深入理解react中的虚拟DOMdiff算法
Posted Node前端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解react中的虚拟DOMdiff算法相关的知识,希望对你有一定的参考价值。
文章结构:
React中的虚拟DOM是什么?
虚拟DOM的简单实现(diff算法)
虚拟DOM的内部工作原理
React中的虚拟DOM与Vue中的虚拟DOM比较
React中的虚拟DOM是什么?
虽然React中的虚拟DOM很好用,但是这是一个无心插柳的结果。
React的核心思想:一个Component拯救世界,忘掉烦恼,从此不再操心界面。
1. Virtual Dom快,有两个前提
1.1 javascript很快
Chrome刚出来的时候,在Chrome里跑Javascript非常快,给了其它浏览器很大压力。而现在经过几轮你追我赶,各主流浏览器的Javascript执行速度都很快了。
在 https://julialang.org/benchmarks/ 这个网站上,我们可以看到,JavaScript语言已经非常快了,和C就是几倍的关系,和java在同一个量级。所以说,单纯的JavaScript还是还是很快的
1.2 Dom很慢
当创建一个元素比如div,有以下几项内容需要实现: html element、Element、GlobalEventHandler。简单的说,就是插入一个Dom元素的时候,这个元素上本身或者继承很多属性如 width、height、offsetHeight、style、title,另外还需要注册这个元素的诸多方法,比如onfucos、onclick等等。 这还只是一个元素,如果元素比较多的时候,还涉及到嵌套,那么元素的属性和方法等等就会很多,效率很低。
比如,我们在一个空白网页的body中添加一个div元素,如下所示:
这个元素会挂载默认的styles、得到这个元素的computed属性、注册相应的Event Listener、DOM Breakpoints以及大量的properties,这些属性、方法的注册肯定是需要h耗费大量时间的。
尤其是在js操作DOM的过程中,不仅有dom本身的繁重,js的操作也需要浪费时间,我们认为js和DOM之间有一座桥,如果你频繁的在桥两边走动,显然效率是很低的,*如果你的JavaScript操作DOM的方式还非常不合理,那么显然就会更糟糕了。 *
* 而 React的虚拟DOM就是解决这个问题的! 虽然它解决不了DOM自身的繁重,但是虚拟DOM可以对JavaScript操作DOM这一部分内容进行优化*。
比如说,现在你的list是这样:
<ul>
<li>0</li>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
你希望把它变成下面这样:
<ul>
<li>6</li>
<li>7</li>
<li>8</li>
<li>9</li>
<li>10</li>
</ul>
通常的操作是什么?
先把0, 1,2,3这些Element删掉,然后加几个新的Element 6,7,8,9,10进去,这里面就有4次Element删除,5次Element添加。共计9次DOM操作。
那React的虚拟DOM可以怎么做呢?
而React会把这两个做一下Diff,然后发现其实不用删除0,1,2,3,而是可以直接改innerHTML,然后只需要添加一个Element(10)就行了,这样就是4次innerHTML操作加1个Element添加。共计5此操作,这样效率的提升是非常可观的。
2、 关于React
2.1 接口和设计
在React的设计中,是完全不需要你来操作DOM的。我们也可以认为,在React中根本就没有DOM这个概念,有的只是Component
当你写好一个Component以后,Component会完全负责UI,你不需要也不应该去也不能够指挥Component怎么显示,你只能告诉它你想要显示一个香蕉还是两个梨。
隔离DOM并不仅仅是因为DOM慢,而也是为了把界面和业务完全隔离,操作数据的只关心数据,操作界面的只关心界面。比如在websocket聊天室的创建房间时,我们可以首先Component写好,然后当获取到数据的时候,只要把数据放在redux中就好,然后Component就动把房间添加到页面中去,而不是你先拿到数据,然后使用js操作DOM把数据显示在页面上。
即我提供一个Component,然后你只管给我数据,界面的事情完全不用你操心,我保证会把界面变成你想要的样子。所以说React的着力点就在于View层,即React专注于View层。你可以把一个React的Component想象成一个Pure Function,只要你给的数据是[1, 2, 3],我保证显示的是[1, 2, 3]。没有什么删除一个Element,添加一个Element这样的事情。NO。你要我显示什么就给我一个完整的列表。
另外,Flux虽然说的是单向的Data Flow(redux也是),但是实际上就是单向的Observer,Store->View->Action->Store(箭头是数据流向,实现上可以理解为View监听Store,View直接trigger action,然后Store监听Action)。
2.2 实现
那么react如何实现呢? 最简单的方法就是当数据变化时,我直接把原先的DOM卸载,然后把最新数据的DOM替换上去。 但是,虚拟DOM哪去了? 这样做的效率显然是极低的。
所以虚拟DOM就来救场了。
那么虚拟DOM和DOM之间的关系是什么呢?
首先,Virtual DOM并没有完全实现DOM,即虚拟DOM和真正地DOM是不一样的,Virtual DOM最主要的还是保留了Element之间的层次关系和一些基本属性。因为真实DOM实在是太复杂,一个空的Element都复杂得能让你崩溃,并且几乎所有内容我根本不关心好吗。所以Virtual DOM里每一个Element实际上只有几个属性,即最重要的,最为有用的,并且没有那么多乱七八糟的引用,比如一些注册的属性和函数啊,这些都是默认的,创建虚拟DOM进行diff的过程中大家都一致,是不需要进行比对的。所以哪怕是直接把Virtual DOM删了,根据新传进来的数据重新创建一个新的Virtual DOM出来都非常非常非常快。(每一个component的render函数就是在做这个事情,给新的virtual dom提供input)。
所以,引入了Virtual DOM之后,React是这么干的:你给我一个数据,我根据这个数据生成一个全新的Virtual DOM,然后跟我上一次生成的Virtual DOM去 diff,得到一个Patch,然后把这个Patch打到浏览器的DOM上去。完事。并且这里的patch显然不是完整的虚拟DOM,而是新的虚拟DOM和上一次的虚拟DOM经过diff后的差异化的部分。
假设在任意时候有,VirtualDom1 == DOM1 (组织结构相同, 显然虚拟DOM和真实DOM是不可能完全相等的,这里的==是js中非完全相等)。当有新数据来的时候,我生成VirtualDom2,然后去和VirtualDom1做diff,得到一个Patch(差异化的结果)。然后将这个Patch去应用到DOM1上,得到DOM2。如果一切正常,那么有VirtualDom2 == DOM2(同样是结构上的相等)。
这里你可以做一些小实验,去破坏VirtualDom1 == DOM1这个假设(手动在DOM里删除一些Element,这时候VirtualDom里的Element没有被删除,所以两边不一样了)。 然后给新的数据,你会发现生成的界面就不是你想要的那个界面了。
最后,回到为什么Virtual Dom快这个问题上。 其实是由于每次生成virtual dom很快,diff生成patch也比较快,而在对DOM进行patch的时候,虽然DOM的变更比较慢,但是React能够根据Patch的内容,优化一部分DOM操作,比如之前的那个例子。
重点就在最后,哪怕是我生成了virtual dom(需要耗费时间),哪怕是我跑了diff(还需要花时间),但是我根据patch简化了那些DOM操作省下来的时间依然很可观(这个就是时间差的问题了,即节省下来的时间 > 生成 virtual dom的时间 + diff时间)。所以总体上来说,还是比较快。
简单发散一下思路,如果哪一天,DOM本身的已经操作非常非常非常快了,并且我们手动对于DOM的操作都是精心设计优化过后的,那么加上了VirtualDom还会快吗?当然不行了,毕竟你多做了这么多额外的工作。
但是那一天会来到吗? 诶,大不了到时候不用Virtual DOM。
注: 此部分内容整理自: https://www.zhihu.com/question/29504639/answer/44680878
虚拟DOM的简单实现(diff算法)
目录
1 前言
2 对前端应用状态管理思考
3 Virtual DOM 算法
4 算法实现
4.1 步骤一:用JS对象模拟DOM树
4.2 步骤二:比较两棵虚拟DOM树的差异
4.3 步骤三:把差异应用到真正的DOM树上
5 结语
前言
在上面一部分中,我们已经简单介绍了虚拟DOM的答题思路和好处,这里我们将通过自己写一个虚拟DOM来加深对其的理解,有一些自己的思考。
对前端应用状态管理思考
维护状态,更新视图。
虚拟DOM算法
DOM是很慢的,如果我们创建一个简单的div,然后把他的所有的属性都打印出来,你会看到:
var div = document.createElement('div'),
str = ''; for (var key in div) {
str = str + ' ' + key;
}
console.log(str);

可以看到,这些属性还是非常惊人的,包括样式的修饰特性、一般的特性、方法等等,如果我们打印出其长度,可以得到惊人的227个。
而这仅仅是一层,真正的DOM元素是非常庞大的,这是因为标准就是这么设计的,而且操作他们的时候你要小心翼翼,轻微的触碰就有可能导致页面发生重排,这是杀死性能的罪魁祸首。
而相对于DOM对象,原生的JavaScript对象处理起来更快,而且更简单,DOM树上的结构信息我们都可以使用JavaScript对象很容易的表示出来。
var element = {
tagName: 'ul',
props: {
id: 'list' },
children: {
{
tagName: 'li',
props: { class: 'item' },
children: ['Item1']
},
{
tagName: 'li',
props: { class: 'item' },
children: ['Item1']
},
{
tagName: 'li',
props: { class: 'item' },
children: ['Item1']
}
}
}
如上所示,对于一个元素,我们只需要一个JavaScript对象就可以很容易的表示出来,这个对象中有三个属性:
tagName: 用来表示这个元素的标签名。
props: 用来表示这元素所包含的属性。
children: 用来表示这元素的children。
而上面的这个对象使用HTML表示就是:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
OK! 既然原来的DOM信息可以使用JavaScript来表示,那么反过来,我们就可以用这个JavaScript对象来构建一个真正的DOM树。
所以之前所说的状态变更的时候会从新构建这个JavaScript对象,然后呢,用新渲染的对象和旧的对象去对比, 记录两棵树的差异,记录下来的就是我们需要改变的地方。 这就是所谓的虚拟DOM,包括下面的几个步骤:
用JavaScript对象来表示DOM树的结构; 然后用这个树构建一个真正的DOM树,插入到文档中。
当状态变更的时候,重新构造一个新的对象树,然后用这个新的树和旧的树作对比,记录两个树的差异。
把2所记录的差异应用在步骤一所构建的真正的DOM树上,视图就更新了。
Virtual DOM的本质就是在JS和DOM之间做一个缓存,可以类比CPU和硬盘,既然硬盘这么慢,我们就也在他们之间添加一个缓存; 既然DOM这么慢,我们就可以在JS和DOM之间添加一个缓存。 CPU(JS)只操作内存(虚拟DOM),最后的时候在把变更写入硬盘(DOM)。
算法实现
1、 用JavaScript对象模拟DOM树
用JavaScript对象来模拟一个DOM节点并不难,你只需要记录他的节点类型(tagName)、属性(props)、子节点(children)。
element.js
function Element(tagName, props, children) {
this.tagName = tagName;
this.props = props;
this.children = children;
}
module.exports = function (tagName, props, children) {
return new Element(tagName, props, children);
}
通过这个构造函数,我们就可以传入标签名、属性以及子节点了,tagName可以在我们render的时候直接根据它来创建真实的元素,这里的props使用一个对象传入,可以方便我们遍历。
基本使用方法如下:
var el = require('./element'); var ul = el('ul', {id: 'list'}, [
el('li', {class: 'item'}, ['item1']),
el('li', {class: 'item'}, ['item2']),
el('li', {class: 'item'}, ['item3'])
]);
然而,现在的ul只是JavaScript表示的一个DOM结构,页面上并没有这个结构,所有我们可以根据ul构建一个真正的
:
Element.prototype.render = function () {
// 根据tagName创建一个真实的元素
var el = document.createElement(this.tagName);
// 得到这个元素的属性对象,方便我们遍历。
var props = this.props;
for (var propName in props) {
// 获取到这个元素值
var propValue = props[propName];
// 通过setAttribute设置元素属性。
el.setAttribute(propName, propValue);
}
// 注意: 这里的children,我们传入的是一个数组,所以,children不存在时我们用【】来替代。
var children = this.children || [];
//遍历children
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render()
: document.createTextNode(child);
// 无论childEl是元素还是文字节点,都需要添加到这个元素中。
el.appendChild(childEl);
});
return el;
}
所以,render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归的把自己的子节点也构建起来,所以只需要调用ul的render方法,通过document.body.appendChild就可以挂载到真实的页面了。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>div</title>
</head>
<body>
<script>
function Element(tagName, props, children) {
this.tagName = tagName;
this.props = props;
this.children = children;
}
var ul = new Element('ul', {id: 'list'}, [
new Element('li', {class: 'item'}, ['item1']),
new Element('li', {class: 'item'}, ['item2']),
new Element('li', {class: 'item'}, ['item3'])
]);
Element.prototype.render = function () {
// 根据tagName创建一个真实的元素
var el = document.createElement(this.tagName);
// 得到这个元素的属性对象,方便我们遍历。
var props = this.props;
for (var propName in props) {
// 获取到这个元素值
var propValue = props[propName];
// 通过setAttribute设置元素属性。
el.setAttribute(propName, propValue);
}
// 注意: 这里的children,我们传入的是一个数组,所以,children不存在时我们用【】来替代。
var children = this.children || [];
//遍历children
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render()
: document.createTextNode(child);
// 无论childEl是元素还是文字节点,都需要添加到这个元素中。
el.appendChild(childEl);
});
return el;
}
var ulRoot = ul.render();
document.body.appendChild(ulRoot);
</script>
</body>
</html>
上面的这段代码,就可以渲染出下面的结果了:
2、比较两颗虚拟DOM树的差异
*比较两颗DOM数的差异是Virtual DOM算法中最为核心的部分,这也就是所谓的Virtual DOM的diff算法。 两个树的完全的diff算法是一个时间复杂度为 O(n3) 的问题。 但是在前端中,你会很少跨层地移动DOM元素,所以真实的DOM算法会对同一个层级的元素进行对比。 *
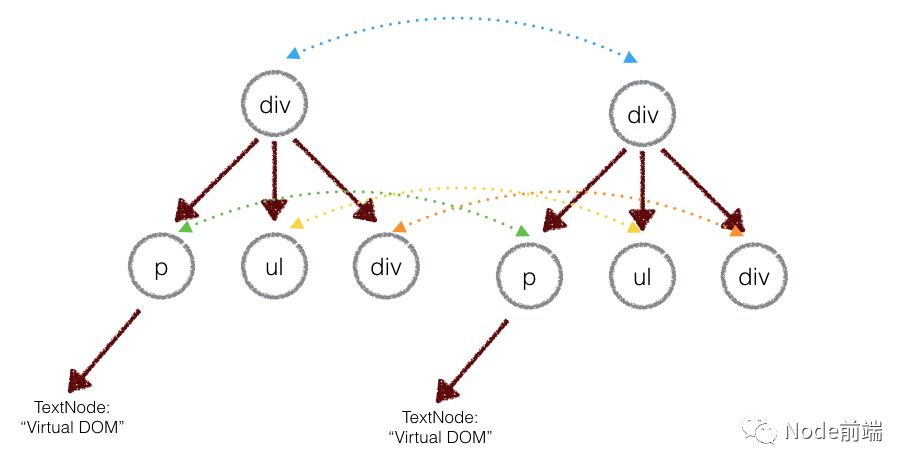
上图中,div只会和同一层级的div对比,第二层级的只会和第二层级对比。 这样算法复杂度就可以达到O(n)。
(1)深度遍历优先,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每一个节点就会有一个唯一的标记:
上面的这个遍历过程就是深度优先,即深度完全完成之后,再转移位置。 在深度优先遍历的时候,每遍历到一个节点就把该节点和新的树进行对比,如果有差异的话就记录到一个对象里面。
// diff函数,对比两颗树
function diff(oldTree, newTree) {
// 当前的节点的标志。因为在深度优先遍历的过程中,每个节点都有一个index。
var index = 0;
// 在遍历到每个节点的时候,都需要进行对比,找到差异,并记录在下面的对象中。
var pathches = {};
// 开始进行深度优先遍历
dfsWalk(oldTree, newTree, index, pathches);
// 最终diff算法返回的是一个两棵树的差异。
return pathches;
}
// 对两棵树进行深度优先遍历。
function dfsWalk(oldNode, newNode, index, pathches) {
// 对比oldNode和newNode的不同,记录下来
pathches[index] = [...];
diffChildren(oldNode.children, newNode.children, index, pathches);
}
// 遍历子节点
function diffChildren(oldChildren, newChildren, index, pathches) {
var leftNode = null;
var currentNodeIndex = index;
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i];
currentNodeIndex = (leftNode && leftNode.count)
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
// 深度遍历子节点
dfsWalk(child, newChild, currentNodeIndex, pathches);
leftNode = child;
});
}
例如,上面的div和新的div有差异,当前的标记是0, 那么我们可以使用数组来存储新旧节点的不同:
patches[0] = [{difference}, {difference}, ...]
同理使用patches[1]来记录p,使用patches[3]来记录ul,以此类推。
(2)差异类型
上面说的节点的差异指的是什么呢? 对DOM操作可能会:
替换原来的节点,如把上面的div换成了section。
移动、删除、新增子节点, 例如上面div的子节点,把p和ul顺序互换。
修改了节点的属性。
对于文本节点,文本内容可能会改变。 例如修改上面的文本内容2内容为Virtual DOM2.
所以,我们可以定义下面的几种类型:
var REPLACE = 0;
var REORDER = 1;
var PROPS = 2;
var TEXT = 3;
对于节点替换,很简单,判断新旧节点的tagName是不是一样的,如果不一样的说明需要替换掉。 如div换成了section,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}]
除此之外,如果给div新增了属性id为container,就记录下:
pathches[0] = [
{
type: REPLACE,
node: newNode
},
{
type: PROPS,
props: {
id: 'container'
}
}
]
如果是文本节点发生了变化,那么就记录下:
pathches[2] = [
{
type: TEXT,
content: 'virtual DOM2'
}
]
那么如果我们把div的子节点重新排序了呢? *比如p、ul、div的顺序换成了div、p、ul,那么这个该怎么对比呢? 如果按照同级进行顺序对比的话,他们就会被替换掉,如p和div的tagName不同,p就会被div所代替,最终,三个节点就都会被替换,这样DOM开销就会非常大,而实际上是不需要替换节点的,只需要移动就可以了, 我们只需要知道怎么去移动。*这里牵扯到了两个列表的对比算法,如下。
(3)列表对比算法
假设现在可以英文字母唯一地标识每一个子节点:
旧的节点顺序:
a b c d e f g h i
现在对节点进行了删除、插入、移动的操作。新增 j节点,删除 e节点,移动 h节点:
新的节点顺序:
a b c h d f g i j
现在知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多,这里不累述,有兴趣可以参考代码。
https://github.com/livoras/simple-virtual-dom/blob/master/lib/diff.js
我们能够获取到某个父节点的子节点的操作,就可以记录下来:
patches[0] = [{
type: REORDER,
moves: [{remove or insert}, {remove or insert}, ...]
}]
但是要注意的是,因为 tagName是可重复的,不能用这个来进行对比。所以需要给子节点加上唯一标识 key,列表对比的时候,使用 key进行对比,这样才能复用老的 DOM 树上的节点。
这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。完整 diff 算法代码可见 diff.js。
3、把差异引用到真正的DOM树上
因为步骤一所构建的 JavaScript 对象树和 render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的 patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes
? node.childNodes.length
: 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}
applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
function applyPatches (node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
5、结语
virtual DOM算法主要实现上面步骤的三个函数: element、diff、patch,然后就可以实际的进行使用了。
// 1. 构建虚拟DOM
var tree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: blue'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li')])
])
// 2. 通过虚拟DOM构建真正的DOM
var root = tree.render()
document.body.appendChild(root)
// 3. 生成新的虚拟DOM
var newTree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: red'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li'), el('li')])
])
// 4. 比较两棵虚拟DOM树的不同
var patches = diff(tree, newTree)
// 5. 在真正的DOM元素上应用变更
patch(root, patches)
当然这是非常粗糙的实践,实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。这些事情都做了的话,就可以构造一个简单的ReactJS了。
> https://www.cnblogs.com/zhuzhenwei918/p/7271305.html
---------
--------
以上是关于深入理解react中的虚拟DOMdiff算法的主要内容,如果未能解决你的问题,请参考以下文章
React简介虚拟DOMDiff算法创建React项目JSX语法组件组件声明方式组件传值props和state组件的生命周期