大数据运营技术与工具:Hadoop生态系统
Posted 李福东频道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运营技术与工具:Hadoop生态系统相关的知识,希望对你有一定的参考价值。
本文属于李福东《大数据运营》第8章内容的
重构升级版
,了解更多请关注微信公众号:李福东频道
摘要:Hadoop基于分布式文件系统HDFS构建,主要包括离线计算引擎MapReduce、实时计算引擎Storm、内存计算引擎Spark,它们
与Sqoop、Flume、HBase、Hive、Kafka、Kylin、Zepplin、Zookeeper等构成Hadoop生态系统。
移动互联网让每一个人都有机会成为信息生产者和消费者,因此催生了以海量、实时、多样化为特征的大数据。
毋庸置疑,大数据已经成为新能源和待开垦的新宝藏,应用发展的需要,要求能够以一种动态可扩展的方式存储数据。
为了解决这一问题,以谷歌为代表的互联网公司,发明了分布式系统,从数据的采集、交换、装载、存储、分析、可视化等环节进行了创新。
诸多创新之中,谷歌公司的GFS、MapReduce、BigTable成为大数据技术的先驱代表,随后雅虎、微软、亚马逊、脸书、Twitter等公司,不断将自研产品贡献到开源社区,为大数据技术和产业的发展推波助澜。
GFS(Google FileSystem,谷歌文件系统)是一种可扩展的分布式文件系统,其主要特点是存储文件容量大、便于扩展并且具有良好的容错性。BigTable是构建在GFS之上,是一个压缩的、高性能的、私有的数据存储系统。
MapReduce则相当于GFS的引擎,将海量的、不同媒介形式的数据进行切分(Map),以大数据块等形式存入数据库集群之中,并根据统计需要对不同节点上的数据进行聚合(Reduce)处理。
在谷歌3大经典发明之后,大数据相关的工具产品推陈出新,并陆续加入开源组织Apache(阿帕奇)的大家庭。
目前流行的工具包括:HDFS、YARN、Sqoop、Flume、HBase、Hive、Storm、Kafka、Spark、Kylin、Zepplin等。
HDFS即Hadoop File System,HDFS的实现原理与GFS类似,Hadoop MapReduce与谷歌的MapReduce类似。
HBase是NoSQL数据库,采用了列式数据存取模式,与GFS的BigTable类似,Storm和Spark则解决了海量数据流式计算的问题。
为了解决大数据的管理问题,出现了多种技术框架,为了促进软件技术的发展,出现了许多开源的技术框架,最为典型的就是阿帕奇的Hadoop开源项目。
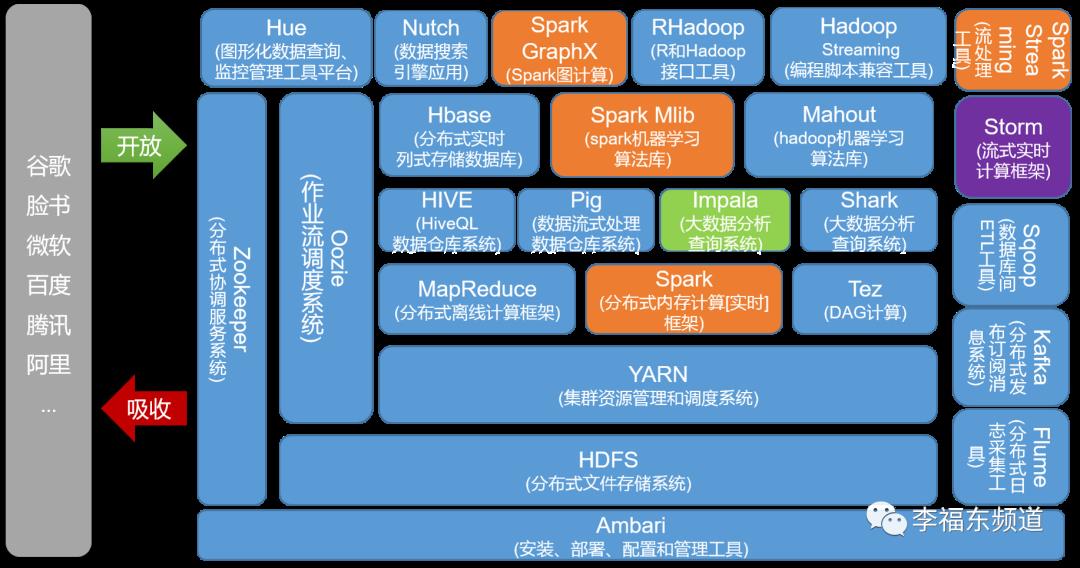
阿帕奇Hadoop开源项目非常多,一个简单的开源项目框架体系如图8-1-1所示:
从图8-1-1可以看出,Hadoop生态系统内的工具产品,都有着独特的定位,自下而上相互支持,自左而右相互配合。
HDFS,即Hadoop FileSystem,是一款典型的开源文件系统,HDFS位于非实时离线计算的底层,是分布式数据库的基础。
HDFS与Windows操作系统中的FAT32、NTFS,Linux操作系统的EXT3、EXT4等文件系统相比,它是一种面向大文件的文件系统。
FAT32、NTFS等文件系统数据存取单位为字节,而HDFS的数据存取单位通常是一个数据块(典型大小为64MB)。HDFS采用以数据块为存取单位的方式,可以大大提高数据的存储容量和存取效率,特别适合对大规模数据的离线处理。
在文件的存取方法方面,HDFS采用NameNode存放文件位置信息,NameNode类似于操作系统上的目录和文件名,操作系统通过目录和文件名就可以定位文件所在的位置。
HDFS采用DataNode存放文件数据。当客户端访问文件时,首先通过NameNode来获取文件所在位置,然后根据文件所在位置定位到文件所在的数据节点(DataNode)。
NameNode方式与Linux的文件管理方式类似,Linux借助虚拟文件系统(VFS,VirtualFile System)屏蔽了文件操作细节,用户在文件操作时,无需了解被操作文件是一台打印机还是一个数据文件,也无需了解文件实际的部署位置。
当然,为了保证数据的可靠性,Hadoop会在集群中设置多个副本,这样当主节点或者数据节点出现故障后,就可以重启任务,并将数据访问路径切换到备用节点,保证数据不会丢失。
当HDFS中存入大量的数据后,需要借助MapReduce完成分析工作。Map就是按照统计分析要求,提取数据文件中的统计维度列和统计值列数据,由于原始数据中统计维度列和统计值列是映射的关系,因此称之为Map,Map就是“映射”的意思。
执行Map操作后,需要从统计维度列角度对统计值列数据进行排序(Sort),最后再通过Reduce(聚合)完成统计维度数据项的计算工作,计算动作可以是次数(count)、均值(average)、求和(sum)等。
Sqoop是一款
位于Hadoop和传统关系型数据库之间的数据交换工具,通过Sqoop,可以实现Hadoop与Oracle、mysql等关系型数据库之间数据的导入和导出。负责数据获取的开源框架和工具包括Pig、Hive等。
HBase架构在Hadoop之上,负责大数据的存储。不同于传统关系型数据库,HBase采用(行:键)的方式存取数据,数据定义和操作语言采用NoSQL(Not only SQL),因此又称为NoSQL数据库。NoSQL数据库还包括BigTable、MongoDB等。
Pig是一种针对Hadoop数据库进行操作的工具,其实现语言为Pig Latin,如果没有Pig,用户需要编写大量的Java代码,有了Pig工具,用户可以像使用SQL那样存取数据。Pig主要面向大数据应用开发者。
Hive是一种比Pig更方便的大数据操作工具,由于其实现方式与SQL非常接近,因此Hive的实现语言称为HiveSQL。
Hadoop主要适用于大批量离线数据的存取,数据处理的实时性差,而像商品实时推荐、实时风险控制、实时统计等应用对于系统的实时性要求非常高,Storm框架的出现解决了这一问题。
如果说MapReduce模型是“计算”找“数据”,那么Storm的Spout/Bolt模型则正好相反,它采用“数据”找“计算”的方式提高了数据处理的实时性。
Spout就像一个水龙头,将数据喷射到不同的数据处理节点(Bolt),来一批数据就处理一次,大大提高了数据统计的效率。
Spark由加州大学伯克利分校开发并开源,解决了海量数据流式分析、基于内存的快速迭代运算、机器学习、数据仓库分析等诸多问题。
Spark则是首先将数据导入Spark集群,然后再通过基于内存的管理方式对数据进行快速扫描,
通过迭代算法实现全局I/O操作的最小化,达到提升整体处理性能的目的。
Spark Streaming与Storm的实现思路基本一致。
Spark Streaming首先对“小数据块”进行批量汇聚,然后再分发给“计算”节点,Storm是将“小数据块”实时地分发(Spout)给“计算”节点,是“数据”找“计算”的思路。
Spark框架支持的编程语言包括Scala、Java和Python。
ZooKeeper负责分布式计算环境的管理,功能包括配置维护、名字服务、分布式同步、组服务等。
从以上分布式数据库相关开源技术可以看出,开源工具的命名都非常有意思,比如Pig是猪,Hive是蜜蜂,ZooKeeper是动物管理员。
其它工具的名称则是非常形象的动作,比如Sqoop意为猛扑,Storm为风暴,意味着快速,Spark为火,意味着朝气和力量。
除了开源框架Hadoop家族,要完成一个大数据项目,还需要项目管理软件、代码管理软件等作为支持。
微软的Project是一款商业版的项目管理软件,OpenProj是一款开源的项目管理软件,可以跨不同的操作系统平台,适用于小型工程项目。
代码管理工具包括Git、SourceSafe、SVN等。
Git是一款开源、免费的分布式版本控制系统,可以敏捷高效地处理任何规模的项目,可以在开发者角色中定义主要开发者和非主要开发者,非主要开发者将软件补丁发送给主开发者。
SourceSafe是微软公司的代码管理工具,主要面向微软公司的开发工具,如VisualBasic、Visual C++等。
SVN是Subversion的简称,是一款开源的代码管理与版本控制系统。
数智萤火虫
愿景目标:致力于为学员提供以大数据、人工智能、数字化转型为核心,从技术到产品,从战略到运营的系统化、高品质知识服务,培养专家型、应用型、实战型人才。
服务内容:会按需延伸至企业架构、产品经理、区块链、5G、AR、VR等领域,帮助您掌握最新的理念、思维、方法、技术与工具,与时俱进,创新发展。
交付理念:起步于技术、聚焦于产品、深耕于运营、决胜于战略,帮助学员实现从点到线,再从面到体的蜕变式修炼与进阶。
交付形式:文章、PPT、音频、视频、微信群、直播、沙龙、答疑、考评等多种形式,多媒体、多触点、线上线下相融合,切实解决工作与学习中遇到困难和问题,提升实战能力。
加入知识星球,您将至少获得:
1、高薪职位推荐。星球帮助学员存放简历,免费对接优选岗位。
2、职业规划指导。帮助学员少走弯路,快速平滑晋级、晋升。
3、精品内容尝鲜。每周至少分享1篇原创精编长文。
4、PPT干货下载。定期推送最新培训、项目、公开课资料。
5、精美礼物赠送。小礼品、红包、作者签名书等。
6、在线问题答疑。72小时内答复个性化问题。
本星球属于你我共同成长的家园,希望我们有缘相聚,共同拥抱数字化时代的新浪潮、新机遇,不负韶华、共创共赢!
选择精品,高效学习
以上是关于大数据运营技术与工具:Hadoop生态系统的主要内容,如果未能解决你的问题,请参考以下文章
一步一步学习大数据:Hadoop 生态系统与场景
大数据hadoop生态体系之YARN配置和使用(13)
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是啥关系?
大数据需要掌握哪些技能
大数据之就业岗位
大数据技术#1 大数据技术生态体系