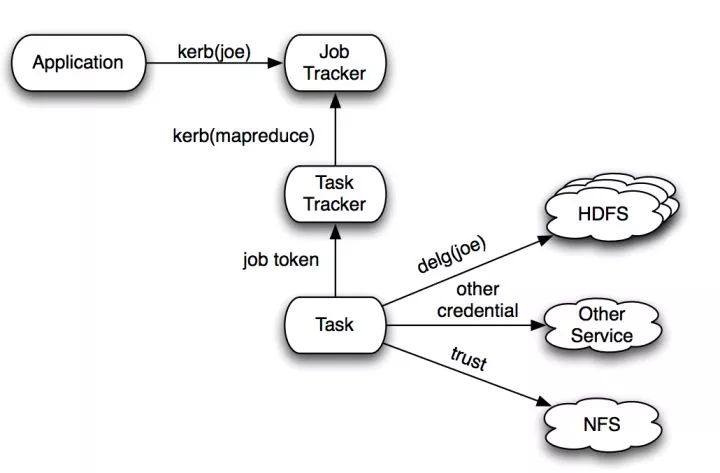
S2.用户提交的计算任务,分布式运行。运行的子task都以提交用户的权限去访问其它“第三方”系统。
比如:Hadoop用户提交的Mapreduce job,在每一个task中都有可能访问HDFS。在访问HDFS时,以提交job的用户来访问HDFS,甚至其它第三方Service。
4.这些场景会产生以下几个问题 (Question)
在场景S1下,Gateway服务器是连接用户和系统的屏障,Gateway服务器还要能装扮成“原提交用户“去和后端系统交互。
Q1-S1. principal & keytab 泛滥,管理困难。
根据上面Kerberos Principal的定义 Username/instance@realm,同一个用户在不同的机器上,是需要配置不同的Principal的。倘若公司内有m个用户,n台Gateway机器,就要预先定义m*n个Principal,且新创建的Gateway机器都要重复这个过程。而且这些Gateway服务器在做kinit操作时,又要使用keytab,这都会导致对Principal以及其对应的keytab (what is a keytab)的管理变的困难。
在场景S2下,计算job会生成很多的子计算任务,且分散在集群的很多机器上。这不仅仅会引起Q1-S1同样的问题,还会更严重。一个大型公司的Hadoop Cluster,上面每天甚至会跑几万几十万的job。每个job又会生成很多的Mapreduce 子task,这些job的生命周期从几分钟到天不等。
Q2-S2. 加强版Q1-S1.
由于job的短生命周期,而产生的大量短生命周期Principal & Keytab
Q3-S2. KDC承受压力,有dos的风险(deny of service)。
在一些大的job launch时,会有很多很多的子task疯狂的访问KDC,而Kerberos涉及了很多的加解密操作,KDC本就是CPU密集型应用,再加上Handle大量的网络请求,很有可能导致 deny of service,让其它访问KDC的正常Kerberos请求不可用。
Q4-S2. long-running的job,ticket会过期,需要处理好。
很多Hadoop上跑的Mapreduce job,都会跑很久,甚至好几天。而Kerberos的Session key在设计之初,就是要过期,防止暴力破解的。那这些job需要去Renew他们的ticket。怎么实现?
5.Hadoop这些问题的解决之道,以及对设计“分布式系统安全”的可借鉴经验(solution)
Q1-S1. principal & keytab 泛滥,管理困难。
常规解法:kerberos forward/proxy ticket , 让gateway机器可以使用客户端的ticket,访问后端机器。
Oracle : kerberos forwardable ticket doc
https://docs.oracle.com/cd/E19253-01/816-4557/user-68/index.html
Delegation of Authentication (proxy & forwarded tickets)
https://technet.microsoft.com/en-us/library/cc961964.aspx
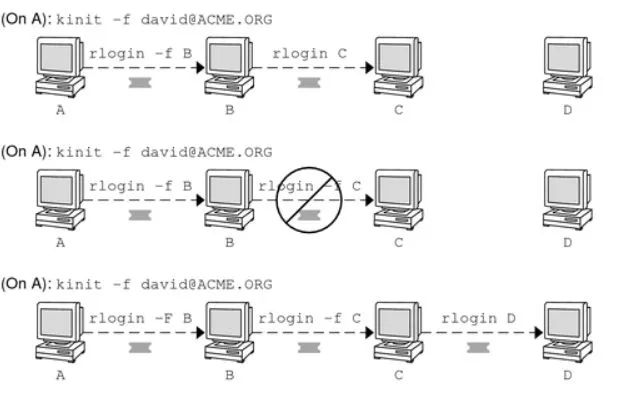
缺点:不论是Proxy还是Forwardable ticket,都需要在客户端kinit时,把Gateway机器/后端机器加入kinit的参数当中。其次这种ticket的时效性管理贯穿多台机器很麻烦。总之,这种实现的复杂度比较高,和Kerberos协议耦合太深。
Hadoop解法:impersonate | proxy user。
Proxy user - Superusers Acting On Behalf Of Other Users
https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/Superusers.html
Hadoop提供了一种使用超级用户,伪装成普通用户访问集群组件的办法,这种办法在Hadoop的代码级别做了支持。在Gateway机器和后端机器进行RPC Kerberos认证时,仍然使用Gateway机器上的Principal去获取tgt。
但真正在做访问控制时,使用Impersonate技术,Superuser会模拟普通用户。这就解决了Q1-S1问题。这是以牺牲一部分绝对安全性为代价,换来了复杂度的减少。不过由于在企业内部,Gateway机器及后端机器都是被管理员严格控制的,所以这是一个行之有效的技术。
Tips:还有一个比较生动的例子来解释这个Solution的合理性:
一个“警察”,他拥有超越普通公民的权利,但他在执行任务时,可以装扮成便衣,这样他在访问商店,办理事务时,会被作为“普通”公民对待。这是合法的。但一个普通公民,你要是装扮成“警察”,那就应该被抓住,是违法行为。
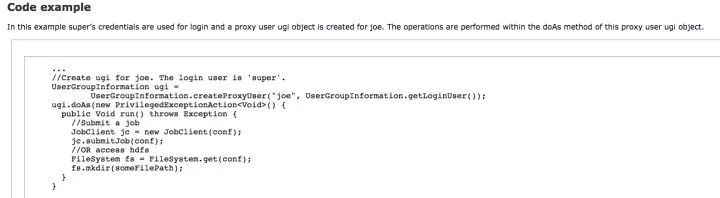
Impersonate技术并非允许所有Gateway服务器/所有进程,都可以做Impersonate。这种行为是被严格控制的,需要Admin把这些配置在Hadoop的配置文件中。
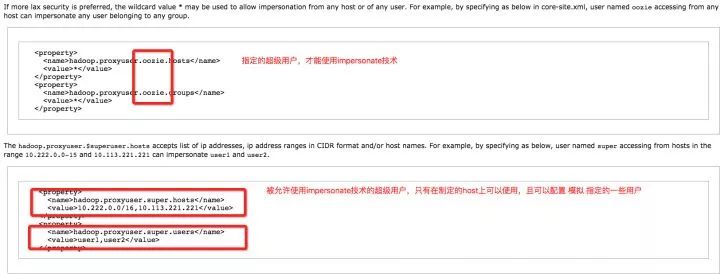
Q2-S2. 解决办法同上Q1-S1。
Q3-S2. KDC承受压力,有DOS的风险(deny of service)。
常规解法:给KDC做Sharding,做负载均衡。
是的,KDC不外乎也就是一个Server,下面挂一个DB,那么理论上肯定是可以做Sharding和负载均衡的。但这样做会又本来就复杂的实施Kerberos环境增加了更多的复杂性。
Hadoop解法:Delegation-Tokens
这个Delegation-Tokens值得好好的说一说。上面我们提到了大量的Mapreduce tasks 会造成KDC的 DOS (deny of service)。我们通过下图看一下:
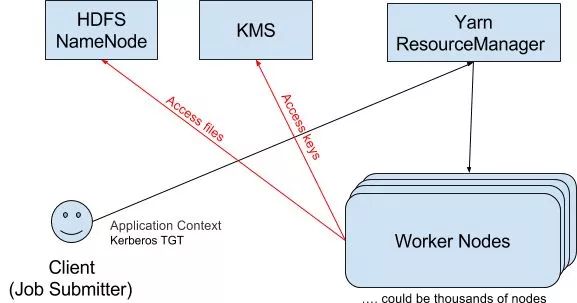
图中的红线表明: 一个MR job里,会切分成很多的Workernode的task进程,他们在运行时,会向HDFS的NameNode,或者Hadoop的其它组件诸如KMS,发出RPC请求。
我们知道,在Kerberos环境中,每一次RPC请求都要经过验证,都要去KDC获取TGT,那么这就会导致KDC承受大量的traffic。
所以Hadoop就弄出了Delegation Tokens这样一个轻量级的Authentication解决方案来代替分布式MR job场景下的Kerberos authentication。Kerberos是一个三方协议,相反, Delegation Token认证是一个两方协议。
Delegation Tokens的工作原理:
Client通过Kerberos和NameNode初始化认证,然后请求NameNode拿到一个Delegation Token。
Client把Delegation Token放入提交的job的context,发送给Yarn Resourcemanager。
Yarn RM 把job的执行环境初始化好,然后启动很多Container去跑MR job的子tasks,把Delegation Token 通过Container的Context再一次下发给Workernodes。
每个Workernode上的子task进程都使用这个Delegation Token去访问NameNode,而并不用再去请求一次KDC来获取TGT。
当job结束后,RM负责去NameNode把这个Delegation Token销毁。
整个流程如下图:
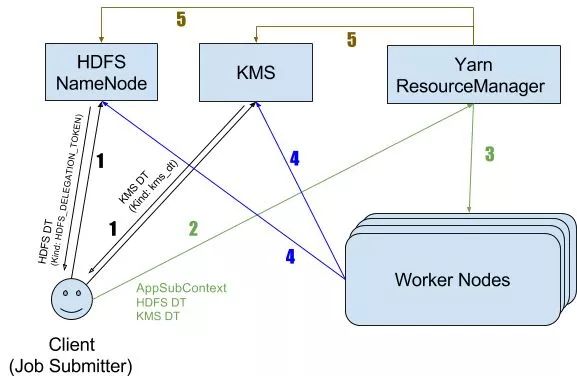
Delegation Token解决了分布式计算任务这种场景下,短生命周期的“子计算进程”导致的Principal泛滥,重复性的给KDC造成大量请求Traffic的问题。 但这种解决方案的代价也是以牺牲了一定的安全性换来的,好在Hadoop Admin对整个集群是可控的。
Q4-S2. long-running的job,ticket会过期,需要处理好。
这个问题是真对Hadoop上的计算任务的,普通的计算任务,time(job生命周期) < time(session-key 过期),但Mapreduce是批处理,是被设计可以跑很久的。加之像Sparkstreaming这种任务,是一直要running下去的,这里就涉及了Kerberos ticket的Renew问题。
这个问题对我们设计分布式系统,并没有什么借鉴之处。在这里提出来,主要是因为ticket的renew,设计很复杂。那么跑在Hadoop上的计算框架,必须要自主去实现这些ticekt Renew的逻辑。
通常很多on-Yarn的非官方Application,在Coding时并没有考虑这些,因此,这会对“部署Keberos”造成很大的挑战。这也是后面我们提到的对Apply Kerberos安全功能到线上的难点之一。
6.小结——Hadoop给我们设计分布式系统提供了哪些经验:
1.在分布式环境下,我们可以做一些tricky的设计,舍弃“三方认证”带来的绝对安全,退化成局部“两方认证”来达到相对的安全。因为用Kerberos来保证绝对安全,实现复杂度太高,在实现时甚至可能引入更多的bug。
2.Impersonate是在链式安全认证模式下,解决Gateway服务器模拟最初用户,访问后端服务器。
3.Delegation Token是一个在分布式环境下,针对大量的计算型短生命周期进程,产生的短生命周期Kerberos Principal泛滥,造成KDC Server DOS问题的解决方案。
Kerberos上线,为什么难?因为整个Hadoop系统需要“重新配置”、“重新分发配置”,客户程序代码也可能需要改变,才能重新跑起来。
这不但需要停机,还可能因为Update,导致启动后进入不稳定的状态。从而会导致对公司线上业务造成很大的影响。
我从Admin & Client两个维度去罗列,把Kerberos上线大致需要做哪些事情,然后自然就能体会为什么难以实施。
Admin side:
每一个Hadoop组件都必须全部停机,重新配置。
所有服务的CONF文件都需要重配,加入Kerberos的安全参数,然后重新分发,再重启这些Hadoop组件。
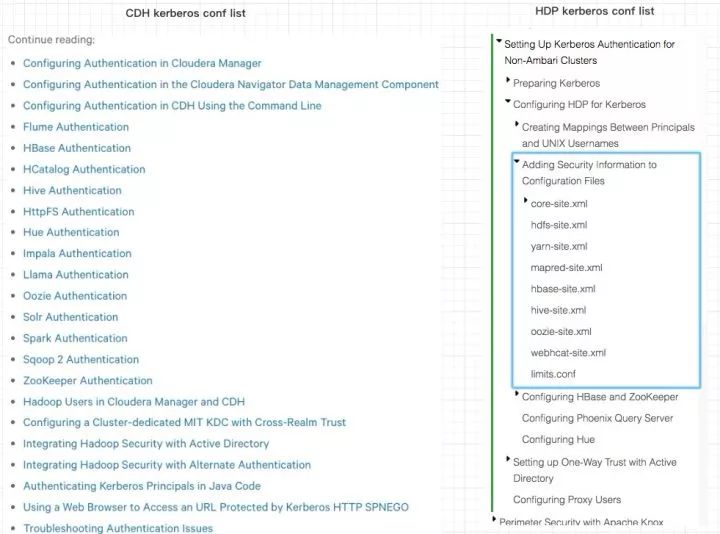
具体的配置步骤,可以参考Cloudera社区,或者Hortonworks社区,我这里截一个图,来证明需要重配的组件有多少。
1.Cloudera : Configuring Authentication
https://www.cloudera.com/documentation/enterprise/5-8-x/topics/sg_authentication.html
2.Setting Up Kerberos Authentication for Non-Ambari Clusters
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.3/bk_security/content/setting_up_kerberos_authentication_for_non_ambari_clusters.html
需要有一个KDC,且必须高可用,且必须与公司内部现有的员工账户体系打通。
HA 是必须的, 否则 KDC会成为 Hadoop 系统的新 SPOF。
KDC 必须和公司员工账户体系打通。公司的个人开发机,以及所有staging/prod机器,其上的linux user/group,在KDC 的数据库里必须存在,否则从这些机器发出的Kinit认证将会不通过。
由于历史遗留问题,很多非个人的账户的文件已经存在于HDFS中,他们的ACL设置可能不正确。那么这些账户的文件在被读取时可能会有问题,需要摸清楚哪些非个人账户需要“预先”在KDC创建,他们的文件ACL设置是否合理。
Keytab文件的分发/管理,也需要有强大的管理工具来支撑。
User side:
所有的Hadoop Client机器Conf都必须重配置,重启。
这会牵扯到“所有的“Data团队、所有Hadoop Client,所有的Application client,这将是一个实施的最难点。
调度系统需要重新配置
Airflow/Azkaban/oozie /以及自研的调度系统,其worker也是Hadoop Client,也需要重配。
On-Yarn的应用,需要重构
我们在前文提到了long running的job是一个问题。正常的生命周期超过Kerberos ticket expiretime的job,也是一个问题。而恰好 MR 和Spark这两个计算层的框架,帮我们解决了这些问题,诸如ticket renew等等。
那么自研发的on-Yarn应用,就要自己来重构Kerberos相关的代码了。
感兴趣的朋友可以读一读Hadoop Apache社区的文档:YARN Application Security
某些公司的MR/Spark程序,也可能跑不起来。因为在没有Kerberos时,可能没有注意ACL的问题,使用诸如 “export HADOOP_USER_NAME=hdfs”这种大锤,那么在Kerberos上线后,这些程序都会出问题,需要重构。
小结:不论管理员/用户,引入Kerberos的代价都及其的高,必然会影响线上业务,必然会使公司的大数据业务shutdown一段时间,且还存在核心pipeline启动不起来的风险,你说这种项目的实施难度得多大? 所以上线难。
退而求其次的解决方案
如果Kerberos这么难以实施,那怎么办?有没有不绝对安全,但相对能简单可实施的解决方案呢?
答案是:堡垒机 + 审计。
堡垒机上部署Hadoop Client,按“组”控制好粒度。
严格配置每个组的用户,不同组的用户不可以登陆到不属于自己Team的堡垒机。严格控制HDFS/Yarn 这种超级用户在堡垒机创建。不让用户"sudo su superuser"。
每个组只部署他需要的Hadoop组件Client Conf,不需要的不给予部署。比如用不到直连ZooKeeper的,就不给他ZK Conf。只连Hive的,就只给他配Hive Conf。
堡垒机审计。
堡垒机是没有办法禁止用户做操作 “export HADOOP_USER_NAME=hdfs"的。但我们可以管理好用户的每一次登陆,管理好用户的历史commands,做到“事后能追查”。
这样能做到把Hadoop用户的活动范围限制在最小的范畴内。
在发生坏事时,可以根据Hadoop的审计日志,查询到是哪个IP干了坏事,然后通过IP找到对应的堡垒机,就可以落实到Tteam。再根据堡垒机的审计日志,可以定位到是哪一次Session,即:谁,在什么时间,操作了什么指令。
Tips:审计就好比:法律是不允许杀人的,但是并不能预先阻止你杀人。而是在你杀人后审判你。因为绝对要防止你杀人,社会成本太高。
除了堡垒机,还有别的土办法嘛?
有,比如Hack NameNode 的代码, /a/b/c 这种三层以内的路径删除操作,来自其它机器的全部过滤掉,只有来自Admin结点的,予以执行。
Hive 的drop table 、Hbase 的删除表也都同理。这种办法看上去很low,但实际上也work的不错。
总结
安全是追求犯罪率的最低化,同时是控制预防犯罪的成本。绝对安全在现实世界并不一定最有意义。Kerberos的过期sessionkey设计,也是追求密钥更新的时间间隔小于被破解时长。
Hadoop使用了Kerberos,但在一些特殊的场景时,Kerberos会遇到性能瓶颈和实施复杂度瓶颈。Hadoop使用“把三方认证退化为局部两方认证” 的Impersonate 和Delegation Token技术顺利地解决了问题。
Kerberos on Hadoop 很难实施。如果实在阻力大,还有一些相对容易的方案可选。
附录:Ceph是一种分布式的对象存储解决方案。它的认证就没有使用Kerberos,而是使用了一种叫Cephx的变种Kerberos协议。Cephx ,authentication protocol #high-availability-authentication。
它把KDC的概念揉进了Ceph自己的组件monitor,避免了SPOF,且Cephx发出的session-key,在所有不同角色的Ceph Component Server之间是通用的。这个设计和Hadoop的Delegation Token有异曲同工之妙。
近期热文
最新活动
以上是关于打赢数据安全攻坚战,从Hadoop-security治理说起!的主要内容,如果未能解决你的问题,请参考以下文章