G-Hadoop: MapReduce用于跨分布式数据中心数据密集型计算
Posted 爱思唯尔Elsevier
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了G-Hadoop: MapReduce用于跨分布式数据中心数据密集型计算相关的知识,希望对你有一定的参考价值。
互联网和WWW的快速增长导致了大量在线信息的产生。此外, 社会、科学和工程应用也创造了大量的结构化和非结构化的信息,需要被处理、分析和关联。如今, 数据密集型计算通常使用现代数据中心体系结构和大规模数据处理范例。Lizhe Wang,Jie Tao,Rajiv Ranjan等学者致力于研究跨多数据中心的大规模数据处理模型。

近年来,很多领域对科学数据大型数据密集型分析的计算要求增高了很多。例如在高能物理领域,大型强子对撞机(LHC)在2010年就产生了13PB的数据。如此大量的数据,被存储在由分布在34个国家的140多个计算中心组成的“全球LHC计算网格(Worldwide LHC Computing Grid)”中。
每时每刻,都有遍布全球的成千上万名科学家在利用“全球LHC计算网格”,希望更进一步洞悉宇宙结构。但在数据处理的过程中,研究人员常常被迫将数据从多个站点复制到运行数据分析的计算中心。由于全球分布式计算中心通过广域网进行互联, 此复制过程单调且效率低下。

Lizhe Wang,Jie Tao,Rajiv Ranjan等研究者认为,用“移动计算”取代“移动数据”是解决这个问题的关键。通过在多个集群使用数据并行处理范式,模拟可以同时在多个计算中心运行,而无需复制数据。

当前数据密集型工作流系统,可用于跨多数据中心的分布式数据处理。在多数据中心分布式计算环境中使用工作流范式,存在着一些限制。考虑到MapReduce范式的应用广泛性,将MapReduce用于跨分布式数据中心的数据处理也是顺理成章,这样就能克服工作流系统的一些局限性。
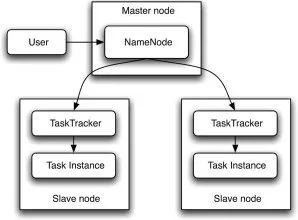
Hadoop MapReduce架构图示
Lizhe Wang,Jie Tao,Rajiv Ranjan等研究者提出了G-Hadoop —— 一种MapReduce架构,可实现跨多个集群的大规模分布式数据处理。
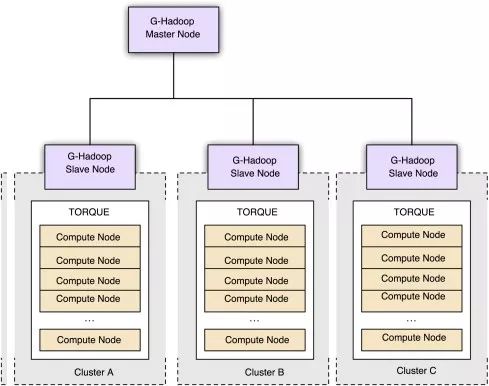
G-Hadoop架构概览
他们提出的G-Hadoop与传统的Hadoop的明显区别:
• 与可在属于单集群的节点上安排数据处理任务的hadoop框架不同,G-hadoop可以跨多个集群的节点安排数据处理任务。这些集群可以由不同组织控制。
• G-Hadoop通过跨多个集群节点复制映射并减少任务,不依赖于单个集群的节点, 因此提供了更有容错性的数据处理环境。
• G-Hadoop 能实现对更庞大数据库的处理和存储节点的访问。
Lizhe Wang,Jie Tao,Rajiv Ranjan,Holger Marten,Achim Streit,Jingying Chen,Dan Chen
英文原文链接:
http://www.sciencedirect.com/science/article/pii/S0167739X12001744
长
按
关
注
微信 : ElsevierChina
微博:@励德爱思唯尔科技
马上前往专题页面获取发表指南,你会发现——发表文章其实并没那么难
以上是关于G-Hadoop: MapReduce用于跨分布式数据中心数据密集型计算的主要内容,如果未能解决你的问题,请参考以下文章