mapreduce工作原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce工作原理相关的知识,希望对你有一定的参考价值。
mapreduce工作原理为:MapReduce是一种编程模型,用于大规模数据集的并行运算。
mapreduce工作原理为:MapReduce是一种编程模型,用于大规模数据集的并行运算。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。

Mapreduce是什么?
MapReduce就是“任务的分解与结果的汇总”,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
参考技术Amapreduce工作原理为:MapReduce是一种编程模型,用于大规模数据集的并行运算。
mapreduce工作原理为:MapReduce是一种编程模型,用于大规模数据集的并行运算。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
Mapreduce是什么?
MapReduce就是“任务的分解与结果的汇总”,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
MapReduce 框架原理MapReduce 工作流程 & Shuffle 机制
【MapReduce 框架原理】
1. MapReduce 工作流程

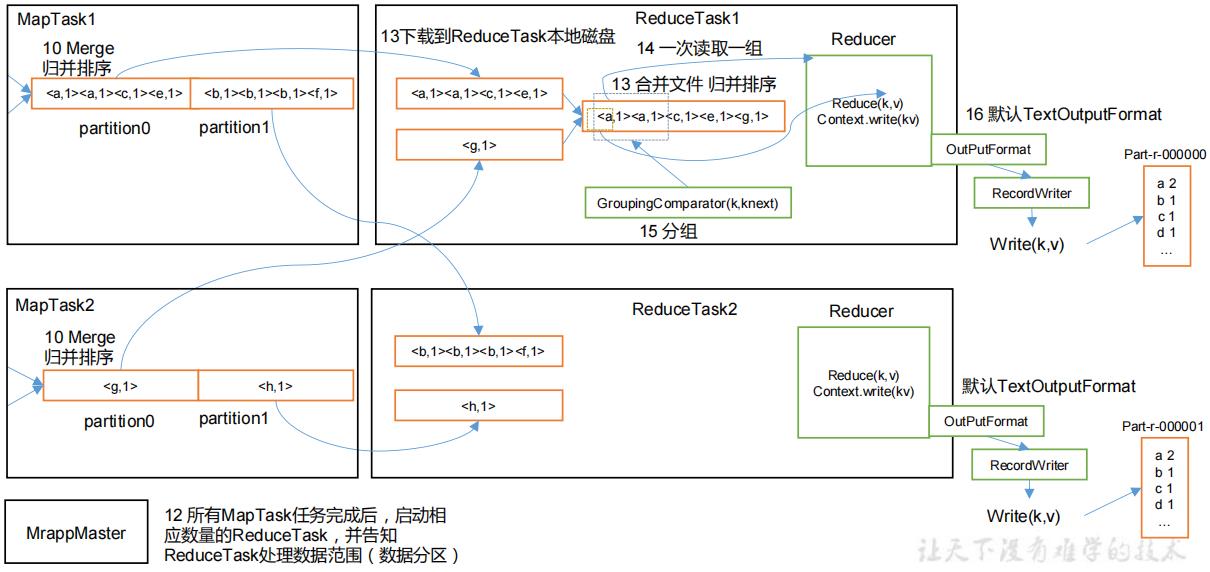
上面的流程是整个 MapReduce 最全工作流程,但是 Shuffle 过程只是从第 7 步开始到第16 步结束,具体 Shuffle 过程详解,如下:
(1)MapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用 Partitioner 进行分区和针对 key 进行排序
(5)ReduceTask 根据自己的分区号,去各个 MapTask 机器上取相应的结果分区数据
(6)ReduceTask 会抓取到同一个分区的来自不同 MapTask 的结果文件,ReduceTask 会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle 的过程也就结束了,后面进入 ReduceTask 的逻辑运算过程(从文件中取出一个一个的键值对 Group,调用用户自定义的 reduce()方法)
注意:
(1)Shuffle 中的缓冲区大小会影响到 MapReduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb 默认 100M。
2. Shuffle 机制
2.1 Shuffle 机制
Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。

2.2 Partition 分区
1、问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
2、默认Partitioner分区
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默 认分区: 是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
2.3 自定义Partitioner步骤
(1)自定义类继承Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
(2)在Job驱动中,设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class);
(3)自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask:
job.setNumReduceTasks(5);
2.4 分区总结
(1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如 果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000;
(4)分区号必须从零开始,逐一累加。
2.5 案例分析
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1); 会正常运行,只不过会产生一个输出文件
(2)job.setNumReduceTasks(2); 会报错
(3)job.setNumReduceTasks(6); 大于5,程序会正常运行,会产生空文件
3. Partition 分区案例实操
3.1 需求
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(1)输入数据

(2)期望输出数据
手机号 136、137、138、139 开头都分别放到一个独立的 4 个文件中,其他开头的放到一个文件中。
3.2 需求分析

3.3 在案例 2.3 的基础上,增加一个分区类
package com.zs.mapreduce.partioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
// text 手机号
String phone = text.toString();
String prePhone = phone.substring(0, 3);
int partition;
if ("136".equals(prePhone)) {
partition = 0;
} else if ("137".equals(prePhone)) {
partition = 1;
} else if ("138".equals(prePhone)) {
partition = 2;
} else if ("139".equals(prePhone)) {
partition = 3;
} else {
partition = 4;
}
return partition;
}
}
3.4 在驱动函数中增加自定义数据分区设置和 ReduceTask 设置
//8 指定自定义分区器
job.setPartitionerClass(ProvincePartitioner.class);
//9 同时指定相应数量的 ReduceTask
job.setNumReduceTasks(5);
package com.zs.mapreduce.partioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.设置jar包
job.setJarByClass(FlowDriver.class);
// 3.关联mapper和reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 4.设置mapper 输出的key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5.设置最终数据输出的key和value类型
job.setOutputValueClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 自定义分区
job.setPartitionerClass(ProvincePartitioner.class);
// 设置分区数
job.setNumReduceTasks(5);
// 6.设置数据的输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\\\software\\\\hadoop\\\\input\\\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D:\\\\software\\\\hadoop\\\\output\\\\outputPartition"));
// 7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0:1);
}
}
4. WritableComparable 排序
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,
如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;
如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
4.1 排序分类
(1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
(4)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
4.2 自定义排序 WritableComparable 原理分析
bean 对象做为 key 传输,需要实现 WritableComparable 接口重写 compareTo 方法,就可以实现排序。
@Override
public int compareTo(FlowBean o) {
// 总流量的倒序排序
if (this.sumFlow > o.sumFlow) {
return -1;
} else if (this.sumFlow < o.sumFlow) {
return 1;
} else {
// 按照上行流量的正序排序
if (this.upFlow > o.upFlow) {
return 1;
} else if (this.upFlow < o.upFlow) {
return -1;
} else {
return 0;
}
}
}
5. WritableComparable 排序案例实操(全排序)
5.1 需求
根据案例 2.3 序列化案例产生的结果再次对总流量进行倒序排序。
(1)输入数据
原始数据

第一次处理后的数据

(2)期望输出数据

5.2 需求分析

5.3 代码实现
(1)FlowBean 对象在在需求 1 基础上增加了比较功能
FlowBean
package com.zs.mapreduce.writableComparable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1.定义类实现writable接口
* 2.重写序列化和反序列化方法
* 3.重写空参构造
* 4.toString()方法
* 序列化:sumFlow -- downFlow -- upFlow--->upFlow -- downFlow -- sumFlow
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
// 空参构造
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 重载
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
// 序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\\t" + downFlow + "\\t" + sumFlow;
}
@Override
public int compareTo(FlowBean o) {
// 总流量的倒序排序
if (this.sumFlow > o.sumFlow) {
return -1;
} else if (this.sumFlow < o.sumFlow) {
return 1;
} else {
// 按照上行流量的正序排序
if (this.upFlow > o.upFlow) {
return 1;
} else if (this.upFlow < o.upFlow) {
return -1;
} else {
return 0;
}
}
}
}
FlowMapper
package com.zs.mapreduce.writableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private FlowBean outK = new FlowBean();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String line = value.toString();
// 切割
String[] split = line.split("\\t");
// 封装
outV.set(split[0]);
outK.setUpFlow(Long.parseLong(split[1]));
outK.setDownFlow(Long.parseLong(split[2]));
outK.setSumFlow();
// 写出
context.write(outK, outV);
}
}
Reducer
package com.zs.mapreduce.writableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
private FlowBean outV = new FlowBean();
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, key);
}
}
}
FlowDriver
package com.zs.mapreduce.writableComparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.设置jar包
job.setJarByClass(FlowDriver.class)Hadoop MapReduce 1.x 工作原理