「大数据」初识hadoop
Posted 信息金字塔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「大数据」初识hadoop相关的知识,希望对你有一定的参考价值。
【导读:数据是二十一世纪的石油,蕴含巨大价值,这是·信息金字塔·大数据技术系列第[3]篇文章,欢迎阅读和收藏!】
1 大数据的起源
半个世纪以来,随着计算机技术全面融入社会生活,信息爆炸已经积累到了一个开始引发变革的程度。世界上的信息比以往更多,而且还在快速增长。互联网社交、搜索、电商、移动互联网、物联网(传感器、智慧城市)、自动驾驶、 GPS 、医学影像、安全监控、银行、股市、保险、电信各行业都在疯狂产生数据。而这些数据早就已经远远超越了当前人力能够处理的范畴。
早在 20 世纪 90 年代,数据仓库之父的 BillInmon 就经常提及 Big Data , 2011 年 5 月,在云计算相遇大数据为主题的 EMC World 会议中, EMC 抛出了 Big Data 概念。研究机构 Gartner 定义“大数据”( Big data ):大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的特征定义 - 具有 4V 特性的数据:Volume( 巨大的数据量 ) 、 Variety( 数据类型多 ) 、 Velocity( 处理速度快 ) 、 Value( 价值密度低 ) 。从前面的数据中可以看出,数据量是海量的,传统的数据库或者硬盘已经无法来存储这些数据,更不要说快速处理(读写数据)了。Hadoop 为我们提供了一个可靠的共享存储和分析系统。HDFS 实现数据的存储, MapReduce 实现数据的分析和处理。虽然 Hadoop 还有其他功能,但 HDFS 和 MapReduce 是它的核心价值。
2 Hadoop 框架
2.1 Hadoop 概述
随着大数据的兴起,势必要出现对海量数据快速存储并且分析的新技术,而 hadoop 就是其中之一,但现在大数据已经发展成一个庞大的生态系统, Hadoop 可以说只是其中一小部分。Hadoop 是一个分布式系统基础架构,由 Apache 基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来, Hadoop 是一个可以更容易开发和运行处理大规模数据的软件平台,并实现了一个分布式文件系统( Hadoop Distributed File System ),简称 HDFS 。 HDFS 有着高容错性( fault-tolerent )的特点,并且设计用来部署在低廉的( low-cost )硬件上。而且它提供高传输率( high throughput )来访问应用程序的数据,适合那些有着超大数据集( large data set )的应用程序。 HDFS 放宽了( relax ) POSIX 的要求( requirements )这样可以流的形式访问( streaming access )文件系统中的数据。
3.2 Hadoop 模块分解
Hadoop 主要包括以下四个模块
◆ Hadoop Common: 为其他 Hadoop 模块提供基础设施
◆ Hadoop HDFS: 高可靠、高吞吐量的分布式文件系统
◆ Hadoop MapReduce: 分布式的离线并行计算框架
◆ Hadoop YARN: 新的 MapReduce 框架,任务调度与资源管理
3.2.1 HDFS
在启动 HDFS 集群时, Master 节点主动链接所有的 Slave 节点并在这些节点上启动相应的进程( DN/NM ),连接的方式是通过 SSH 。
◆ NameNode
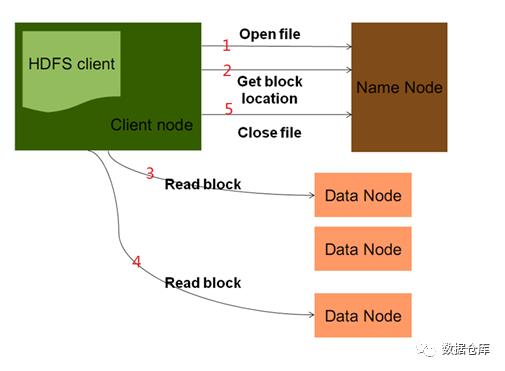
它是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间 (namespace) 以及客户端对文件的访问。NameNode 负责文件元数据的操作, DataNode 负责处理文件内容的读写请求,跟 文件内容相关的数据流不经过 NameNode ,只会询问它跟那个 DataNode 联系,否则 NameNode 会成为系统的瓶颈。 副本存放在哪些 DataNode 上由 NameNode 来控制,根据全局情况做出块放置决定,读取文件时 NameNode 尽量让用户先读取最近的副本,降低带块消耗和读取延时;
Namenode 全权管理数据块的复制,它周期性地从集群中的每个 Datanode 接收心跳信号和块状态报告 (Blockreport) 。接收到心跳信号意味着该 Datanode 节点工作正常。块状态报告包含了一个该 Datanode 上所有数据块的列表。
◆ DataNode
一个数据块在 DataNode 以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳 ;启动后向 NameNode 注册,通过后,周期性( 1 小时)的向 NameNode 上报所有的块信息;心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用;集群运行中可以安全加入和退出一些机器。
◆文件
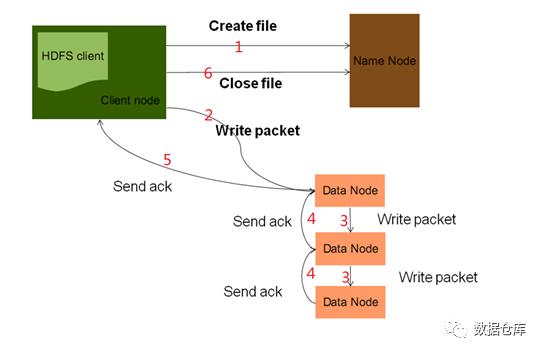
文件切分成块(默认大小 128M ),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认 3 ,是在 hdfs-site.xml 中配置的);
NameNode 是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间 , 副本数 , 文件权限),以及每个文件的块列表以及块所在的 DataNode 等等;DataNode 在本地文件系统存储文件块数据,以及块数据的校验和。 可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
HDFS 读流程:
HDFS 写流程:
3.2.2 MapReduce 计算框架
将计算过程分为两个阶段:Map 和 Reduce
Map 阶段并行处理输入数据 ;
Reduce 阶段对 Map 结果进行汇总 ;
◆ Shuffle 链接 Map 和 Reduce 两个阶段( Shuffle 通俗的理解就是重新洗牌,打乱原有顺序)
Map Task 将数据写到本地磁盘 ;
Reduce Task 从每个 Map Task 上读取一份数据 ;
◆ 仅适合离线批处理
具有很好的容错性和扩展性 ;
适合简单的批处理任务 ;
◆ 缺点明显:
启动开销大,过多使用磁盘导致效率低下等; map tasks 的个数只要是看splitSize ,一个文件根据splitSize 分 成多少份就有多少个map tasks 。 该 slave 节点上有多少个 MapTask 运行,取决于该 slave 节点分配到了多少块(一般默认 128M );slave 的 cpu 是几核的会影响 MapTask 是单线程还是多线程,及其运行效率;如果它出现问题,挂掉,会将没运行完的块交给其它 slave 节点重新运算;
3.3.3 YARN 服务组件(主要是负责硬件资源的合理调用)
YARN 总体上仍然是 Master/Slave 结构,在整个资源管理框架中, ResourceManager 为 Master , NodeManager 为 Slave 。ResourceManager 负责对各个 NodeManager 上的资源进行统一管理和调度;
当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster (主管进程),它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的任务。 由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。
ResourceManager
◆ 全局的资源管理器,整个集群只有一个,负责集群资源的统一管理和调度分配。
◆ 功能
- 处理客户端请求
- 启动 / 监控 ApplicationMaster
- 监控 NodeManager
- 资源分配与调度
NodeManager
◆ 整个集群有多个,负责单节点资源管理和使用
◆ 功能
- 单个节点上的资源管理和任务管理
- 处理来自 ResourceManager 的命令 (下文简称 RM )
- 处理来自 ApplicationMaster 的命令
- 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
- 定时地向 RM 汇报本节点上的资源使用情况和各个 Container 的运行状态
ApplicationManager
管理一个在 YARN 内运行的应用程序的每个实例
◆ 功能
- 数据分割
- 为应用程序申请资源,并进一步分配给内部任务
- 任务监控与容错
- 负责协调来自 ResourceManager 的资源,幵通过 NodeManager 监视容器的执行和资源使用( CPU 、内存等的资源分配)。
Container( 容器 )
◆ YARN 中的资源抽象,封装某个节点上多维度资源,如内存、 CPU 、磁盘、网络等,当 AM 向 RM 申请资源时, RM 向 AM 返回的资源便是用 Container 表示的。YARN 会为每个任务分配一个 Container ,且该任务只能使用该 Container 中描述的资源。
◆ 功能
- 对任务运行环境的抽象
- 描述一系列信息
- 任务启动命令
- 任务运行环境
下图为集群完整的任务流程:
以上是关于「大数据」初识hadoop的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(七十一)<Hadoop生态:初识Flume>