python爬虫抓取信息的问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫抓取信息的问题相关的知识,希望对你有一定的参考价值。
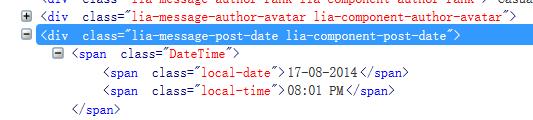
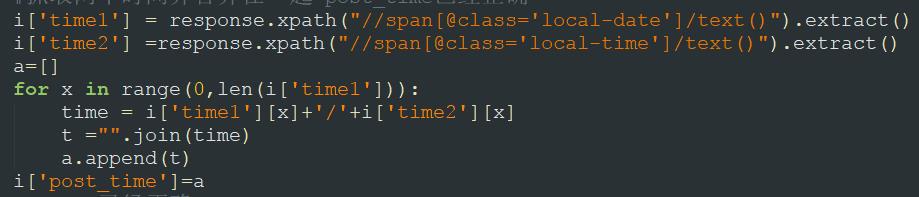
①图是网页上的代码,②图是我根据③图写的语句爬下来的东西。但是我想要的是一图两个时间能合在一起显示成一条信息,求大神指导我一下,谢谢你们~
哦
追答嗯
参考技术B 你直接取DateTime下面的text不就行了,追问你好,谢谢你。
我懂你的意思了,但是这样取出来的是同一个列表的两个值。但是我在pipeline中想把来两个值放在一起输出。不过我昨晚已经想到解决的方法了。谢谢你
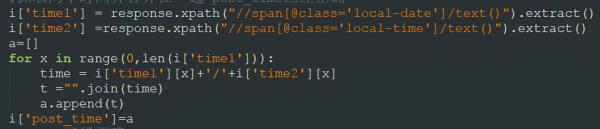
这样可以将两个数据合在一起输出。
基于python的scrapy爬虫抓取京东商品信息
这是上的第二节爬虫课程的课后作业:抓取京东某类商品的信息,这里我选择了手机品类。
使用scrapy爬虫框架,需要编写和设置的文件主要有phone.py , pipelines.py , items.py , settings.py , 其中主要编写的是前两个文件,最后一个文件主要设置破解反爬方法。
phone.py编写程序如下:
import scrapy
from scrapy.http import Request
from jd_phone.items import JdPhoneItem
import re
import urllib.request
class PhoneSpider(scrapy.Spider):
name = "phone"
allowed_domains = ["jd.com"]
start_urls = [‘http://jd.com/‘]
#获取商品手机100页网址
def parse(self, response):
for i in range(1, 100):
url = "https://search.jd.com/Search?keyword=手机&enc=utf-8&page="+str(i*2-1)
yield Request(url=url,callback=self.product_url)
#获取每页商品链接
def product_url(self, response):
urls = response.xpath(‘//div[@class="p-name p-name-type-2"]/a[@target="_blank"]/@href‘).extract()
for i in urls:
url = response.urljoin(i)
yield Request(url=url, callback=self.product)
#获取商品的链接,名称,价格,评论数
def product(self, response):
#获取标题
#title = response.xpath("//li[@class=‘img-hover‘]/img/@alt").extract()#部分网页不行
title = response.xpath("//img/@alt").extract()
#获取id号,用来构造价格和评论的链接
pattern = r"(\d+)\.html$"
id = re.findall(pattern, response.url)
#得到价格
priceUrl = "https://p.3.cn/prices/mgets?&skuIds=J_"+str(id[0])
priceData = urllib.request.urlopen(priceUrl).read().decode("utf-8", "ignore")
patt = r‘"p":"(\d+\.\d+)"‘
price = re.findall(patt, priceData)
#得到评论数
commentUrl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds="+str(id[0])
commentData = urllib.request.urlopen(commentUrl).read().decode("utf-8", "ignore")
patt1 = r‘"CommentCount":(\d+),‘
comment = re.findall(patt1, commentData)
item = JdPhoneItem()
item["url"] = response.url
item["title"] = title[0]
item["price"] = price[0]
item["comment"] = comment[0]
yield itempipelines.py编写程序如下:
import pymysql.cursors
class JdPhonePipeline(object):
#连接登陆mysql,新建数据表
def __init__(self):
self.conn=pymysql.connect(host="127.0.0.1",
user="root",
passwd="123456",
charset=‘utf8mb4‘,
cursorclass=pymysql.cursors.DictCursor)
cur = self.conn.cursor()
cur.execute("CREATE DATABASE jd")
cur.execute("USE jd")
cur.execute("CREATE TABLE phone (id INT PRIMARY KEY AUTO_INCREMENT,url VARCHAR(50),title VARCHAR(50),price VARCHAR(10),comment VARCHAR(10))")
#mysql写入
def process_item(self, item, spider):
try:
url = item["url"]
title = item["title"]
price = item["price"]
comment = item["comment"]
cur = self.conn.cursor()
sql = "INSERT INTO phone (url, title, price, comment) VALUES (‘"+url+"‘,‘"+title+"‘,‘"+price+"‘,‘"+comment+"‘)"
cur.execute(sql)
self.conn.commit()
return item
except Exception as err:
print(err)
#关闭连接
def close_spider(self):
self.conn.close()items.py编写程序如下:
import scrapy class JdPhoneItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() url = scrapy.Field() title = scrapy.Field() price = scrapy.Field() comment = scrapy.Field()
另外不忘settings.py设置常规破解反爬方法。
这个爬虫项目主要学习了:
网页源代码屏蔽数据的获取,使用F12开发人员调试工具获取屏蔽信息的网址,通过下载网址读取数据匹配所需信息。
将抓取的数据写入mysql中。
要将mysql数据写进本地csv文件,使用如下方法
mysql> select * from phone
--> into outfile‘c:/ProgramData/MySQL/MySQL Server 5.7/Uploads/phone.csv‘
--> fields terminated by ‘,‘ optionally
--> enclosed by ‘"‘ escaped by ‘"‘
--> lines terminated by ‘\n‘;
解决导出csv中文乱码的问题,将phone.csv复制到桌面,用记事本打开,然后另存为,选择utf8编码。
如果是要将csv数据写进mysql,使用如下方法(先要创建对应数据表)
mysql> load data infile ‘c:/ProgramData/MySQL/MySQL Server 5.7/Uploads/phone.csv‘
--> into table phone1
--> fields terminated by ‘,‘ optionally
--> enclosed by ‘"‘ escaped by ‘"‘
--> lines terminated by ‘\n‘;
本文出自 “12325998” 博客,请务必保留此出处http://12335998.blog.51cto.com/12325998/1882410
以上是关于python爬虫抓取信息的问题的主要内容,如果未能解决你的问题,请参考以下文章