☞专栏董飞:后Hadoop时代的大数据架构
Posted 软件定义世界(SDX)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了☞专栏董飞:后Hadoop时代的大数据架构相关的知识,希望对你有一定的参考价值。
☞【专栏】董飞:后Hadoop时代的大数据架构
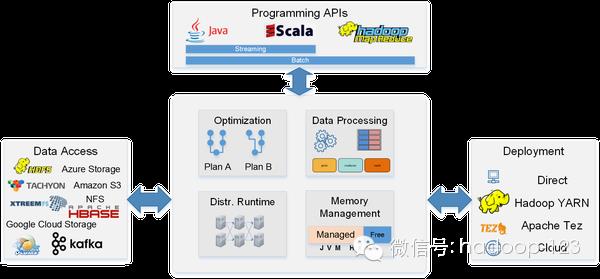
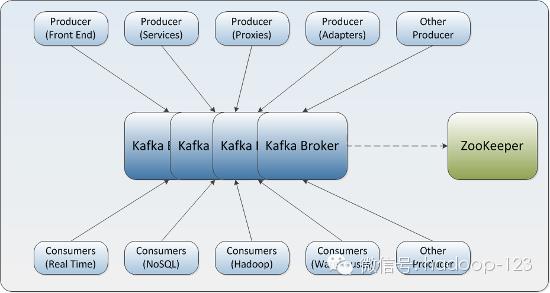
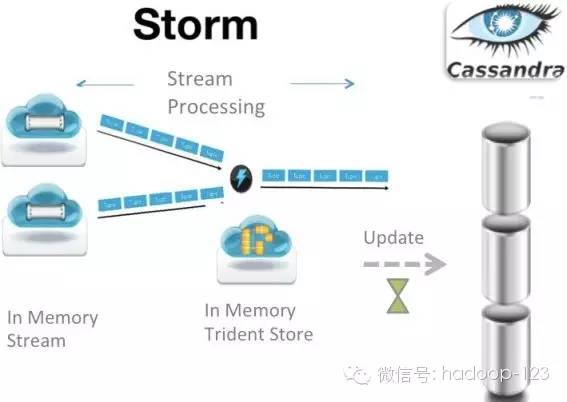
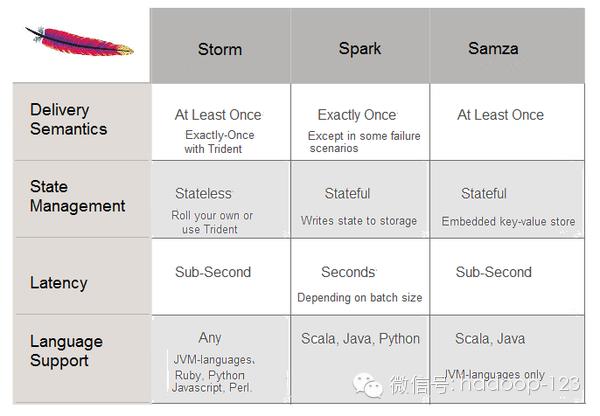
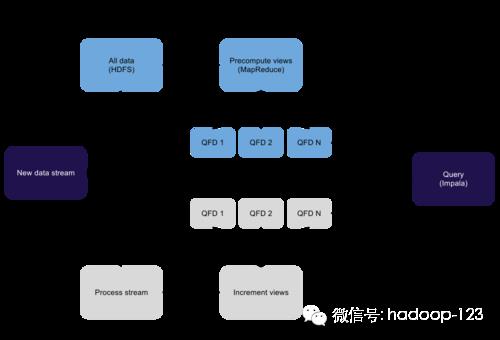
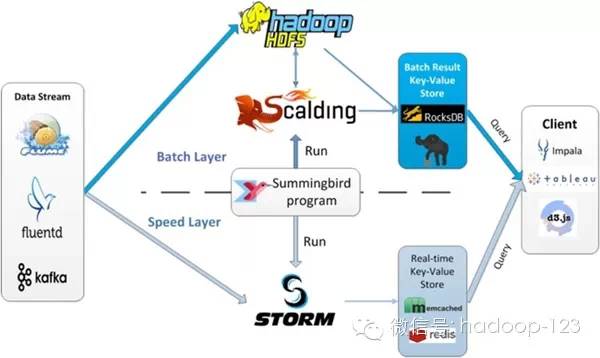

来源:知乎
▌【软件定义世界(SDX)】2014年4月份不容错过的精彩文章: “查看信息”中,回复日期代码即可。 回复“20140406”-->武新:大数据架构及行业大数据应用【大数据100分】 回复“20140301”-->互联网的未来【PPT】 回复“20140426”-->大数据产业地图 回复“20140406”-->《互联网思维“独孤九剑”》读书笔记【PPT】 回复“20140429”-->怀进鹏院士:大数据与产业发展转型【PPT】
回复“20140427”-->部分欧洲国家新一轮工业革命进展
回复“20140430”-->大数据足以引领第四次革命的商业价值
回复“20140408”-->阿里巴巴西湖品学大数据峰会观后感
回复“20140413”-->明天的数字营销分析工具
回复“20140409”-->华尔街分析师选出全球最重要16张图表
回复“20140408”-->颠覆支付行业的创新者RIPPLE
回复“20140410”-->预测零售业未来将发生的十个“神奇”变化
回复“20140403”-->移动支付分析报告【PPT】
回复“20140412”-->传统行业转型必须回归产品本质
回复“20140409”-->医疗行业大数据应用的15个场景
回复“20140403”-->谢国忠:“新经济”幻象:互联网不能拯救中国经济 |
▌【软件定义世界(SDX)】原创文章推荐。
“查看信息”中,回复【 】内数字快速到达。 ★《软件定义世界,数据驱动未来》【001】 ★《2013年世界软件产业发展回顾与展望》【003】
★《平台格局确立,生态体系深化,竞争由硬转软--2013年全球移动互联网发展回顾与展望》【006】 ★《云计算叫好不叫座深层次原因分析》【015】
★《数据驱动新商业世界【PPT】》【016】 ▌软件定义世界(SDX) 软件定义世界(SDX),数据驱动未来(DDF)!
|
以上是关于☞专栏董飞:后Hadoop时代的大数据架构的主要内容,如果未能解决你的问题,请参考以下文章
后Hadoop时代的大数据技术思考:数据即服务
大数据干货基于Hadoop的大数据平台实施——整体架构设计
大数据干货基于Hadoop的大数据平台实施——整体架构设计
如何架构大数据系统 hadoop
庞晓曦:基于Hadoop和HBase的大数据存储实践
属于 Hadoop 的大数据时代已结束