后Hadoop时代的大数据技术思考:数据即服务
Posted csdn研发技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了后Hadoop时代的大数据技术思考:数据即服务相关的知识,希望对你有一定的参考价值。
1. Hadoop 的神话正在破灭
IBM leads BigInsights for Hadoop out behind barn. Shots heard
IBM has announced the retirement of the basic plan for its data analytics software platform, BigInsights for Hadoop.
The basic plan of the service will be retired in a month, on December 7 of this year.
“IBM把BigInsights for Hadoop牵到牧棚后面,只听一声枪响…”
这个是前不久英国知名媒体The Register对IBM 产品BigInsights产品下线的报道。
BigInsights 是IBM在Apache Hadoop上增加了不少IBM分析技术能力后形成的一个大数据分析产品。 在面临近乎2年的前途未卜的窘境之后,IBM终于决定将其关闭。
无独有偶,前不久Gartner的一篇文章也指出 “70%以上的Hadoop部署未能天线的业务价值…”
Hadoop大数据是怎么了呢?
我们从DBMS数据库管理系统的角度,来剖析下常见产品的能力:RDBMS,MPP,Hadoop,NoSQL以及NewSQL。 这几类产品对数据处理的能力各有什么样的特点?
2. 常见几种数据技术比较
我们首先试图对大数据这个被第一滥用的名词来统一一下概念。按照Gartner的说法,大数据具备以下几个特征(3个V):
- Volume: 数据量够大
- Velocity: 数据访问并发够高,够实时
- Variety: 数据的类型多
从另一方面讲,大数据也是数据,对常规数据的管理离不开我们熟悉的ACID事务性来保证对数据操作时候的原子性,一致性,隔离性和持久性。有了这个几个衡量标准以后,我们可以来对上述几个产品列表比较一下。
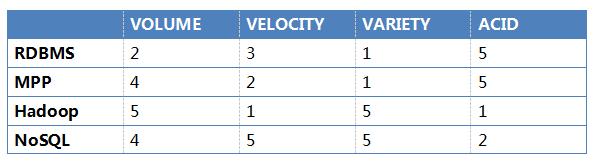
在这里根据4个维度给几种流行的数据库管理技术打分,以5分制为例,5分即最高分,表明具备最佳能力。1分为最低分,表明相对而言能力最弱。其实最近已经有类似于TiDB或者CockroachDB的NewSQL产品出现,但是数据库软件是最为复杂的软件之一, 因为它要满足各种应用的使用场景。如果历史是面镜子,那么最少还要3年左右这些NewSQL的表现才能被足够的评测。所以这里我们暂时略过。
下面我们来解读一下各种数据库的得分原因。
3. 关系型数据库
RDBMS全称关系型数据库(Relational Database Management System)是历史最悠久的数据库类型。关系型数据库以Oracle,SQLServer,mysql,PostgreSQL等为代表,是我们最熟悉的数据库。特点是:
- 单机架构限制,处理数据量有限, 通常在小几个TB以下(得分2)
- 受事务之累,并发不高,但是通常是毫秒级响应(得分3)
- 严谨的关系模型,无法处理非结构化数据(得分1)
- 事务性强,无与伦比(得分5)
4. MPP 数仓
MPP,全称Massive Parallel Processing数据库,通常被用来实现企业的数据仓库和ODS等需求。MPP的产生主要是用来解决关系型数据库的数据量管理能力的问题。MPP数据库通过把数据进行分区分片,并分布到各个横向扩展节点,并由调度节点进行统一管理计算。每一次你执行查询的时候,该查询会被分解为多个子查询并交付给每一个计算节点去做并行的查询。这个架构可以通过增加节点的方式来扩展容量。数据在MPP系统里是分片的(Sharded), 每个节点会存取自己本地的一部分数据。这个较之共享存储(如Oracle RAC)方案来说又有不少性能上的优势。因此大部分MPP系统,如Teradata,Greenplum,Vertica等都采用了这种shared nothing及DAS 直挂存储的架构。一般来说MPP系统都具备完备且成熟的SQL优化器,支持主流的SQL标准,包括地理分析,全文检索以及数据挖掘功能。除了GP之外,几乎所有的MPP系统都是闭源系统,并且一般都是和昂贵、复杂这些词联系在一起的。
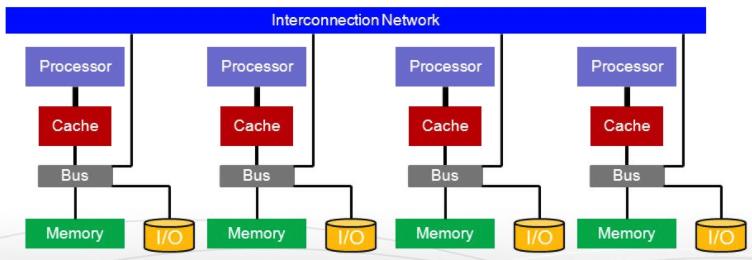
图片来源: Gregory Kesden
MPP理论上是可以无限横向扩展的,但是实际上由于控制节点或协调节点的原因,往往很难超出一百左右的节点数量。所以VOLUME得分为4分而不是满分。MPP系统上主要运行的是分析型的应用场景,并发数往往较低,是为多节点并行分析能力而不是高并发能力优化的,因此VELOCITY上得分为2分。MPP大致也是基于关系模型的,对非结构化数据的处理上和RDBMS基本一样无能为力,因此得分为1。
5. Hadoop
下一个出场的是Hadoop,按时间顺序来排的话。 Apache Hadoop是2007年发布的开源软件。Hadoop是基于Google 公开的MapReduce和HDFS技术研发而成的。它的最伟大之处就是让企业能够以非常廉价的x86服务器把大量的数据管理起来。在那之前,机构需要购买机器昂贵的企业级存储设备来管理海量数据。就从这一点上,Hadoop技术已经为企业带来了很大的价值。这个确实是Hadoop的强处所在。然而,Hadoop的弱点也是一箩筐:安全,数据管理,查询速度,复杂等等。10年的发展,很多这些地方都已经有了比较不错的解决,唯有这个数据查询速度依然是很多Hadoop部署的痛中之痛。这个性能低下的原因,是和HDFS,Hadoop用来存储文件的机制,HDFS,分不开的。HDFS不支持索引,举个例子来说,你想要在词典里找一个不认识的生僻词的发音和释义,为了找到这个生僻词,你可能需要翻遍整本词典,因为你无法使用拼音来检索。在HDFS里面找内容都是通过扫描(SCAN)的方式,也即是从头读到尾来找到你想要的数据。可以想象这种操作的性能如何。
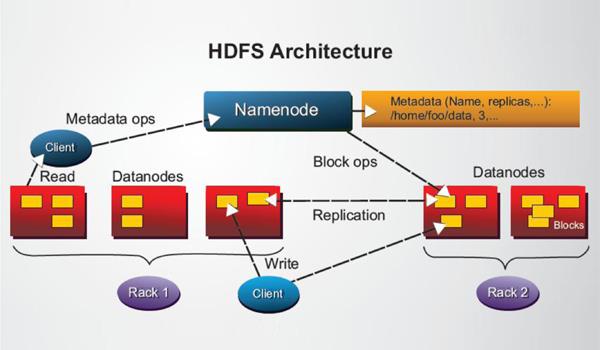
Hadoop的打分情况:
- 基于x86廉价服务器及低端存储海量扩展,轻松支持 TB/PB级数据量,VOLUME得分5分
- HDFS文件存储系统对所有格式的数据照单全收,在VARIETY上面也尽得高分5分。
- 性能方面Hadoop毫不客气的占了倒数第一,但是并发接入能力还是okay,所以给2分
- ACID事务性更是八杆子打不着,得1分。
6. NoSQL数据库
NoSQL数据库是一个争议颇多的话题。首先是NoSQL阵营参差不齐,有以Redis为代表的KeyValue类型,专长于极短响应时间及很高的单机并发能力,适合于缓存、用户会话等场景。 有以宽表列族为模型的HBase、Cassandra,对IoT海量数据持续写入场景有不错支持,但是使用起来比较不友好。有以图关系模型的Neo4J,专注于复杂关系搜索。ElasticSearch 则以搜索起家,在奠定了搜索市场后也视图小觑数据库的大蛋糕。而具有JSON文档模型的MongoDB可以说是NoSQL里面的不折不扣的龙头老大。JSON像XML一样富有表达性,同时又不像XML那样繁琐,用过的程序员基本都说好。由于各种NoSQL数据库差异太大,很难拿出一个抽象模型来代表NoSQL,我们下面就用DBEngines上面持续多年排名NoSQL第一的MongoDB来说事。

MongoDB 在很多方面和Hadoop有相似之处:都是基于x86的分布式数据库,都是schema-on-read,支持结构化和非结构化数据类型等等。以至于很多人都以为MongoDB就是和Hadoop一样用来做大数据分析场景。事实上MongoDB的一贯定位都是OLTP数据库,以联机交易为主要适用场景,如IoT,CMS,Customer data,以及Mobile/Web等低延迟交互式应用。MongoDB的扩展能力可以支持PB级别的数据量(百度云)以及每秒百万+的混合读写并发处理能力(Adobe)。 正因为如此它在VOLUME、VELOCITY、及VARIETY上面都获得了较高的得分(分别为4,5,5分)。它的短板就是事务性,ACID四项中,Atomicity 目前可以支持文档级别的的原子性。一个文档可以很复杂,但是针对单个文档内所有写操作,包括子文档,可以享受原子性的保证。MongoDB不支持多文档或者多集合之间的原子性,但是由于文档模型下多表操作已经转换成为单表操作,所以对多表原子性的需求已经大大降低。Consistency一致性方面,MongoDB默认只使用主节点做读和写来保证数据的读写一致性。Isolation 上MongoDB支持到了第二级别:提交读(Read Committed)。 Durability持久性反而是MongoDB的强项,一份数据会被准实时的同步到其他节点上,从而很大限度上保证了数据的不丢失性。所以在事务上给了MongoDB 2分。
7. Hadoop:局限于大数据分析场景
如果我们用一个雷达图来表示各类数据库的能力,我们可以直观的看到各种技术的覆盖面。面积越大,则表示可以适用的场景越多。
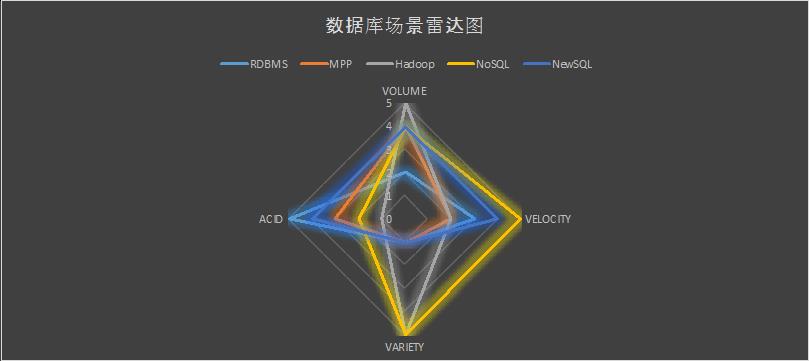
我们发现Hadoop其实覆盖的面积并不是最大的,虽然大家之前都被教育过这个庞大的生态系统可以包治百病。现在我们可以开始理解一些为什么Gartner会说有70% Hadoop用户感觉到并没有获得期望价值。Hadoop其实擅长的就是对海量数据的离线分析(Offline Analytical),HDFS这个文件系统的设计就决定了这一点。这种技术特性适合用来做趋势分析,用户行为挖掘,机器学习,风险控制,历史数据留存等一系列分析场景,用来辅助商业决策。
但是企业今天对数据的需求,何止是分析型一种?
8. NoSQL: 操作型大数据之首选
我们说大数据的价值体现方式有不仅仅是分析型,还有一种同样重要的就是在线操作型(Online Operational)。 在线操作型(Online Operational)数据场景则是我们耳熟能详的企业机构日常生产的交易数据,如用户,表单,订单,库存,客服,营销等。这些数据使用的特点就是交互型,低响应延迟。原来这些系统数据各自为营的时候普通关系型数据库可以处理,但是在大数据时代当我们需要把这些操作型数据,甚至包括5年内所有数据都要提供出来供用户快速访问的时候,或者当传统大型企业突然要面向数百上千万最终用户的移动APP访问需求的时候(如银行业,航空业等),这些就需要一个在线大数据解决方案来实现了。 而Hadoop大生态系统号称是大数据问题大包大揽, 但是动到交互式查询或者更新的时候就捉襟见肘了。Hive, Hbas, Impala等一系列解决方案也都未能有效解决对数据活用的迫切需求。
操作型大数据的两大关键技术需求:数据量大,响应迅速及时。
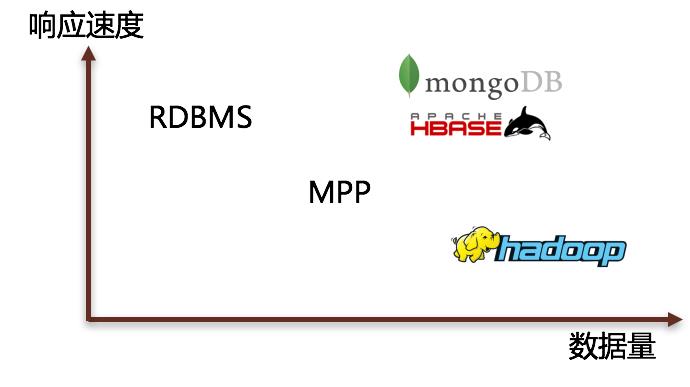
从这两个维度可以看出,以MongoDB或者HBase之类的 NoSQL更加适合用来做操作型大数据平台的场景。
9. MongoDB vs. HBase
事实上HBase正式作为一个NoSQL通常是Hadoop生态系统里用来支持操作型大数据的实时读写需求的。可惜HBase 是个扶不起的刘阿斗,跟着Hadoop的大旗沾了不少光,用起来问题一堆:
- 原生不支持二级索引,只能通过主键访问。社区实现的二级索引功能支持和数据更新有时延,导致头疼的一致性问题
- 宽表模型概念拗考,难于理解并且要求实现建模,不够灵活
- 数据类型低级,只支持比特流,开发很不友好
- 支持程序语言种类少(Java,Thrift, RESTful API)
- 集群结构复杂,有8种不同类型节点
- 无一致性快照功能
- 需要定时compact,对持续读写场景影响很大
因为这些原因,HBase只能在真的是超级大量数据的场景下才值得去忍受着种种不便去使用。
和HBase相比,MongoDB也有一些自己的不足:
- 多表事务还在研发中,导致对原子性要求较高需要回滚的时候只能通过变通手段来实现,增加了开发复杂度(所有NoSQL基本都不支持事务)
- 常为读性能优化而鼓励冗余,但是又不提供这些冗余数据变化时候的自动同步
但是MongoDB在取悦开发者,提高开发效率上可是做的淋漓尽致:
- 支持数十种程序语言
- 有最大的开发社区
- JSON文档模型是个程序员都懂,API式管理数据库,非常自然
- 支持二级索引,关系型数据库的复杂查询基本都能支持
- MEAN stack,全JS开发
- 无须ORM,减少服务层和持久化层的摩擦
- 动态模型,无须显式建模,适合快速开发
- 傻瓜式水平扩展
正是这些原因,DBTA 2017年的“读者最喜欢的数据库”里面,MongoDB傲视群雄,夺得了桂冠。

10. 后Hadoop时代: 数据即服务
今天的企业在其数字化转型、双模IT及企业上云策略下,纷纷在重新审视企业的平台级数据库产品策略。企业已经大手笔投入了大量的资源构建基于Hadoop的数据湖,但是由于Hadoop本身特性所限,很多部署变成了 “数据垃圾堆”(Data Dump),空有数据,但无法实现价值。企业真正需要的是一套在线操作型大数据解决方案可以满足:
- 汇聚来自各个独立隔离系统的客户、行销、生产等数据,提供360度统一视图
- 海量的性能扩展来应付日益增加的数据量及业务需求
- 提供秒级数据API 服务来驱动实时面板和快速应用开发
- 大规模减少ETL流程,降低成本
这种方案应该充分企业已经投入的Hadoop体系架构,但是在此之上铺设一个以低延迟高并发支持灵活API为特色的DaaS(Data as a Service)数据即服务层。
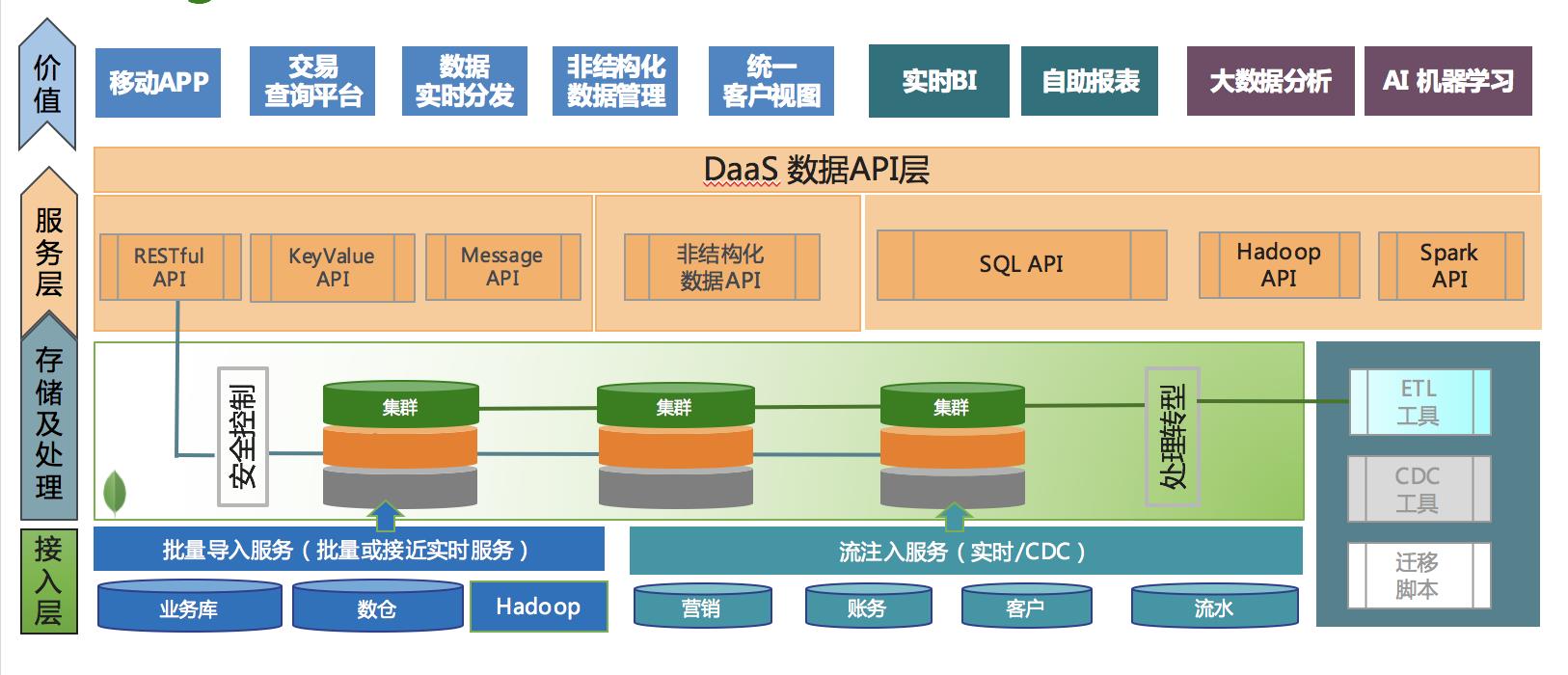
数据即服务就是一种操作型大数据平台的具体体现。这种基于MongoDB的架构的优势在于:

除上述之外,基于分片机制的自动扩容的机制更可以支持数以百TB级的业务数据量;异构数据库实时同步工具可以把来自于数十个业务系统库内的数据同步到数据服务层,并提供秒级的数据一致;在同步过程中实现数据模型转换,快速搭建服务;批量方式或者连接器方式直接接受来自Hadoop集群的分析结果,如个性化标签及推荐信息等,提高Hadoop的可操作性 等等优势。
RBS银行在2015年就开始实施了这样的DaaS架构,短短两年时间,RBS声称已经获得了以下的价值:
- 降低的成本:数百万欧元的Coherence及Oracle商业授权的节省
- 简化的技术栈:一套方案已经支持了数十个数据应用
- 开发加速:新应用上线时间从12个月到数个星期
与此类似的成功案例还有巴克莱银行,Vodafone电信公司等,均是在其数字化转型中经过审慎评估,选择了操作性强,易用性高,分布式能力可靠的MongoDB作为其新一代数据服务平台。
11. 结语
每一种技术都有它的应用场景,在这篇文章里我们想要讨论的是一种操作型大数据解决方案,所以我们花了不少笔墨在NoSQL并认为MongoDB是一个非常不错的选择。NewSQL或许会是一个潜在的选择,如果不是因为现在它还没发展成熟。况且,NewSQL对半结构化、非结构化数据的需求支持估计也还是无法很好满足, 所以我们拭目以待。
最后,在做一个大型决策的时候,我们要充分考虑到企业对技术能力的需求,把需求列出来,然后对照数据产品各自的长短板,有理论有方法的进行选型,并对最后2-3个选择进行POC验证,最终确定合适的方案。
声明作者为MongoDB从业人员,虽然文章尽可能从技术的角度探讨问题,难免有偏颇之处欢迎反馈。
作者:唐建法,MongoDB官方首席架构师,Mongoing中文社区联合发起人。
附:Mongoing中文社区将在2018.01.07在北京举办MongoDB年终盛典。邀请了来自于官方技术大牛WiredTiger引擎作者Michael Cahill 及国内外著名嘉宾,点击此处报名可获限量免费门票。
PS:最后给大家推荐一个数据库在线峰会,嘉宾来自阿里巴巴、腾讯、微博、网易等多家企业的数据库专家及高校研究学者,将围绕Kubernetes、MySQL、PostgreSQL、Redis等热点数据库技术展开。峰会详情页:http://edu.csdn.net/huiyiCourse/series_detail/74

以上是关于后Hadoop时代的大数据技术思考:数据即服务的主要内容,如果未能解决你的问题,请参考以下文章
深度解读大数据3.0—— 后Hadoop时代大数据的核心技术