创始人专访:比 Hadoop 快至少10 倍的大数据平台是这样炼成的
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创始人专访:比 Hadoop 快至少10 倍的大数据平台是这样炼成的相关的知识,希望对你有一定的参考价值。
2019年7月12日,涛思数据团队对外正式宣布一款专为物联网定制打造的大数据平台软件,此项目一经开源,引起强烈关注,连续两天时间在 Github 全球趋势榜上排名第一。截至发稿前,TDengine 在 Github 上获得近 7000 的 star。

▲ 截至发稿前,TDengine 在 Github 上的 star 数近 7000
TDengine 背后的男人
这款大数据平台背后的男人正是陶建辉,湖南人,一个健谈,爱笑的大龄程序员。
在一个天气炎热的下午,我们来到陶思数据位于北京朝阳区望京的办公楼,一起与创始人陶建辉老师聊一聊 TDengine 物联网大数据平台从研发到成功开源背后的故事。

▲ 陶思数据创始人陶建辉(Jeff)
①
高效运维社区(以下简称“社区”):陶建辉老师,您好,可否介绍一下您刚刚开源的这款软件,它的名字是什么?应用在那些领域?
陶建辉:我们刚刚开源的这款软件叫 TDengine。它主要是处理物联网、车联网、工业互联网、包括运维检测这种类型的数据,我们称之为一个大数据平台。
TD 的意思是 Time-series Data,也是 TAOS Data 的简称,也可以称之为 Teradata,于是我们取了 TDengine 这个名字。这个产品不仅仅是一个数据库,我们不想只做一个数据库,而是想做一个大数据平台,这里面除了数据库,还有缓存、消息队列、流式计算等一系列软件,我们是想把这一系列软件都包含在里面,提供一个全栈、完整的解决方案。
▲TDengine :专为物联网而生的大数据平台
②
社区:这一次您将整个平台最核心的存储引擎、计算引擎和成套的工具完全开源出来,是出于怎样的考虑?
陶建辉:对于我们来说,这次终于跨出了重要的一步。TDengine 不管是自身的测试,还是现有的客服反馈,性能相当之好,至少插入速度和查询速度秒杀所有的竞争对手,包括应用性上,比如安装包大小、各种线上操作都有不俗的表现,一款优秀的产品研发出来后如何推广?开源是一种方式,但怎么开源?我们自己也思考了很久。
一开始确实我们还是有很多纠结的,因为我以前不是做开源社区的,如果我以前是做开源软件的,可能没有多少纠结,那最终为什么下定决心做开源?我想有几个原因。
第一,是 TDengine 确实有优异的性能,我并非传统的销售人员,那怎么才能快速获得市场?开源是个很好的方式,能够快速地扩大 TDengine 影响力并获得市场。
第二,整个IT产业的两大趋势,不拥抱是绝对不行,一个是开源,另一个是云服务。不拥抱云服务和开源是成不了独角兽,尤其是基础软件。我自己前面创过两次业,这是第三次创业,我一心是想成为独角兽的,如果不拥抱开源,不拥抱云服务,我是成不了独角兽,不管成不成,必须开源,才能实现我的梦想。
③
社区:这样就衍生了一个问题,开源要如何盈利?老师能否在这个问题上有过纠结?
陶建辉:盈利其实有很多方式,其中一种就是开源版本上有一个企业版,这两个版本有什么区别?核心引擎是一模一样的,但企业版上还有一部分是集群,企业一般需要高可用和更大规模的处理,这方面我们还没有开源。
另外一方面的计划是集群版也会开源,只是时机还没有成熟。如果集群也是一个很重要的核心,一旦开源就像之前核心的地方都开源,那靠什么盈利?其实依然有很多盈利的方式。
任何一款产品一定是会有不足的,大型的企业在用软件的时候,一定会购买服务,如果没有原创团队在背后支持,万一某一天宕机,损失是非常大的。我们更多是给大型、中型企业提供一种保险,就是开源之后,我们让企业用起来放心。

陶建辉:社区版和企业版都会升级,但我会第一时间把我解决的 BUG 开放出来,让损失降到最低的程度,而且还有一些外围的管理工具,尤其是运维的工具,会给企业客户来使用,让管理更方便、更可靠,这是我们今后的盈利点。包括已经付费的客户,你买了我们产品好处是买了我们的服务和支持。
④
社区:TDengine 目前有哪些比较有代表性的客户?
陶建辉:代表性的比如广联达的智慧城市使用了 TDengine 大数据平台,还有数控机床、机器人全球最大企业 FANUC,也用了 TDengine,还有山西电力全省12个机房的 IT 运维都已经用了 TDengine。

⑤
社区:TDengine 最核心的技术有哪些与众不同的特性,相比同类的产品,最大的优势是什么?
陶建辉:我讲一下 TDengine 相对于其他同类产品有六大特点。
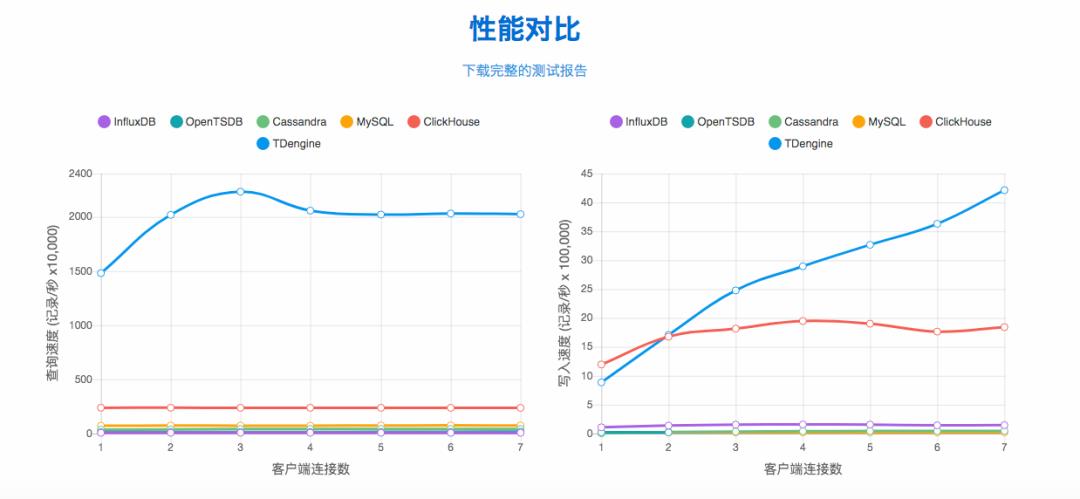
第一,10倍以上的性能提升,插入、查询速度极其之快,官网上宣传的是10倍,其实还不止10倍,因为宣传的原因,说10倍比较好记,对比有一些产品我们是快几十倍。
第二,一站式解决了所有的问题。一些时序数据库像 InfluxDB,还得用其他软件,消息队列、流式计算、缓存;我们把缓存、消息队列、数据库组合在一起,大幅降低了研发和运维的复杂度和成本。现在的运维真的越来越难做了,以前就是数据库不宕机就行,现在要管 Kafka、Spark、Hbase、HDFS,我们把它合在一起,这就大幅降低运维和研发的成本。
第三,我们是能够把硬件和云服务的成本大幅降低,为什么能降低?第一个是我们的性能特别高,以前可能要10台服务器,现在可能只需要一台或两台就够了,那你采购的服务器就少多了,或者你到阿里云上去买虚拟机,用的虚拟机也少多了。
另外一方面我们整个存储的成本也大幅节省,由于我们采用列式存储,用格式化存储之后,对不同的数据类型采取不同的压缩算法,压缩空间大幅节省。
比如说拿 TDengine 跟 Hbase 相比,我们在一个车联网企业的应用里,压缩以后只有 Hbase 存储空间的7%,也就是说 100T 到 TDengine 这里只要7个T,节省了很多费用。
第四,就是历史数据和实时数据处理是一套方法。在做 SQL 查询时,不会到历史库去查,到实时库去查,分成两套,TDengine 就是一个 SQL 语句,只要改时间,也是一样的查询,这就很简单。而且整个查询可以通过 Python、MATLAB、R 来查,这个数据分析,尤其做机器查询,不是同一个RESTful API来查。
第五,就是 TDengine 是有标准的 SQL,支持 JDBC、ODBC,那不是像很多大数据软件都RESTful API之外,尤其是对to B的软件,写 Java 程序的程序员特别喜欢用 JDBC,所有学过计算机的人都会写sql,即使没写过,可能他一听就知道怎么用sql了。那因此我们这个学习成本就极其之低。

▲ TDengine 与同类产品相比的六大特点
⑥
社区:相比于hadoop来说,您说至少快十倍,那其最大的优势是什么?通过什么技术来实现?
陶建辉:比 hadoop 远远不止十倍,刚才讲的优势实际上我都讲了。它主要是通过什么技术实现的,主要是我们充分利用了物联网或运维数据的特点,我们的产品是基于这些特点开发的。
拿 TDengine 跟 hadoop 对比,对 hadoop 有一点点不公平,hadoop是所有类型的数据都能处理,比如舆情大数据分析,用户画像、推荐系统,但我们不是。我们只能做物联网、车联网、工业互联网、运维数据、金融数据,TDengine 不是个通用的,是个专用的。那么它到底有什么特点?我顺便介绍一下物联网或运维采集的数据有什么特点。
举个例子,比如日志是按照时间产生的,agent 它是每一秒钟采集服务器的状态,内存、CPU、网络;采集一下应用的状态,如 nginx,采集一下,的 DataBase 的状态,它是定时采集的,是按照时间产生的,一定是时序的数据,而且是日志型的,采集了之后不会改,这是一个很大的区别。
第二,它是结构化的,我讲个最简单的例子,比如说CPU,它说我们就是个浮点数,CPU占比是80%,还是90%,我用的内存是用哪,当前的内存是用了16个G,过一会是16.5G,我的硬盘的状态现在是几个T,还是多少,它被它采集,它是个结构化的数据,对吧,就包括智能电表,我们跟电网合作的智能电表这里,就产生了电流电压相位,你用不着画结构化表说它就是个结构化的数据。
第三,这种数据一般不改,没有人去改。
第四,不是不删,是到了一定的时间要删。举个例子,运维监测数据只保留7天,保留一个月我就不要了。
还有一个特点,比如说写多读少的这种数据,人们是很少去看这种数据的,一般是通过算法统计、分析来看这个数据,靠程序去读,不像微博、微信,是写一条无数人看。就像我写的那篇文章,好多人看,就写了一次,但无数人读。但运维监测的数据还包括物联网、车联网则不是这样,这又是个不同的特点。
还有个特点,举个例子,物联网的流量比较平稳,我假设整个机房、超算中心、IDC中心有一万台服务器,每台服务器采集三百个量,每五秒钟采集一次,我可以把采集的流量估算出来,说每秒会产生多少监测的流量,到了“双11”,京东、淘宝的流量要涨几十倍都不止,但这个物联网、车联网都不存在,它是平稳的,它很有特点。
另外,物联网、车联网包括运维,它从来不看单个采集值,更多的是看一个时间段的趋势,就看您炒股票,这个股票涨了还是跌了,它并不看我买的第一手价格是什么,更多的是看趋势,看看过去的几个分钟,过去的几秒钟,过去的几天,几个月,整个的波动的趋势是什么。
除了这些特点外,但是物联网、车联网包括运维,它的数据链特别地大,它单个点的价值很低,而微信、微博包括银行记录,它是单条价值特别高。
比如说微信,每条记录都不能丢,丢了那是严重的BUG。那物联网包括运维,你丢一分钟的数据有什么关系?其实没有什么关系,它不影响任何的判断和决策,这就是物联网数据跟这种通用大数据很大的一个区别,我们之所以比hadoop牛得那么多,跟别的牛得那么多,主要是我们充分利用了我刚刚讲的这些数据特点做的。
比如说运维集成里面有很多人用 ElasticSearch 来做这种,ElasticSearch 做这种我们程序里的日志,做大个的分析特别好,但我认为如果来做运维的监测,那是完全错误的选择,没有考虑到这个数据的特点,因为 ElasticSearch 来做文本、分析、搜索引擎特别好,但是来做电表、车联网、物联网的数据处理那是完全错误的,不是说不能做,但是效率是极其之差。
因此我们是做了一个特殊化专用的大数据平台。
⑦
社区:TDengine 大数据平台没有采取任何第三方的组件,1.5MB的安装包就能将一个物联网大数据平台搞定,从下载、安装、运行不会超过五秒钟,这是如何做到的?
陶建辉:第一个,我们是用 C 语言编写的,我们中间有一个模块是用C++ 写的,结果后来 C++ 都改成了C,因为有的客户抱怨到平台安装 glib 版本不对,要重新下载,glib 版本一下载,安装到 Centos 上一两个小时都搞不定,而我们就希望用户可以一键安装几下搞定,因此用 C 语言开发是我一个很正确的决定,它安装包就是小,C 语言里面又没有太多的库可利用,我就自己开发了很多好用的工具,内存管理也是自己写的,这样就会很精炼,安装包就极其小。我们给客户都是用微信给的,安装包就微信直接给,不利用第三方软件就是我陶建辉从小到大养成的习惯。
就像我文章里分享,我2008年创办和信的时候,那是个做免费短信、彩信的软件,我希望大家能够免费收发短信、彩信,免费在手机上收发邮件,因为那个时候有黑莓手机,黑莓手机每个月费都很多钱,我就希望把黑莓这些功能完全搬运到普通手机上,通过移动互联网、wifi,来随意收发短信、彩信。和信在 Windows moblie 的客户端,你们猜猜多大?才18K,我的功能当然还没有微信那么强,但主要功能是完全有,就是收发短信、彩信、照片、视频,邮件还可以发,这些工具都具备,我不知道微信是现在有没有一百兆,至少几十兆是有吧,我是18K。
陶建辉:其实这是一个习惯的问题,每写任何一行程序的时候,我都是想着项目,能不能少写几行,能不能效率更高一点,你养成这个习惯,包括我们团队现在都养成这个习惯了,那你就一定会写出很小的。因此这也是我们公司一个杀手锏的东西,为什么呢?到边缘侧优势就显示出来了。我们马上就要ARM上二维的版本公开,那你边缘侧历来都是嵌入式的盒子,资源极其有限,我这么小的体量,一定大受欢迎,其他时序数据库都是几十兆,就没有办法在ARM的盒子上跑,而 TDengine 就这么小,就可以。

⑧
社区:陶老师开发这款大数据平台软件的初衷是什么?期间经历了什么有趣的事情?
陶建辉:开发的初衷是因为我在2016年有接近一年的时间在休整,期间被邀请很多VC,基本上都是物联网、工业互联网,包括智能硬件的相关项目,我们那时候很想搞菜市场的智能秤,就想把菜市场的秤完全革命掉,变成智能化。包括我看电梯物联网、农业物联网,包括一些医疗项目。
看完之后也看了一些物联网平台的公司,我很难确定某个物联网到底什么时候起来,智能硬件到底会怎么样,但发现了大家有个共性的东西,就是数据处理没有太大区别。我当时做母婴项目——快乐妈咪的时候,处理的是母婴健康数据,其实它跟电梯物联网的数据没有本质的区别,农业物联网数据的处理跟工业物联网数据的处理跟手环、摩拜单车、滴滴数据处理本质上没有区别。之后我发现,大家几乎都是用 Hadoop 这套体系,Hbase、ElasticSearch、Hadoop是个体系,不仅是这个词,它包含很多东西,就是大家熟悉的这些,Kafka、Spark,这些工具在处理。
我认为这完全搞错了,因为物联网这些数据采集,就像我讲的,它很有特点,那为什么不做一个更好的,更专业化的?我自己认为在未来 5 到 10 年,最多不会超过10年,物联网一定会起来,世界上 90% 的数据会是物联网采集的数据。以前,大家都想不到自行车都会联网,所有的交通工具、电器都会联网,这个数据面能有多大?如果我能做一个极其高效的引擎来处理这些数据,那是多有意义的事情。于是,我就是决定做这个。
⑨
社区:TDengine 的成功离不开团队的支持,您最想感谢的是谁?
陶建辉:毫无疑问感谢我们团队,存储引擎是我自己写的,像我们团队的廖博士,计算引擎几乎是他一个人写出来的;洪泽做压缩,后来又解锁整个存储引擎,存储引擎保证会有BUG,他接手处理了很多,包括胜亮他们,外围的软件很多,包括集群的管理,很多东西要做,我们整个代码有十几万行,好多测试,case,那不是一个人做得到的,包括我们的女生都要感谢,她是我们团队唯一一个不写程序的,涛思数据所有跟程序不相关的事情都是她一个人做的。

▲ TDengine 幕后团队
⑩
社区:开源之后社区的反馈如何?
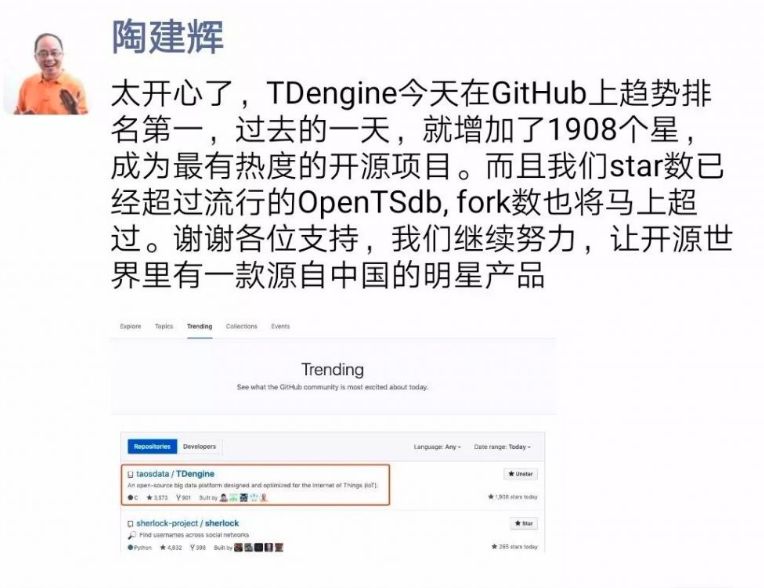
陶建辉:我觉得社区的反馈还是相当正面的,至少已经使用的人就是觉得 TDengine 真的很简单,只有 1.5 MB,也有一些人发现了我们的 Bug,也有很多人提供了建议,比如希望 Windows 版本尽快开源,有人希望我们 dark,就是好几个开发者都主要搞了一个 dark的版本让大家用。最开心的事情就是连续两天在 Github 全球趋势榜上第一,目前在 github 上 Star 数已经超过6000,Fork 的数也已经超过1200,就这两个数字已经超过另外一个有相当多用户的开源时序数据库,这个时候我很开心的,而且很多人在微信和微博上问我问题,反馈很强烈。
⑪
社区:TDengine 未来将向哪些方向发展?
陶建辉:初衷是我们想为整个物联网提供一个全栈的大数据平台,目前从 Roadmap 上来看,我们还有一些不足。一个最明显的例子,就是我们在流式计算上,我们只做了一个滑动窗口的流式计算,但我们去计算,事件驱动,它的实时性会更高,而且事件驱动完了之后我们能做数据清洗之类的一系列的功能,而且还要做自定义函数,因为目前我们提供的函数,自定义聚合,计算的函数不可能满足所有用户的需求,但我希望自定义可以自己实现,即便如此,在自定义函数的这些方面我们永远会采用 SQL,不用定性地脚本语言。
另外一方面 TDengine 还需要提供更多的数据协议接口,比如尽快提供 MQTT 和 OPC接口,这些都是工业物联网最重要的协议,比如说我们有可能提供 Modbus 的接口,这样的话我们的生态会渐渐更完善。
还有就是在应用侧也要提供很多的接口,现在已经跟telegraf、grafana的这些软件集成了,我们可能要跟很多流行的BI工具集成,现在已经有一个BI的公司让 TDengine 跟他们集成在一起了,我希望能够和很多BI工具无缝集成在一起,这个生态要建立起来。
⑫
社区:您认为 TDengine 大数据平台对推动中国IT技术进步有哪些意义?
陶建辉:我觉得意义还是挺大的,中国 IT 产业已经享受了开源社区无数的回应,但是中国 IT 对世界的开源的贡献还比较有限,中国已经有不少公司在为开源社区做贡献,但目前开源社区里做得特别好的还很少,比如 pingCAP 的 tidb 分布式数据库,还有像华为、阿里、腾讯的一些开源项目也不错,但数量还是不多。
比如说数据库,数据库有好多的分支,那冲在排行榜前几名没有一家是中国的公司。说一句豪言壮语,在时序数据处理这一领域,我认为我们一年就能冲到全球排行榜前三名,时序数据库的分支,我估计三年冲到第一名完全没有问题,这样的话,会给中国 IT 产业一个很大的信心,中国人照样能做底层软件,能把做开源做得很好,我相信会有很多IT公司像我一样。
9月6日,GNSEC 高峰论坛,听 35年码龄老程序员、涛思数据创始人陶建辉为您深度揭秘 TDengine 的超高性能是如何实现的。
✨作为社区福利,本次活动特放出限量39元福利门票:
1、购买此票需主办方审核,审核通过后发送付款邮件
2、作为福利,凡是报名本次活动的朋友可在活动现场领取技术图书一本(《持续交付2.0》 《风向》)限量100本。
扫码立即报名
GNSEC 高峰论坛专注于全方位的软件工程和技术,致力于定义新一代软件工程。
GNSEC 定义了新一代的软件工程,旨在聚集软件工程行业的专家、学者、从业者,讲述重要的最新研究成果,并分享最前端的实践经验,同时促进产、学、研领域的专家互相交与合作。
本活动为高端邀请制,拟邀嘉宾来自金融、通信、互联网行业的处级、副总、高级经理及以上领导。
点击阅读原文,访问 GNSEC 高峰论坛官网(立即报名)
以上是关于创始人专访:比 Hadoop 快至少10 倍的大数据平台是这样炼成的的主要内容,如果未能解决你的问题,请参考以下文章