B站容量管理:游戏赛事等大型活动资源如何快速提升10+倍?
Posted TakinTalks稳定性社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B站容量管理:游戏赛事等大型活动资源如何快速提升10+倍?相关的知识,希望对你有一定的参考价值。
一分钟精华速览
当成千上万的服务器都处于低利用率时,就意味着巨额的浪费,良好的容量管理可以帮助消除某些“最后时刻”的临时应急式的盲目或者超量采购。除了成本合理控制方面,容量管理还要预估对客户可能产生影响的业务发展和风险变化。
B站在降本增效大背景下,从业务视角对整体容量做了可视化管理,本文详细描述了其容量管理的背景、思路及成效。

作者介绍

哔哩哔哩资深SRE专家 张鹤
TakinTalks社区专家团成员,2020年加入B站,先后负责主站/直播/OGV/推广搜相关的SRE工作。深度参与多活、活动保障、混沌工程、容量治理相关的建设,并主导容量管理平台、混沌平台的架构设计和落地。曾负责B站S赛、跨年晚会、拜年祭等相关活动的基础架构保障工作,目前主要负责推广搜业务的稳定性建设、PaaS治理。
温馨提醒:本文约4500字,预计花费9分钟阅读。
后台回复 “交流” 进入读者交流群;回复“2252”获取课件资料;
背景
对于B站来讲,我们最大的三个活动是S赛、拜年纪、B站跨年晚会。在用户增长的背后,SRE团队做了非常多的事情来保障业务连续性,比如多活、混沌工程等等。
今天换个角度聊聊——“容量管理”,B站为什么要做容量管理的平台?我们的容量管理体系是怎么设计的?平台侧和业务侧我们是如何去运营、让工作变得“可视化”的?我也将结合容量管理平台在S12赛事中的实际应用,来分享“赋能业务”的一些经验。
一、为什么B站要做容量管理?
在做容量管理之前,B站面临了几个很明显的痛点,如下图所示。

除了需要解决未知的容量风险,在提倡“降本增效”的大背景下,提高资源利用率,制定合理的、有数据支撑的预算决策也非常重要。
而此前,B站在大型活动中的容量决策,比如S9、S10等,并没有沉淀下来可供S12参考的相关数据,系统本身容量是否足够、是否需要扩容、应该扩容多少等等,少有容量数据支撑。另外,全年的预算制定也迫切需要参考容量数据。
二、B站容量体系是如何设计的?
2.1 不同角色的诉求
基于上述的痛点,我们计划做整个容量体系的设计,其中不同的角色关注的流量指标其实不太一样。比如:
研发部门:关注是否有足够资源,能扩容、能发布即可。级别比较高的研发Leader可能更关注整个部门的资源使用率、部门的成本是否合理等;
平台:更关注平台的售卖率、资源Buffer、资源使用率,以及其他降本增效的工作;
SRE:核心关注稳定性,还需要提升总体资源的使用率,实现降本增效的大目标;
成本部门:更关注账单、成本、预算、资源使用量等,即节省整体费用。
2.2 容量体系整体设计
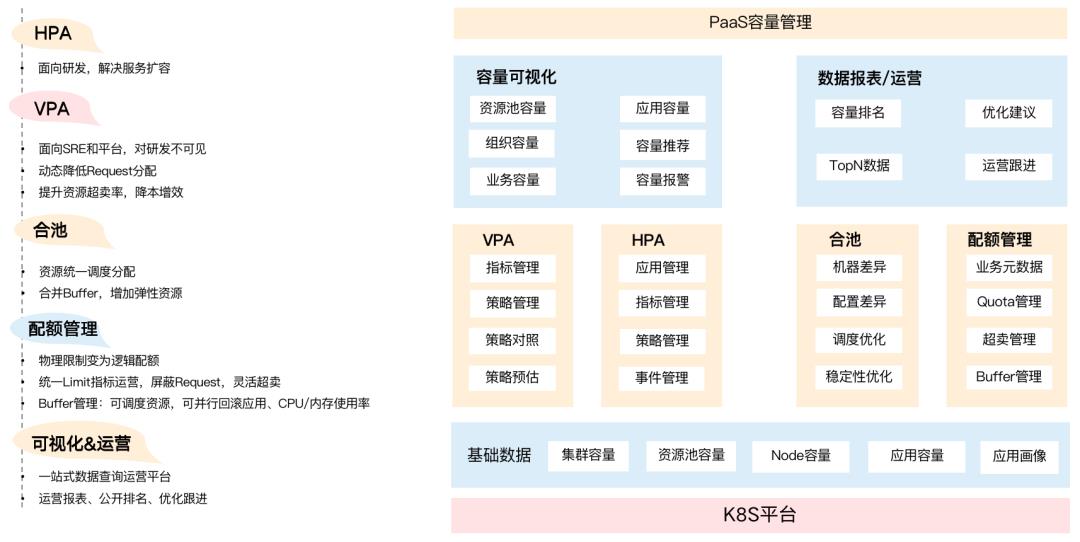
从下往上看,最下层主要是基础数据(基础容量),比如机器、资源池等偏向云底层的层面。SRE和平台更多要感知到集群的容量、资源池的容量等到底怎么样,无论资源池如何超卖或者调控,前提是整体底层的资源使用一定要在安全水位。
在基础容量之上,我们构建了一套基VPA的伸缩策略,以及基于HPA 的弹性扩缩实例的策略。还和业务的资源池做了合池,合池后可能就会面临一个问题,即都在一个大池子里,如何控制每个业务方使用的资源?此时,就需要基于业务做配额管理,即管控每个业务能使用多少资源。
在更上层,我们还提供了一套容量可视化以及可运营的数据,提供给业务做支撑,提高业务团队的效率,包括基于业务部门的组织容量、容量事件等,比如容量运营周报,将不同的部门的使用率公开排名,根据数据提供优化建议等,这部分我将在后面详细地介绍。
三、容量运营与可视化如何帮助业务解决问题?
3.1 基础容量
基础容量是整个容量体系的基础,上文提到基础容量我们更关注集群、资源池、 node 以及一些应用维度的容量报表,如下图所示。
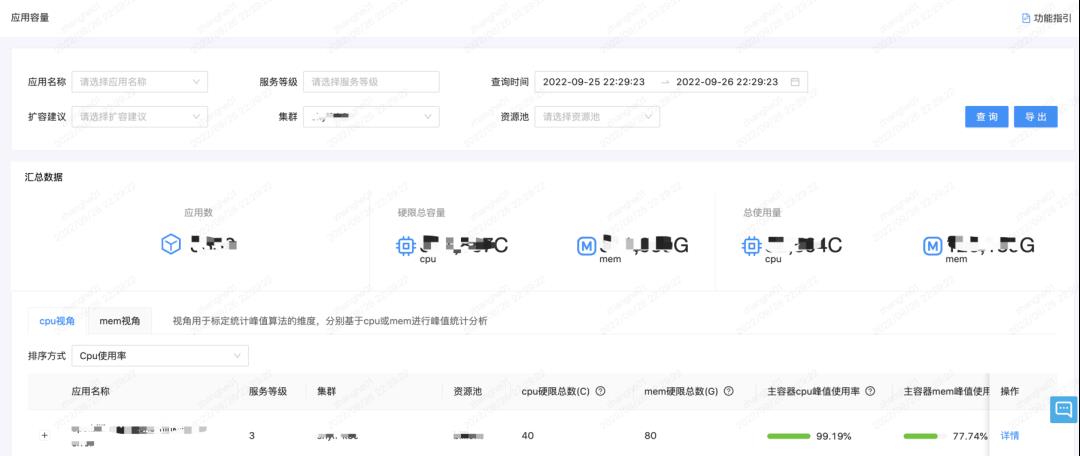
集群:关注集群容量水位和超卖率;
资源池:关注资源池容量水位、超卖率、资源冗余度。资源使用率决定了我们是否需要及时采买机器、判断是否能承载更多业务;
Node:关注Node资源水位、Node超卖率,因为超卖会有热点带来的压力,所以对Node做了使用率相关的报表;
应用:关注使用量、使用率、实例数、单实例容器数等。业务比较关注应用层面的数据的,比如,服务是否是单点的,因为单点代表如果一台物理机挂了,恰巧服务在这台物理机上,此时服务会短暂不可用,对于核心业务来说是不能被接受的。
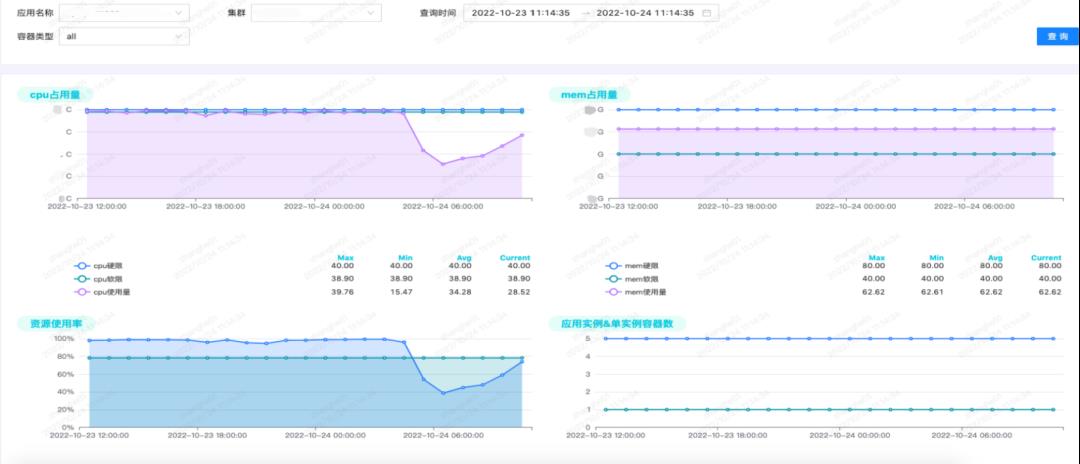
基于这些指标,我们做了一些可视化的界面,与对外监控系统 Grafana 数据默认存储 2 周不同的是,我们整个容量平台的数据是持久存储的,目前已存储接近两年的数据。
3.2 业务组织容量
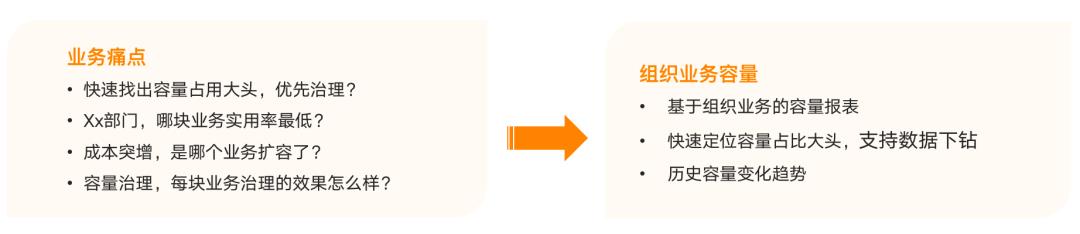
在降本增效的背景下,如何帮助业务去解决问题?业务侧一般更关注如何找出哪些服务占用了较多容量、哪块业务的资源使用率比较低可以缩容、成本突增或者使用突然增多到底是哪个业务导致的、业务治理或者架构整合后到底治理效果如何等等,需要比较直观的界面,能帮他们了解全局。
所以基于以上几点,我们做了基于业务组织的容量报表,如下图所示。
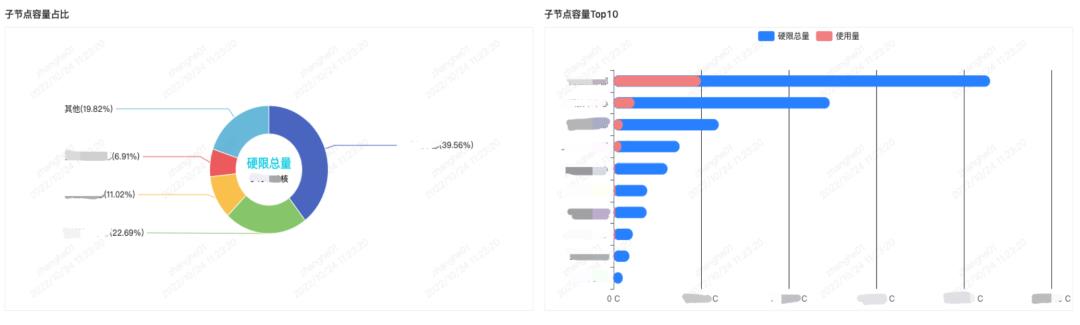
以B站直播业务为例,直播作为一个大部门,假设整体容量使用率是 40%,想要提高使用率,通过直观的可视化报表可以看到直播大部门下,分支业务例如营收,会有送礼、抽奖之类的服务,发现其资源较多且使用率低时,业务团队就能依据可视化报表的信息,提前做治理从而获得更多的收益。
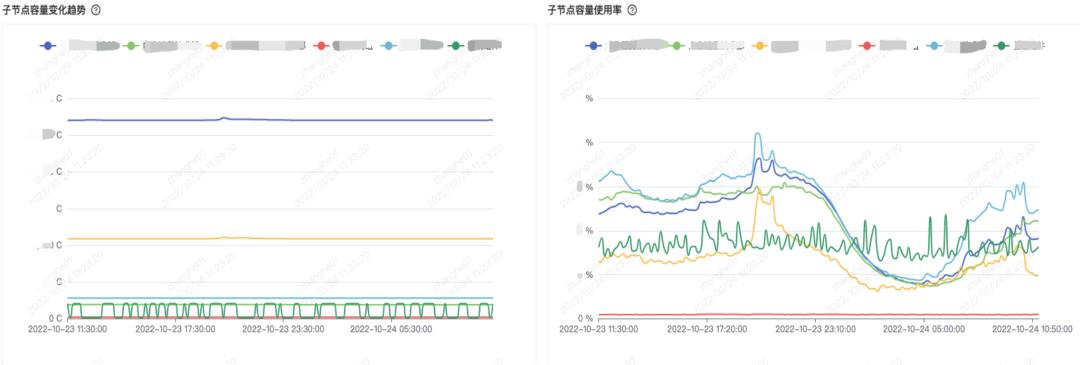
同时,能够基于趋势图,看到直播业务下哪些业务突然占用了较大容量,比如新业务场景、研发或者业务突然扩容等,并且支持数据下钻,可以下钻到营收业务下,了解到底是抽奖还是送礼业务引起的变化。
3.3 容量事件
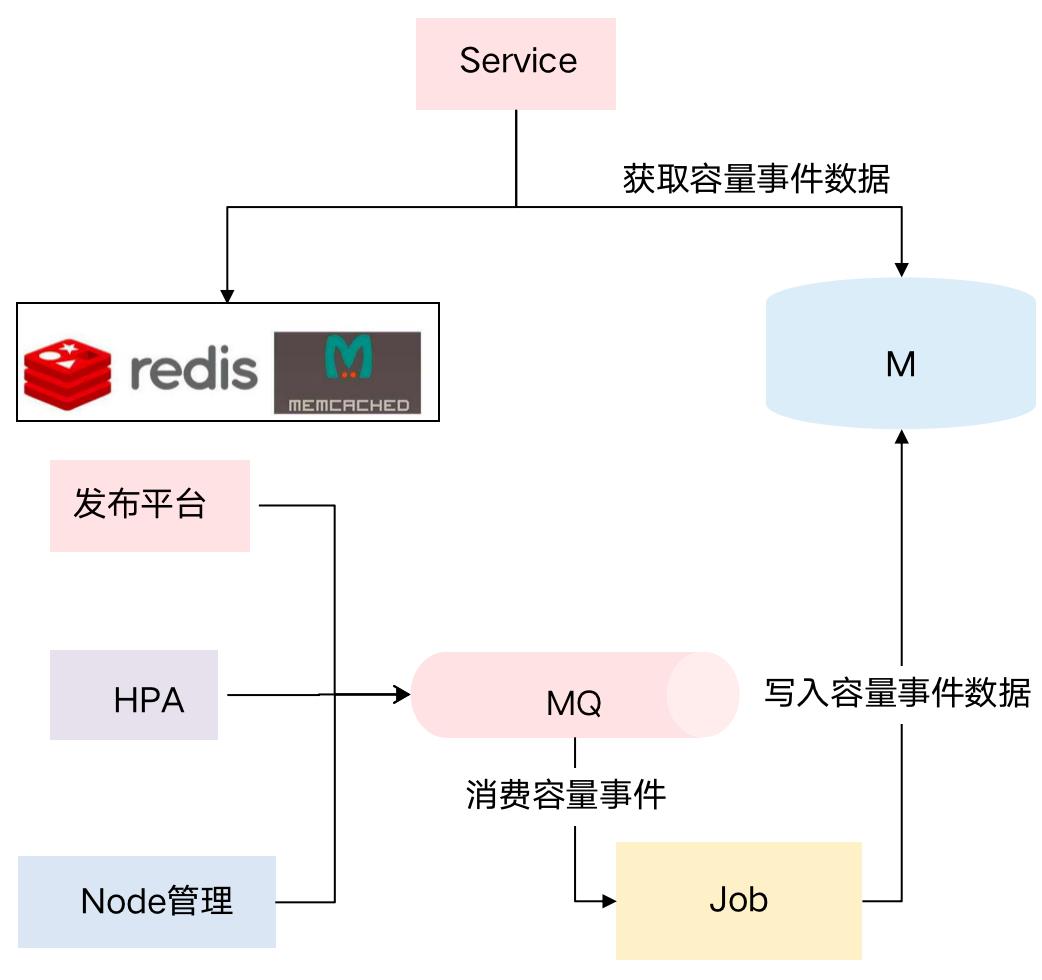
从事件源上看,能引起容量变化的事件有很多,其中包括发布平台/HPA变更平台/Node管理,在发布平台里,研发可以扩容或新增服务,以及修改容量配置等,所以发布平台会导致容量的变化。另外,HPA扩缩容、Node物理机新增或删除等,也会导致容量的变化。
所以我们内部对接了各种容量变更的平台,做了容量事件相关的能力,当一个业务发现整体资源使用变化很多,此时能通过容量事件快速定位事件源,及时感知容量风险,并追溯容量变化的根因。
3.4 容量周报
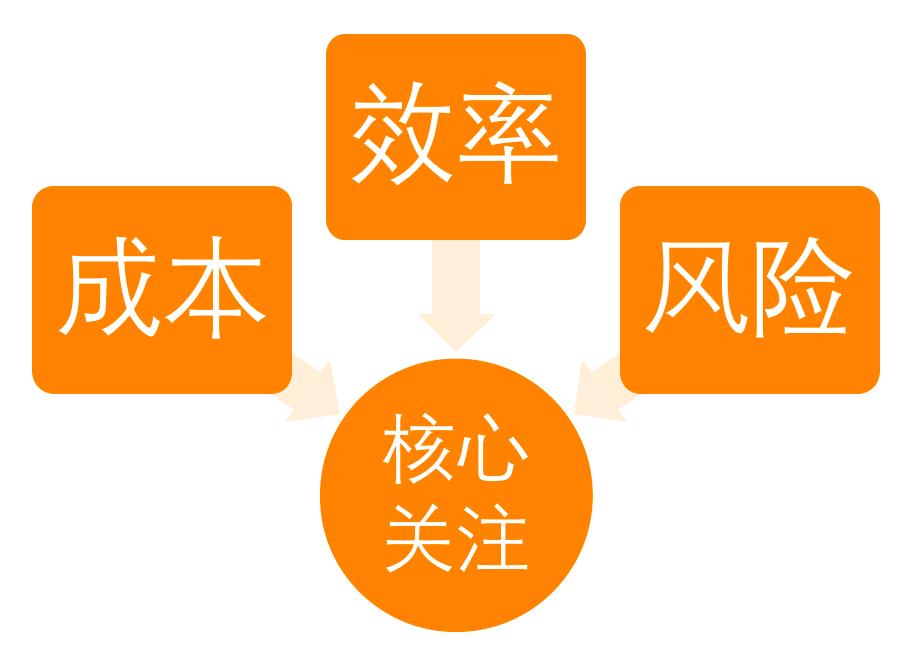
容量每周都在发生变化,所以我们平台做了周报的分析,从成本、效率、风险这三个核心出发,业务部门和平台方的周报关注点差异较大。
3.4.1 部门容量周报(业务侧)
业务侧周报核心关注以下4点——
整体资源容量,资源使用率,环比上周变化。即和上周比较,资源使用率增加或减少了多少。
应用容量Top。即哪些应用占用了较多资源,方便业务快速感知大头资源,提高降本优化效率。
风险应用Top(优先展示L0/L1应用)。本部门是否有风险较大的应用,如有使用率较高的核心服务,可以提前扩容。
一周容量变化应用Top。即新增了哪些服务、哪些服务做了扩缩容、下线了哪些服务等,做到一目了然。
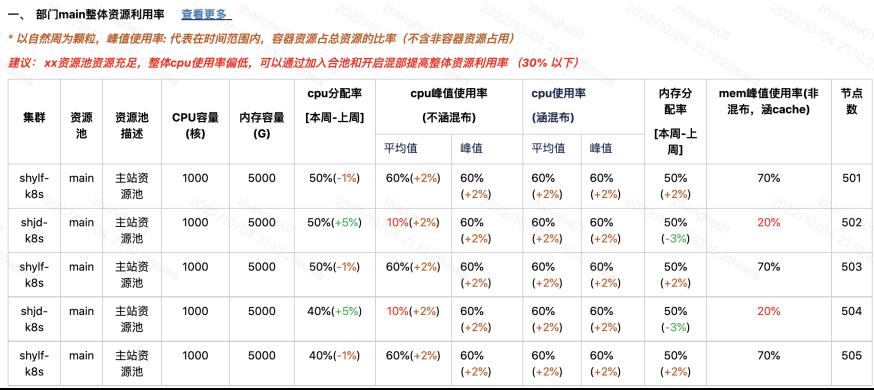
(外部周报展示--部门main整体资源利用率)
3.4.2 内部周报(平台侧)
平台侧周报核心关注以下2点——
部门资源使用率及排名,部门容量Top;
部门资源空闲率Top(大于5000核部门)。
通过公开排名,了解哪些业务的容量治理较弱,并优先治理。同时,由于其资源使用量较大,优先对其做治理,平台也将得到更大的治理收益。
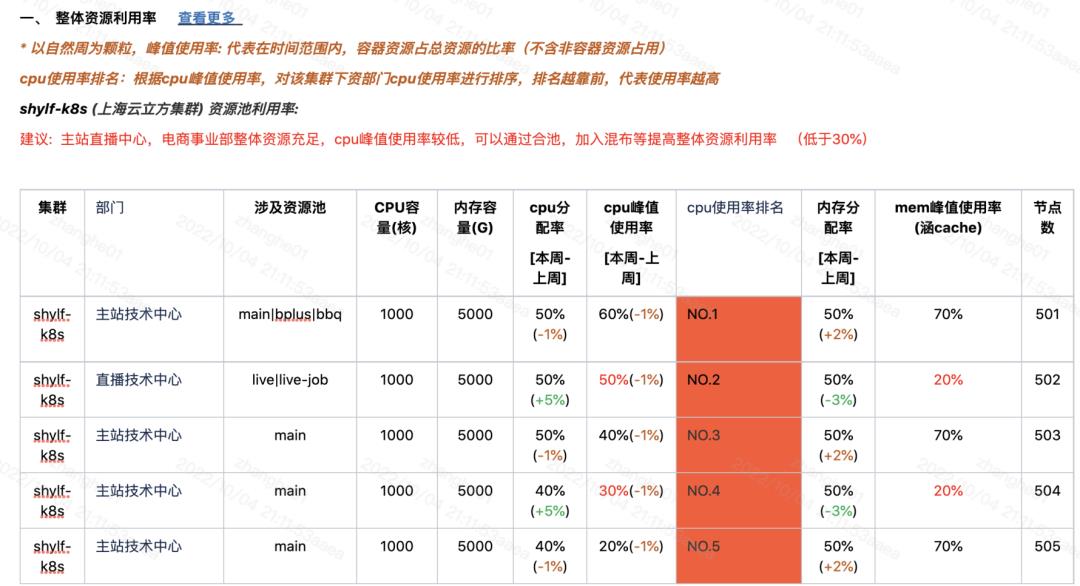
(内部周报展示--整体资源利用率)
3.5 容量巡检
不管是在活动大促,还是在日常业务稳定性保障中,我们都需要密切关注整体容量是否存在风险,所以有了容量巡检体系。
3.5.1 业务类巡检
根据业务侧关注的2个方面——应用容量巡检、配额巡检,我们做了可视化展示。
应用峰值使用率较高的,会有稳定性风险,需要考虑紧急扩容;而应用使用率较低的,则要考虑是否可以缩容以节省资源。
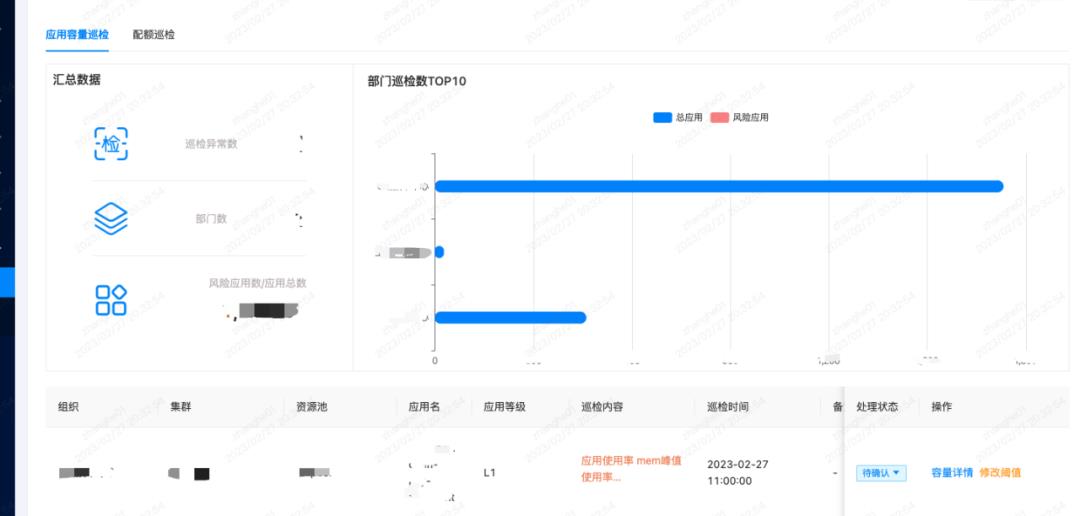
前面讲到我们做了合池,那么需要关注合池后配额使用率过高的情况,避免导致后续扩容或新增业务无法满足,提前发现风险并做治理。
3.5.2 平台类巡检
平台更关注底层的使用率情况,可调度实例数是否满足后续的业务需求,以及资源池是否是单节点等等。同时,因为平台覆盖了 VPA,那么VPA 调整完后的失败率也是平台比较关注的。
基于此,我们做了平台巡检大盘、资源池巡检管理、VPA巡检管理等等。在巡检大盘中,对风险资源池/空闲资源池Top、风险应用Top、风险配额Top等做了相应展示。
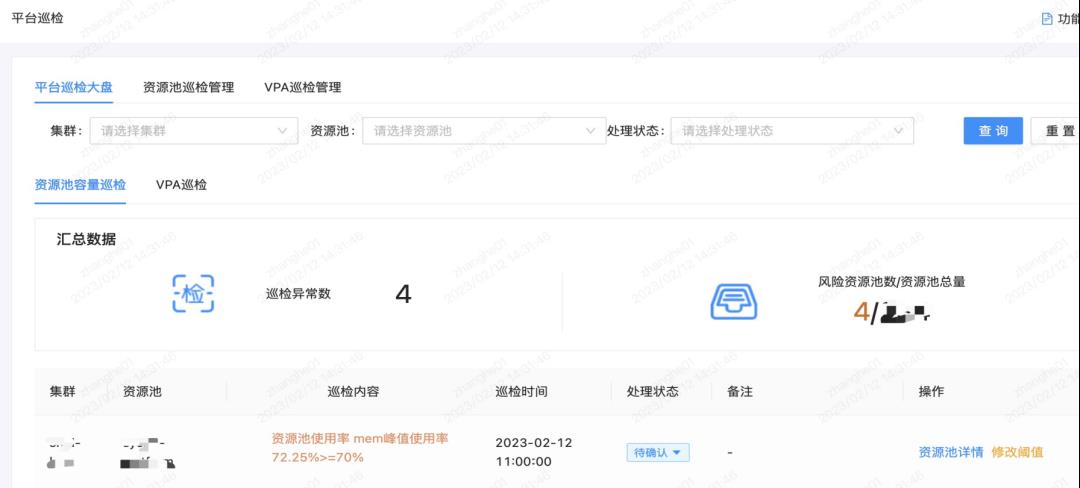
3.6 容量管理的业务价值

容量管理落地后,我们可以直观看到整体工作对业务带来的帮助,比如容量资源导致的发布问题减少80%、容量问题导致的线上故障降低90%等等。从这个角度来看,业务部门并非是在配合平台做容量管理,而是大家共同在为最终的业务目标努力,能确保容量管理落实好后,业务的诉求得到更快响应,稳定性也能得到较大提升。
四、容量管理是如何支撑S12赛事的?
前面我们讲的是平台侧的能力、业务侧的需求,接下来,我将以刚过去的B站大型赛事S12为例,具体阐述容量管理平台在具体业务场景中的应用。
4.1 S12活动节奏
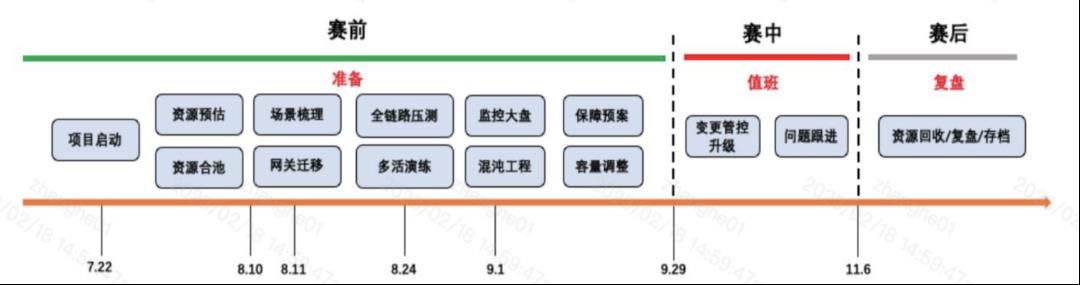
4.2 S12赛前容量预估
S12赛前的容量预估主要分为三大步。
第一步,参考历史基础容量数据,计算容量delta
无论S赛事还是跨年晚会,B站多年来的大型活动,沉淀了一些历史数据可作参考,基于历史数据可以计算出增量。
举个例子,S11 在11月举行总结赛,活动保障启动在8月,拿8月的使用量a和S11峰值使用量b做比较,并根据delta = 1 + (b-a) / a,来算出S11当年的增量系数,比如1.3、1.5等。
第二步,S12新增场景,预估增量
考虑到S12在原有基础上,会有一些新增场景,此时需要在业务目标明确后,将其转化成技术目标,技术目标再去转化为容量需求,得到一个预估的增量d。
第三步,S12容量预估,得到资源缺口
在资源准备中,额外buffer通常是10%~20%。总容量的预估,可以根据S12当前8月的使用量e和buffer来推算,公式参考如下:
容量预估=(e * delta + d ) * (1 + buffer )
这部分预估的容量,减去当前的总资源存量,即可得到整体的资源缺口,并以此为依据进行容量调整。
4.3 S12的PaaS合池
4.3.1 合池前后对比
在合池之前,各块物理资源池相对独立,如下图所示,漫画业务的整体资源使用率最低,而直播可能已接近饱和,此时由于直播是完全独立的物理资源池,漫画和电商业务的空闲资源无法被利用。在往年,例如S11时期,就需要采购资源或临时从云上新增资源来支撑整个活动。
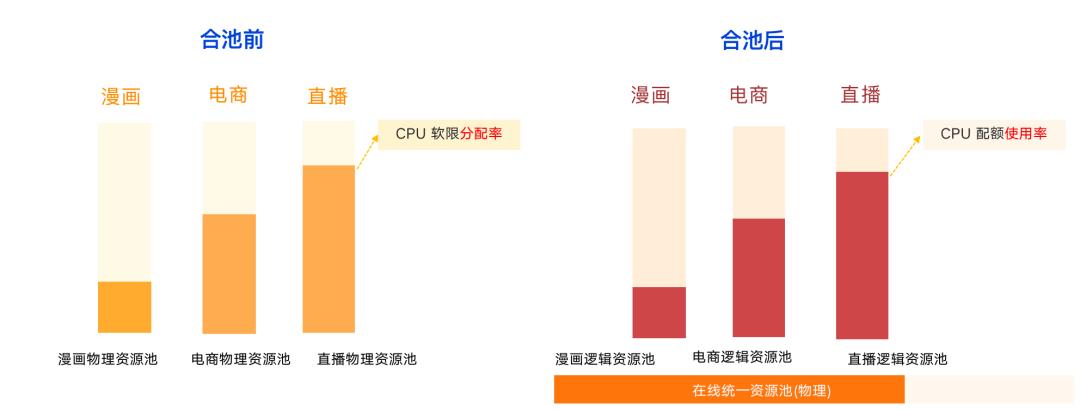
S12赛前,我们把诸如漫画、电商、直播等的在线类微服务合池完后,业务不再需要关心总体的物理资源池,即只需关心自身业务逻辑配额的使用率,而非底层的分配率或使用率。在物理层面有在线统一物理资源池,底层的分配率、使用率完全由 SRE 和平台来保证。
4.3.2 合池可能风险
合池后可能会面临一些不稳定因素,比如,不同的资源池或不同的业务,其内核版本可能有差异,所以我们做了整体物理层的标准化,统一内核以及去CPUSET化,通过底层的 VPA 策略动态调整整体资源使用。
4.4 S12的配额管理
由于合池后的每个业务都共用一个资源池,所以各业务的资源配额需要做到细分管理,避免资源被无限度使用。这里我们通过容量管理平台进行管理,容量配额下发逻辑如下图所示。
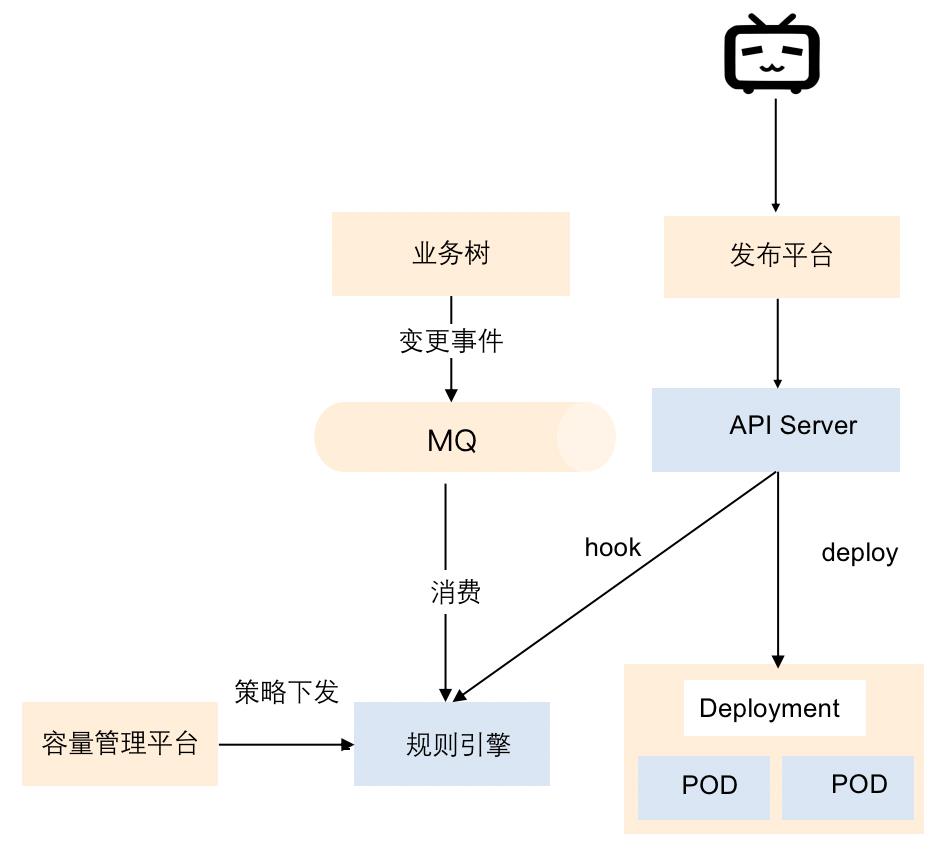
配额是基于组织数来下发的,比如某个组织能使用多少配额,策略下发后会作用在规则引擎上,业务变更时,比如要做发版前,会先在规则平台上了解对应业务的配额是否足够做发版,若资源不够,则会提醒配额不足,此时需联系 SRE 调整配额或者进行配额治理。以此我们就能做到配额管控,保证整个资源池不会被乱用。
4.5 S12的容量支撑
整个 S12 赛事期间,容量支撑可以大致分为四个方面——HPA、VPA、弹性上云、容量巡检,如下图所示。

4.6 S12的容量监控大盘
对于S12赛事活动保障,整体关注的核心指标有业务指标、SLO、资源饱和度,容量监控大盘能根据核心指标,帮助更快地定位潜在风险点,并快速做决策。
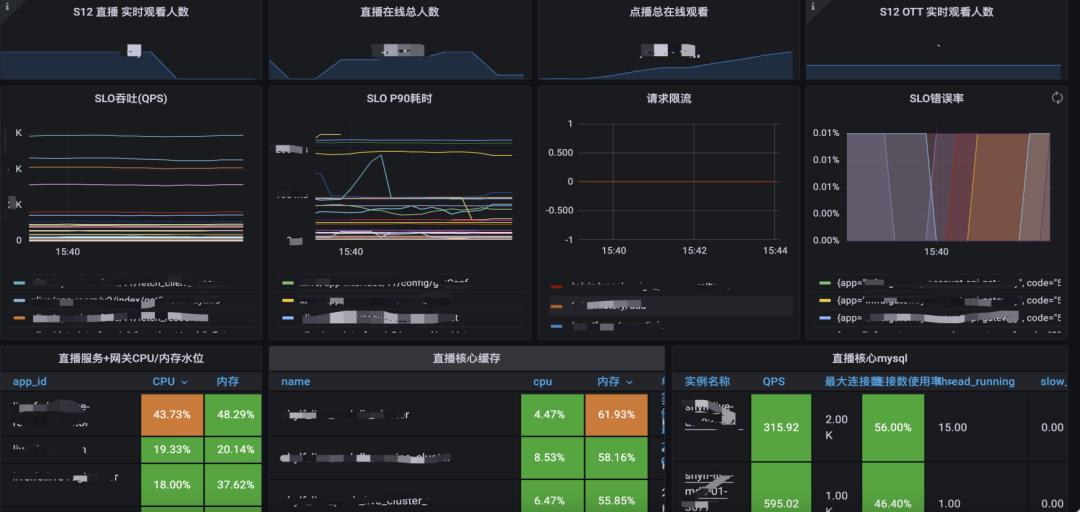
首先是业务指标,S12我们比较关注直播间在线人数,如超过1000万、2000万等等。当赛事期间的整体流量增加,点播业务也会被影响,所以点播在线人数也是我们关注的业务指标之一。
其次是SLO,SRE团队会更关注核心接口的QPS,以及吞吐、延迟、错误率等。
最后是资源饱和度,包括核心服务饱和度、核心中间件饱和度等。
五、未来规划
5.1 容量风控
我们发现有一些服务的容量变更操作缺乏依据,比如想当然地做缩容,没有指标去提示或验证,很有可能导致服务故障。所以我们会做容量风控相关的拦截策略,基于容量画像、应用群包,去做到容量变更风险控制。
5.2 弹性伸缩
第一块是分时调度。B站有些小活动比如漫画业务,基本是在夜间有1个小时左右的峰值流量,其他时间点都是正常的流量。加入分时调度后,比如夜间0-1点的活动,我们就可以在23点前提前做好扩容,活动结束后完成缩容。
第二块是弹性预测。一方面是能够预测有规律的流量压力并提前扩容,另一方面如果监控系统挂了,弹性的预测数据也可以作为监控数据的兜底。
5.3 热点打散
我们是基于软限调度,同时软限也基于 VPA 做了调整,但仍难避免有些服务在物理机上会有热点,所以我们将基于物理机去做二次调度等工作。(全文完)


添加助理小姐姐(shulie888),凭截图免费领取以上所有资料
并免费加入「TakinTalks读者交流群」
声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
本文由博客一文多发平台 OpenWrite 发布!
以上是关于B站容量管理:游戏赛事等大型活动资源如何快速提升10+倍?的主要内容,如果未能解决你的问题,请参考以下文章