零基础示例,教你轻松Hadoop中的MapReduce
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零基础示例,教你轻松Hadoop中的MapReduce相关的知识,希望对你有一定的参考价值。
译者:刘旭坤
原文链接:http://examples.javacodegeeks.com/enterprise-java/apache-hadoop/hadoop-hello-world-example/
小象科技原创作品,欢迎大家疯狂转发;
机构、自媒体平台转载务必至后台留言,申请版权。
零基础示例,教你轻松Hadoop中的MapReduce
Hadoop是由Apache软件基金会所管理的一个开源项目,解决的是大型数据集的分布式处理问题。Hadoop由两个主要的部分组成:
分布式文件系统HDFS
用于MapReduce的框架
MapReduce和文件系统可以追溯到谷歌公司曾推出的闭源MapReduce和文件系统,因此Hadoop也可以说是开源版本的谷歌MapReduce。本文中我们将为大家讲解一个简单的字数统计示例来演示Hadoop中的MapReduce功能。在我们开始之前先来认识一下到底MapReduce是个什么。MapReduce是一个软件框架,换种说法也可以叫一个编程的模型。通过MapReduce这种编程模型我们可以在多个系统中同时并行数据的处理工作。顾名思义,MapReduce包括了两个部分:Map和Reduce。
n Map:Map是由map()函数来完成的,基本的功能就是过滤和排序。通过Map处理过后的数据被称为中间结果。在下图中我们可以看到每一个Map任务都是相互独立。
n Reduce:类似的,Reduce是由reduce()函数来完成的。它将Map生成的中间结果进行了合并。
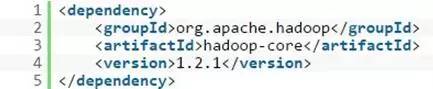
首先我们在Eclipse中使用Maven来创建一个新的项目,然后在pom.xml中添加下面的Hadoop依赖。
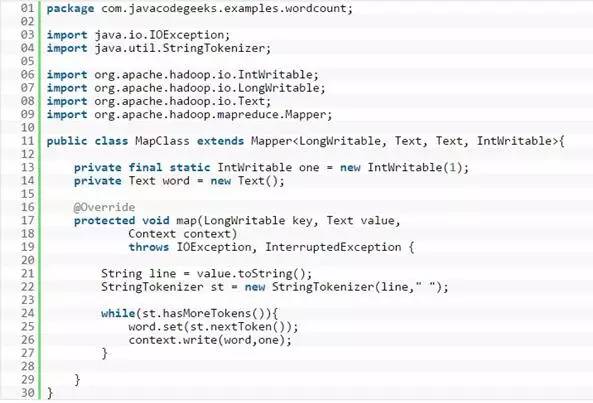
Mapper的目的是将输入的文字按空格分割然后输出一列值为1的键值对,比如<Hello,1>。MapClass类需要继承Mapper类并重写map()方法,下面是MapClass.java的代码:
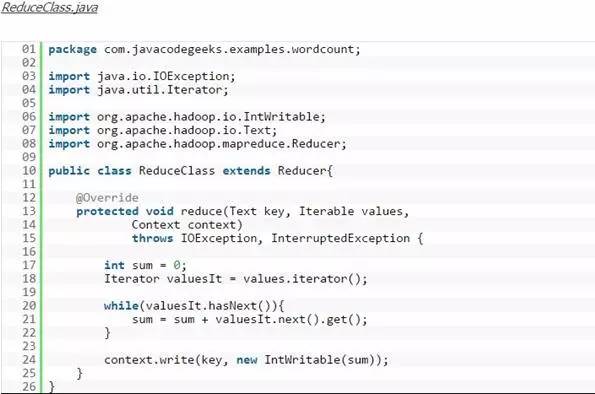
类似地,ReduceClass类也需要继承Reducer类并重写reduce()方法。这里reduce()方法的输入就是map()方法输出的中间结果,把中间结果遍历一遍然后把键值对中的值也就是1加起来就能得到最终的字数了。下面的代码是ReduceClass类:
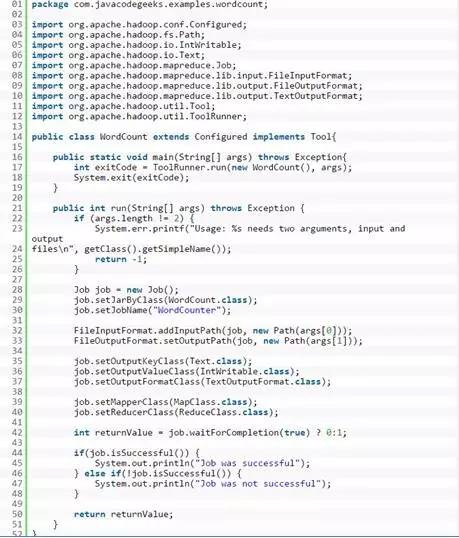
有了MapClass类和ReduceClass类,我们还需要一个WordCount类来调用这两个类,我们的main()方法也在WordCount类中。下面的代码就是WordCount类,运行完毕之后它会通知用户运行是否成功。
测试的话我们可以直接从Eclipse来运行,不过首先我们得有一段文字作为输入。下面这一段是我们用来测试的输入文字input.txt。
This is the example text file for word count example also knows as hello world example of the Hadoop ecosystem.
This example is written for the examples article of java code geekThe quick brown fox jumps over the lazy dog.
The above line is one of the most famous lines which contains all the english language alphabets.
下面我们要在Eclipse中设置参数。因为我们的output.txt在同一目录下所以只放文件名就可以了,如果你的output.txt位置不同那么就得放完整的路径。
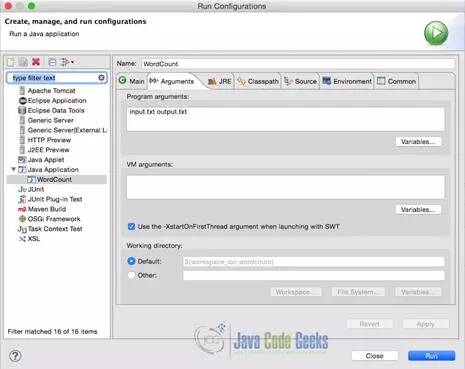
要注意如果output.txt已经存在的话程序会抛出异常。因为我们只是一个示例程序就不考虑这些了。下图是运行的结果:
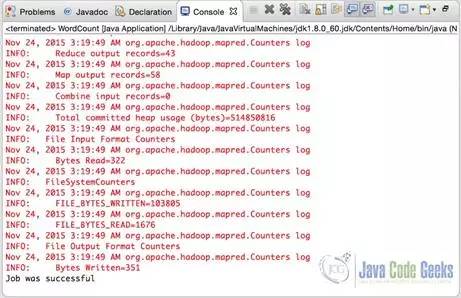
最后一行我们可以看到程序已经成功地执行了。最后输出的output.txt如下图所示:
更多精彩内容,请点击"阅读原文"
以上是关于零基础示例,教你轻松Hadoop中的MapReduce的主要内容,如果未能解决你的问题,请参考以下文章