干货:如何将Hadoop存储容量提升4倍?
Posted 首席数据师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货:如何将Hadoop存储容量提升4倍?相关的知识,希望对你有一定的参考价值。
本文主要介绍如何通过Federation使用多个独立的Namenodes Namespaces水平扩展命名空间。Namenodes彼此独立,互不通信,可以共享相同的Datanode存储。
在Hadoop 1.0中,HDFS的单NameNode设计带来诸多问题,包括单点故障、内存受限制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等。为了解决这些问题,Hadoop 2.0就引入了基于共享存储的HA解决方案和HDFS Federation,HDFS Federation是指HDFS集群可同时存在多个NameNode,这些NameNode分别管理一部分数据,且共享所有DataNode存储资源。
Apache Hadoop分布式文件系统(HDFS)具有高度可扩展性,可支持PB级群集。但是,整个命名空间(文件系统元数据)存储在内存中。因此,即使存储可以水平扩展,命名空间也只能垂直扩展,它受限于单个NameNode进程可存储的文件、块和目录的数量。
本文主要介绍如何通过Federation使用多个独立的Namenodes/Namespaces水平扩展命名空间。Namenodes彼此独立,互不通信,可以共享相同的Datanode存储。Federation和Namespaces可以为整个集群提供可伸缩性,Federation增加了对Namespace水平扩展的支持;添加更多的NameNode,增加集群的聚合读/写能力和吞吐量;用户和应用程序可以通过Namenodes隔离。
1、示例
Federation在可伸缩性、性能和隔离方面的优势为它创建了许多用例,本文仅列举一些简单示例。
1.1 HIVE ON FEDERATION
Hive将表数据组织到分区中以提高查询性能,它将分区存储在不同的位置,这为在不同命名空间中存储、管理和配置hive数据提供了机会。使用federated集群,我们可以将不同的表存储在不同的命名空间,或者将同一个表的不同分区存储在不同的命名空间。
例如,我们可以将不经常访问的数据归档存储到单独的命名空间,并将当前频繁使用的数据保存在单独的命名空间,这将提高服务于当前数据命名空间的性能效率,并减少负载。
假设我们一年有一个分区hive表,我们希望将2000年以后的所有数据存储在一个命名空间中,将其余数据存储在一个命名空间中,这就可以通过federation实现。
下图显示了 NSI中Students 表year=‘2018’分区下的数据。
如果想在NS2中存储1990年的记录,我们必须改变表格以将其位置设置为NS2。

将表的位置更改为新命名空间NS2之后,我们可以将数据插入到所需的分区中,现在将在NS2中创建分区。
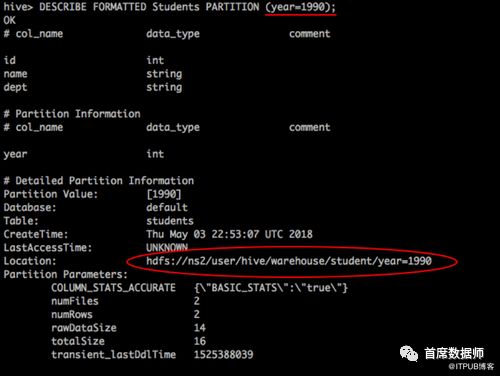
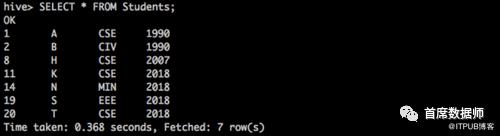
我们可以在同一个查询中执行跨越不同命名空间的多个分区操作。例如,表上的“SELECT *”将从不同命名空间的分区返回记录。
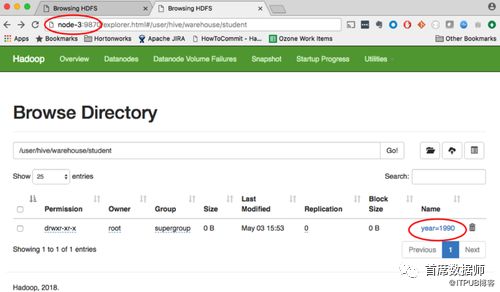
下图显示了在nameservice NS1(在node-1上运行的namenode)中存储的2007和2018年的hive分区数据。
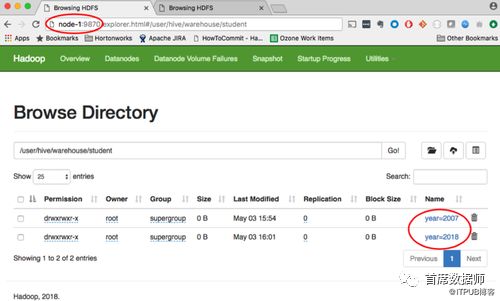
1990年的归档数据存储在NS2中(namenode在node-3上运行),如下所示:
1.2 应用程序隔离
假设我们需要运行一个较庞大的应用程序,它可能会占用Namenode上的大量资源,这很可能导致其他应用程序延迟。通过federation,我们可以将这些应用程序移动到不同的命名空间。
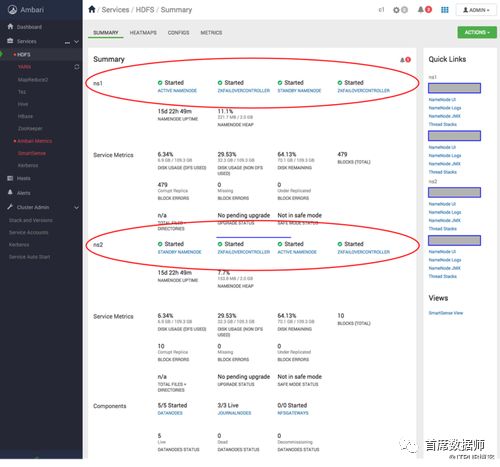
2. AMBARI概述
Ambari中的federated集群视图如下所示,这两个服务将各自具有相应的组件和度量信息。其他组件(如Datanodes和Journalnodes)将由这两个服务共享。 如下所述,启用federated所需的所有配置更改都由Ambari自动完成。
3.配置更改
要启用federated并在集群中具有多个命名空间,需要在hdfs-site.xml中进行一些配置更改。 如果使用Ambari安装federated集群,则会自动设置以下配置。但是,学会如何通过页面配置federated是有帮助的,以下是具有两个Nameservices集群的示例- NS1和NS2。
3.1 NAMESERVICEIDS
使用逗号分隔的NameserviceID列表将此配置添加到hdfs-site.xml。

3.2 NAMENODEIDS
对于具有HA设置的Nameservice,我们需要为属于该Nameservice的Namenode指定NamenodeID。这是通过将NamenodeID列表添加到与名称服务ID一起使用的密钥dfs.ha.namenodessuffixed中来完成的。

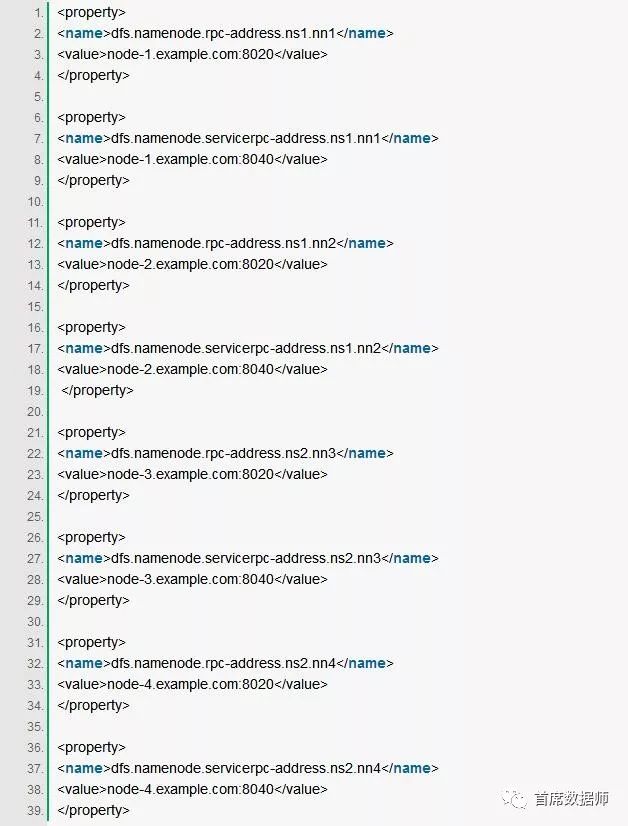
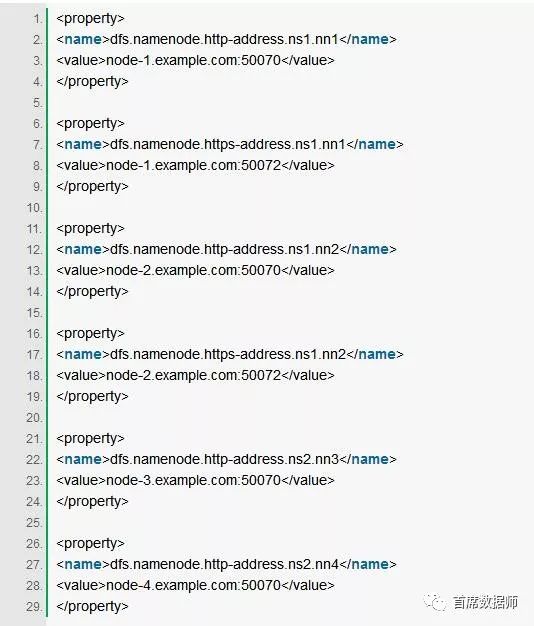
3.3 RPC ADDRESSES
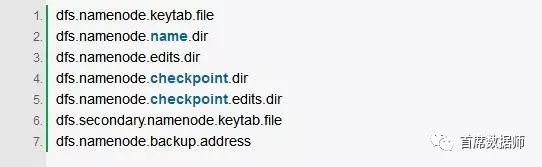
3.5 其他NAMESERVICE特定密钥
通过使用NameserviceID后缀键名,可以为每个名称服务配置以下键:
4.集群设置
federated集群中的所有Namenode应具有相同的clusterID,应使用以下命令格式化一个namenode,选择唯一的clusterID,使其不与环境中的其他集群冲突。如果未提供clusterID,则会自动生成唯一ID。
集群中的所有其他名称节点必须使用与第一个namenode相同的clusterID进行格式化。
如果向现有集群添加新名称服务,则应使用与现有名称节点相同的clusterID格式化新名称节点,可以从Namenode中的VERSION文件检索clusterID。
以上是关于干货:如何将Hadoop存储容量提升4倍?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch大文件检索性能提升20倍实践(干货)