HDFS监控背后那些事儿,构建Hadoop监控共同体
Posted 六月雪寒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS监控背后那些事儿,构建Hadoop监控共同体相关的知识,希望对你有一定的参考价值。
导语
大数据生态圈中,HDFS是最重要的底层分布式存储系统,它的稳定性关乎着整个生态系统的健康。本文介绍了HDFS相关的重要监控指标,分享了指标背后的故事。
HDFS监控挑战
面临主要挑战:
HDFS是Hadoop生态一部分,监控方案不仅需适用HDFS,其他组件也需适用,如Yarn、Hbase、Hive等
HDFS本身提供的指标较多,这些指标没必要全部采集,但在需要时能快速获取到
Hadoop相关组件的日志,比较重要,如问题定位、审计等
监控方案不仅能满足监控本身,故障定位涉及指标也应覆盖
Hadoop监控方案
谈起Hadoop监控管理工具,不得不说CDH和Ambari。
CDH为Cloudera公司开源的一款集部署、监控、操作等于一体的Hadoop生态组件管理工具,也提供收费版(比免费版多提供数据备份恢复、故障定位等特性)。CDH提供的HDFS监控界面在体验上是非常优秀的,是对HDFS监控指标深入发掘之后的浓缩,比如HDFS容量、读写流量及耗时、Datanode磁盘刷新耗时等。
图1 CDH提供的HDFS监控界面
Ambari与CDH类似,它是Hortonworks公司(被Cloudera公司已收购)开源(此信息需再确认)。它的扩展性要比CDH好,另外,它的信息可以从机器、组件、集群等不同维度展现,接近运维人员使用习惯。基于Ambari,可以实现对其他软件的监控管理,但是它的UI和CDH有一定差距。
如果使用CDH,或者Ambari进行HDFS监控,也存在实际问题:
对应的Hadoop及相关组件版本不能自定义
不能很好的满足大规模HDFS集群实际监控需求
其他工具,如Jmxtrans目前还不能很好适配Hadoop,因此,实际的监控方案选型为:
采集:Hadoop exporter,部分自定义任务
说明:自定义任务主要通过http://{domain}:{port}/jmx实现
日志:通过ELK来收集、分析
存储:Prometheus
展现:Grafana,HDFSUI,Hue
告警:对接京东云告警系统
Hue作为UI交互工具推荐使用,HdfsCLI也推荐使用。
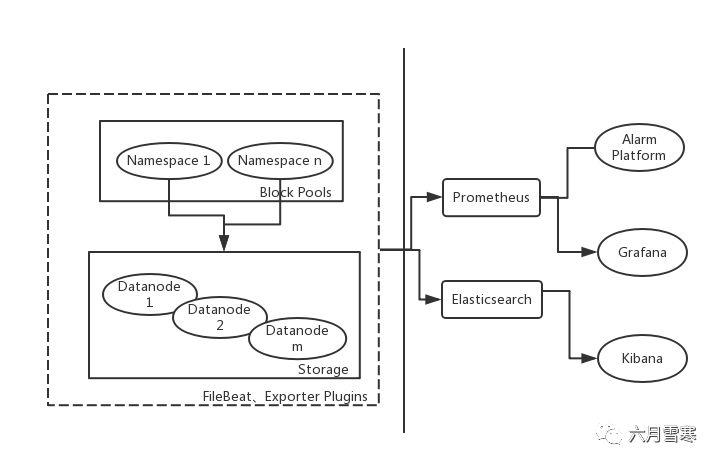
图2 HDFS监控架构图
HDFS监控指标
主要指标概览
HDFS实战中,三个最重要监控项:
基本功能,如果一个或两个异常节点(慢节点等)影响到全局也需发现
数据完整性,坏块数量,如果出现坏块异常,则意味着数据丢失,因此需再深入一步,副本数量提前预警
流量
涉及到的其他主要监控指标:
表1 HDFS主要监控指标概览
黑盒监控 |
功能 |
文件生命周期健康:创建、查看、修改、删除 |
Block读写成功率(作为对外SLA衡量指标) |
||
白盒监控 |
容量 |
集群总空间、空间使用率 |
Namenode堆内存使用率 |
||
文件系统对象数 |
||
数据均衡度(用标准差衡量),空间耗尽实例数 |
||
存活实例数、下线实例数 |
||
流量 |
Block读、写流量 |
|
进出流量(对外/对内) |
||
磁盘I/O流量 |
||
延迟 |
队列长度时间 |
|
慢节点数量 |
||
请求队列长度 |
||
错误 |
Block丢失数量 |
|
未复制Block数 |
||
数据盘故障 |
||
核心外部依赖Zookeeper、DNS |
||
错误日志关键字监控 |
除上述主要指标外,比如机器或实例资源使用情况、各角色健康状态等监控,均需考虑,本文不再赘述。
黑盒监控指标
基本功能
文件整个生命周期中,是否存在功能异常,主要监控创建、查看、修改、删除动作。
查看时,需校对内容,有一种方式,可以在文件中写入时间戳,查看时校对时间戳,这样,可以根据时间差来判断是否写超时
切记保证生命周期完整,否则,大量监控产生的临时文件可能搞垮HDFS集群
读写成功率
根据Block实际读写流量汇聚计算,是对外SLA指标的重要依据。
白盒监控指标
容量
集群总空间、空间使用率
HDFS UI花费了很大篇幅来展现存储空间相关指标,足以说明它的重要性。
空间使用率计算包含了处于“下线中”节点空间,这是一个陷阱。如果有节点处于下线状态,但它们代表的空间也计算在总空间,如果下线节点过多,存在这样“怪象”:集群剩余空间很多,但已无空间可写。
在Datanode空间规划时,要预留一部分空间。HDFS预留空间有可能是其他程序使用,也有可能是文件删除后,但一直被引用,如果“Non DFS Used”一直增大,则需要追查具体原因并优化,可以通过如下参数来设置预留空间:
dfs.datanode.du.reserved.calculator
dfs.datanode.du.reserved
dfs.datanode.du.reserved.pct
作为HDFS运维开发人员,需清楚此公式:ConfiguredCapacity = Total Disk Space - Reserved Space = Remaining Space + DFS Used + NonDFS Used。
Namenode堆内存使用率
如果将此指标作为HDFS核心指标,也是不为过的。元数据和Block映射关系占据了Namenode大部分堆内存,这也是HDFS不适合存储大量小文件的原因之一。堆内存使用过大,可能会出现Namenode启动慢,潜在FGC风险,因此,堆内存使用情况需重点监控。
实际中,堆内存使用率增加,不可避免,给出有效的几个方案:
调整堆内存分配
建立文件生命周期管理机制,及时清理部分无用文件
小文件合并
使用HDFS Federation
尽管这些措施可以在很长时间内,有效降低风险,但提前规划好集群也是很有必要。
文件系统对象数
文件系统对象数包括文件、目录、块的数量,与堆内存配合使用。每个文件系统对象至少占有150字节堆内存,根据此,可以粗略预估出一个Namenode可以保存多少文件。根据文件与块数量之间的关系,也可以对块大小做一定优化。
数据均衡度(用标准差衡量),空间耗尽实例数
HDFS而言,数据存储均衡度,一定程度上决定了它的安全性。实际中,根据各存储实例的空间使用率,来计算这组数据的标准差,用以反馈各实例之间的数据均衡程度。数据较大情况下,如果进行数据均衡则会比较耗时,尽管通过调整并发度、速度也很难快速的完成数据均衡。针对这种情况,可以尝试优先下线空间已耗尽的实例,之后再扩容的方式来实现均衡的目的。还有一点需注意,在3.0版本之前,数据均衡只能是节点之间的均衡,不能实现节点内部不同数据盘的均衡。
单实例空间使用率耗尽情况,作为补充,也需要监控。具体原因简单说明如下:
BlockPlacementPolicy.java中:
private boolean isGoodTarget(DatanodeStorageInfo storage,
long blockSize, int maxTargetPerRack,
boolean considerLoad,
List<DatanodeStorageInfo> results,
boolean avoidStaleNodes,
StorageType requiredStorageType)
定义了判断一个实例是否可以作为存储的条件,其中一个是“是否有足够存储空间”。如果空间已写满实例数量过多,则可能导致选择不到健康的Datanode,因此,必须保证一定数量的健康Datanode。
存活实例数、下线实例数
HDFS集群规模较大时,实时掌握健康实例说,定期修复故障节点并及时上线,可以为公司节省一定成本。
流量
Block读、写流量
Block读写流量,主要通过ELK日志收集后,在Kibana上添加相应Dashbord来实现。
进出流量(对外/对内)
没有直接可以使用的现成数据,需要通过ReceivedBytes(接收字节总量)、SentBytes(发送字节总量)来计算,另外RpcQueueTimeNumOps(RPC请求总次数)也可以作为参考指标来计算。
Datanode所在实例的网卡流量也需要汇聚计算。
磁盘I/O流量
延迟
队列长度时间
采集RpcQueueTimeAvgTime(平均队列时间)、SyncsAvgTime(Journalnode同步耗时)。
慢节点数量
慢节点主要特征是,落到该节点上的读、写较平均值差距较大,但给他足够时间,仍然能返回正确结果。通常导致慢节点出现的原因除机器硬件、网络外,对应节点上的负载较大是另一个主要原因。实际监控中,除监控节点上的读写耗时外,节点上的负载也需要重点监控。
根据实际需要,可以灵活调整Datanode汇报时间,或者开启“陈旧节点”(Stale Node)检测,以便Namenode准确识别故障实例。涉及部分配置项:
dfs.namenode.heartbeat.recheck-interval
dfs.heartbeat.interval
dfs.namenode.avoid.read.stale.datanode
dfs.namenode.avoid.write.stale.datanode
dfs.namenode.stale.datanode.interval
请求队列长度
采集CallQueueLength、NumOpenConnections、TotalLoad即可。
错误
Block丢失数量
如果出现块丢失,则意味着文件已经损坏,所以需要在块丢失前,提前预判可能出现块丢失的风险。
未复制Block数
数据盘故障
如果一个集群有1000台主机,每台主机是12块盘(一般存储型机器标准配置),那么这将会是1万2000块数据盘,按照机械盘平均季度故障率1.65%(数据存储服务商Backblaze统计)计算,平均每个月故障7块盘。若集群规模再扩大,那么运维工程师将耗费很大精力在故障盘处理与服务恢复上。很显然,能够有一套自动化的数据盘故障检测、自动报修、服务自动恢复机制,是多么幸福的事情啊!
除故障盘监控外,故障数据盘要有全局性解决方案。在实践中,以场景为维度,通过自助化的方式来实现对此问题处理。

图3 基于场景实现的Jenkins自助化任务
核心外部依赖Zookeeper、DNS
Zookeeper在实际部署中,切忌将Nodemanager临时目录与Zookeeper数据目录混用,否则计算任务频繁IO操作可能导致Zookeeper数据写延迟。
由于Hadoop自身设计原因,对主机名强依赖,因此,必须保证主机名正反解正常。同样,DNS服务本身监控也至关重要。
错误日志关键字监控
根据实际经验,匹配关键字,总结出常见错误日志监控。
HDFS监控落地
Grafana仪表盘展现:主要用于服务巡检、故障定位
说明:Grafana官方提供的HDFS监控模板,数据指标相对较少
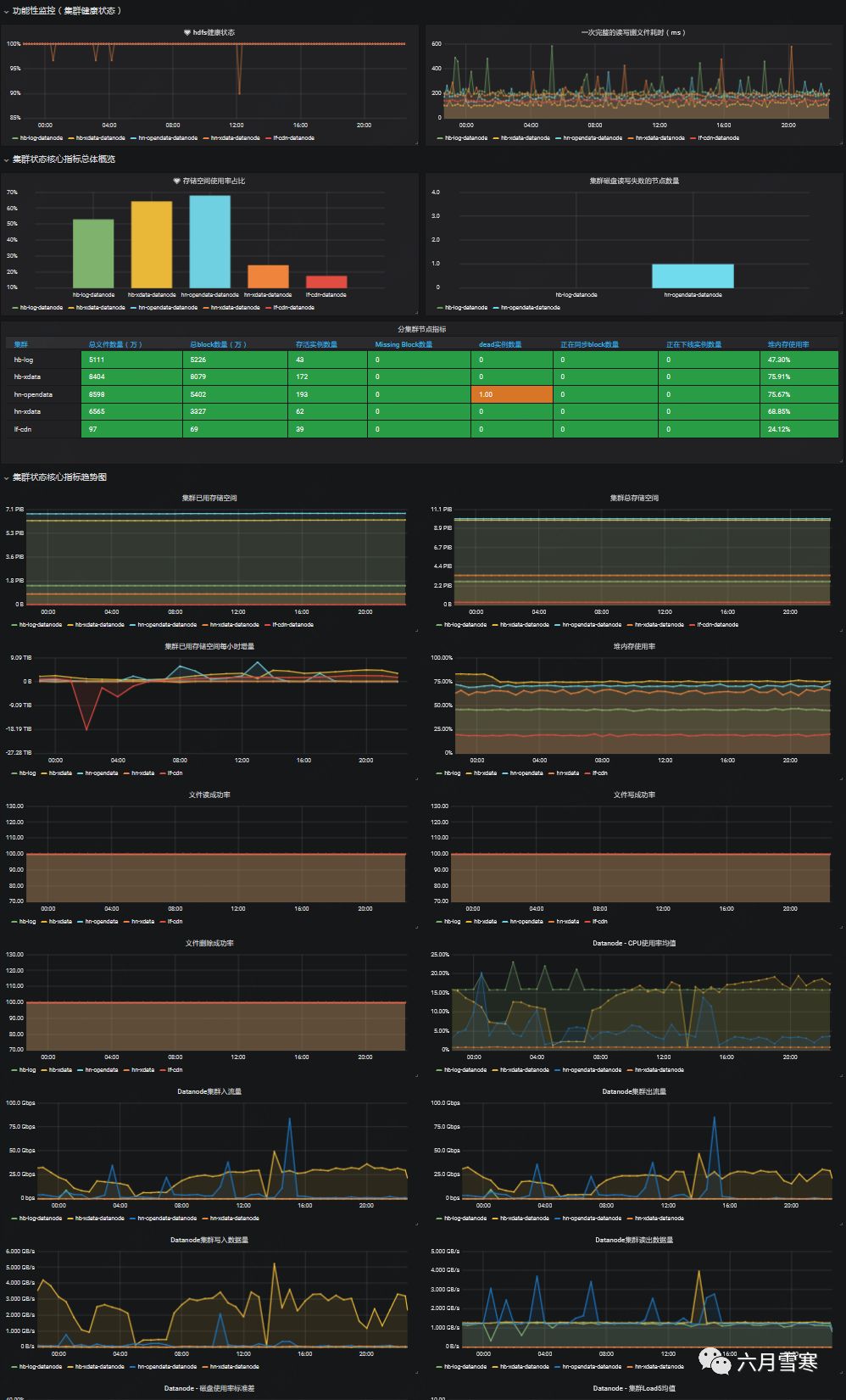
图4 HDFS边缘集群仪表盘
ELK-Hadoop:主要用于全局日志检索,以及错误日志关键字监控
图5 ES中搜索HDFS集群日志
Hue、HDFSUI:主要用于HDFS问题排查与日常维护
图6 HDFS UI部分内容
HDFS监控案例
案例1
DNS产生脏数据,导致Namenode HA故障
发现方式:功能监控、SLA指标异常
优化建议:如果没有内部DNS,使用DnsMasq来彻底解决DNS问题
案例2
机架分组不合理,导致HDFS无法写入
发现方式:功能监控写异常偶发性告警
优化建议:合理分配各机架上的实例数量
附:
HDFS监控自定义任务:https://github.com/cloud-op/monitor
以上是关于HDFS监控背后那些事儿,构建Hadoop监控共同体的主要内容,如果未能解决你的问题,请参考以下文章