用爬虫和Flask打造属于自己的电影网站!
Posted 网易云课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用爬虫和Flask打造属于自己的电影网站!相关的知识,希望对你有一定的参考价值。
也许你曾经为了一部电影,找遍全网却没发现任何有用的资源;
也许你曾经被披着电影外衣的网站,忽悠进去而染上木马病毒。
一部小小的电影搞得你心力交瘁,怀疑人生。
不过,作为一名合格的程序员,一向以write the code,change the world所著称,我们写的代码都能改变世界,岂能被这种小事情所屈服?
不是不干,要干就干一票大的!这一次,我们祭上万能的Python语言,用爬虫技术加上Flask框架,打造一个属于自己的电影网站!界面清爽无木马,PC手机随心看!
今年告别单身,征服女神的任务,就从这里开始啦~
01
准备工作
首先你要一个Python解释器
在目前为止,Python存在两大主流的版本,一个是Python2.7,一个是Python3.6。Python2.x历史悠久,支持的库多,但是毕竟是老版本,一些历史遗留的问题未能得到解决,比如编码问题,一些内置函数的执行性能等。
而Python3优化了Python2中的很多底层代码,并且默认的字符串就是unicode类型,无需担心编码问题,很多函数因为使用了生成器而大大的提高了代码的执行效率。
但是Python3因为比较新,所以一些第三方库还来不及支持Python3(比如进程管理工具supervisor就还未支持Python3),但是慢慢的都在支持Python3了,并且Python3也是未来的一个趋势,Python2已经被官方宣布在2020年将全面停止更新。所以现在学Python,首选Python3。
因此我们本个课程,也用Python3来讲解。
如果您还没有安装Python3,可以到官网:https://www.python.org,根据自己的操作系统,选择相应的版本下载。
安装过程非常简单,一顿下一步就可以啦,但是为了不必要的麻烦,给个小提示,千万不要放在有中文的路径下面哦~

安装完Python以后,如果不出意外,应该是已经安装了pip
通过pip可以非常方便的管理Python第三方包。可以在CMD或者任何shell终端输入pip -V,如果提示了找不到pip命令,说明pip没有安装成功。那么可以通过easy_install install pip来进行安装。
requests库
这个库是专门用来做网络请求的。他比Python自带的urllib库好用很多,在urllib3的基础之上做了进一步的封装,让我们写网络请求的时候不要处理一些类似于url编码等相关的无意义的事情。他的slogan是Http for Humans,意思是对人友好的Http请求库,可以说是非常的形象了。这个库不是Python内置的,因此需要通过pip进行安装。安装方式也是非常简单,只要进入cmd或者shell终端,输入pip install requests即可安装。
Scrapy框架
最强大的爬虫框架,没有之一!注意,他不是一个简简单单的库,而是一个框架。实现了从url匹配,到数据下载,数据解析,数据存储等一套完整的组件。让你写爬虫更加轻松,更加健壮,更加高效。我们也是用这个框架来帮我们处理爬虫,这样我们可以不间断的批量的爬取电影信息,然后存储到数据库中。Scrapy也不是Python内置的,需要通过pip install scrapy安装。
MySQL服务器
数据爬取下来后,要存储起来,以后才能通过网页的形式展现出来。存储数据的方式有很多,比如可以存储到JSON文件中、mysql数据库中、SQLite数据库等。而MySQL由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,已经被广泛的应用在了大中小型网站中。我们的数据从网站上爬取下来后,以后还需要用在网站中展示。
因此我们采用MySQL来存储数据。MySQL安装非常简单,可以到MySQL官网下载安装即可
https://dev.mysql.com/downloads/windows/installer/5.7.html
Django框架
Django框架是Python web开发中一款非常主流的框架。上手快,功能齐全,可以胜任大型网站的任务。他也是集HTTP协议、URL匹配、数据库管理、HTML模版渲染等于一体的框架。数据已经从爬到数据库中了,下一步我们就是使用Django框架实现一个网站,动态的加载数据!根据自己的需求,想做成什么样就做成什么样!Django也是第三方的,需要通过pip install django进行安装。
02
项目架构
在写具体的代码之前,先来理顺一下整个项目框架的结构。爬虫负责抓取网站的数据,并对抓取下来的数据进行解析和清洗,然后存储到数据库中。之后Django再从数据库中读取数据,并将读取的数据显示在网页中。结构图如下:
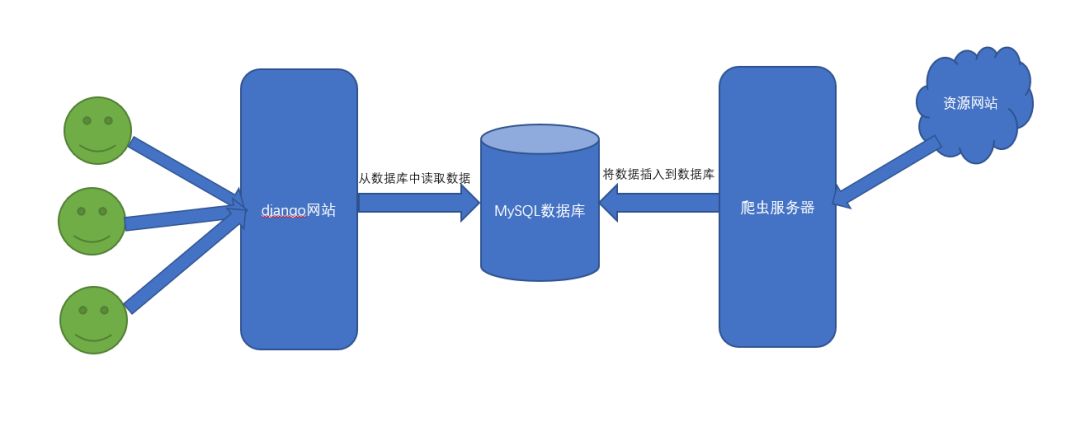
03
爬虫实现
俗话说,巧妇难为无米之炊,再牛逼的爬虫程序如果没有好的数据来源,也爬不到有价值的数据。因此选择一个好的资源网站至关重要。
这里我们选择的是电影天堂和阳光电影两个特别良心的网站。这两个网站上有大量的高清视频资源,每部电影都配有详细的信息,包括演员,导演,年代,类型,豆瓣评分,视频截图等,最重要的是附有迅雷下载链接,可以说是非常良心了。
但是这个网站经常会有一些广告(广告是主要的主要的收入来源),当你在点击某个链接的时候,会首先给你弹出一个新页面,里面嵌入的就是广告资源,然后你再次点击,才能进入到下一个页面。并且有时候这个网站还会被Chrome浏览器识别为病毒网站(不知是否真的有病毒),导致无法正常访问。
另外最后一个就是,这个网站的界面相当不美观,对于我这种审美要求高的(特别是美女(*^_^*))码农来说,实在不能忍受。因此如果我们能把上面的电影资源都爬下来,再按照自己的需求实现一个网站,显示这些信息,那就很有意思了。无论从个人角度还是商业角度来说,都是非常有价值的!这里我们使用的是Scrapy框架来实现的,那么以下主要从数据抓取,数据解析和数据存储三个角度来进行分析:
数据抓取和解析
在写代码之前,我们首先来分析下电影天堂这个网站,他的首页是包含了各种类型资源的一个组合。我们现在要爬取的是电影信息,因此点击“更多最新电影”跳转到最新电影的列表页面,如下图:
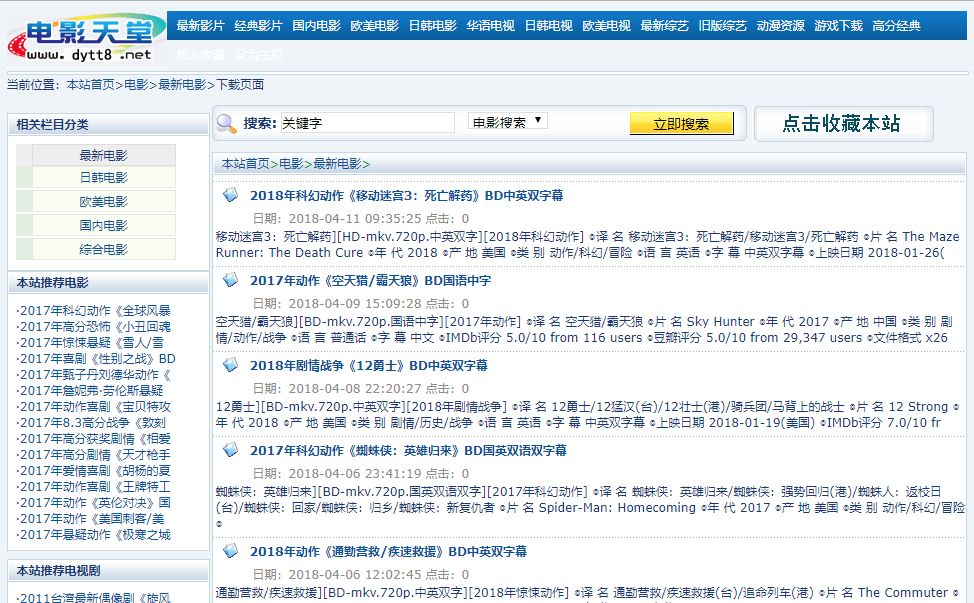
可以看到这个列表页包含了许多我们想要的电影资源,但是我们现在爬,只能爬取到这一页的电影信息,怎么能把其他页面的电影也爬下来呢,这时候就要找到每个页面的url规则了。
我们可以看到,第一页电影的URL是:
http://www.dytt8.net/html/gndy/dyzz/list_23_1.html,
第二页电影的URL是:
http://www.dytt8.net/html/gndy/dyzz/list_23_2.html。
所以我们得出一个结论就是,URL的前面部分都是一样的,最后那个数字是几,代表的是第几页。接下来就是去爬详情页面了。详情页的例图如下:

包括电影的信息、海报,都能在这个里面找到。那么数据爬取的代码如下:
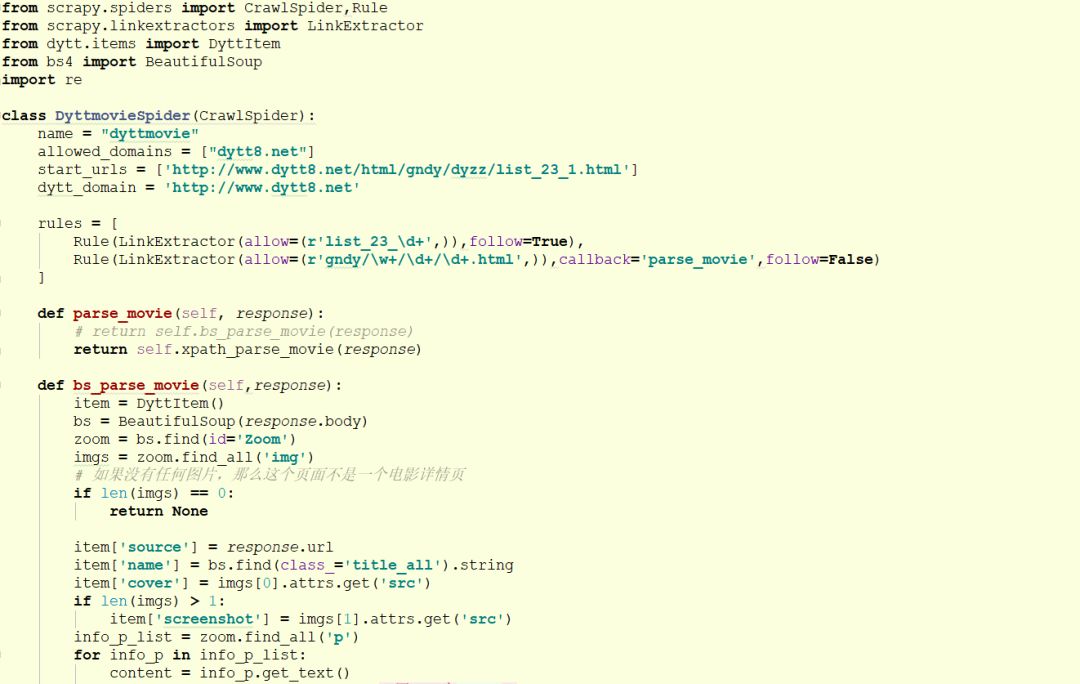
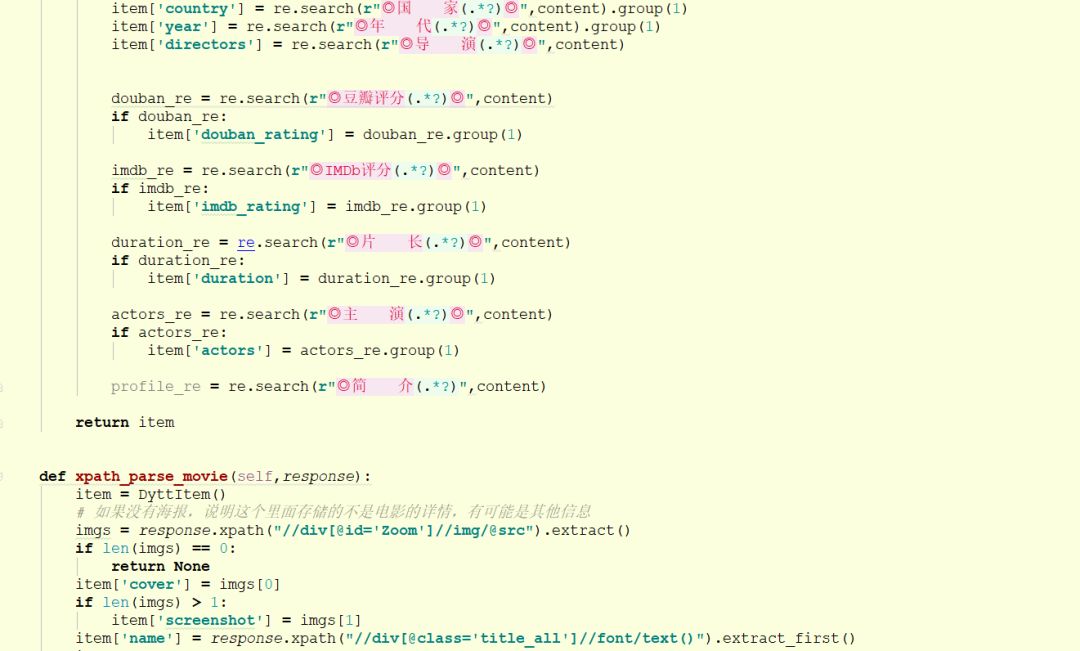
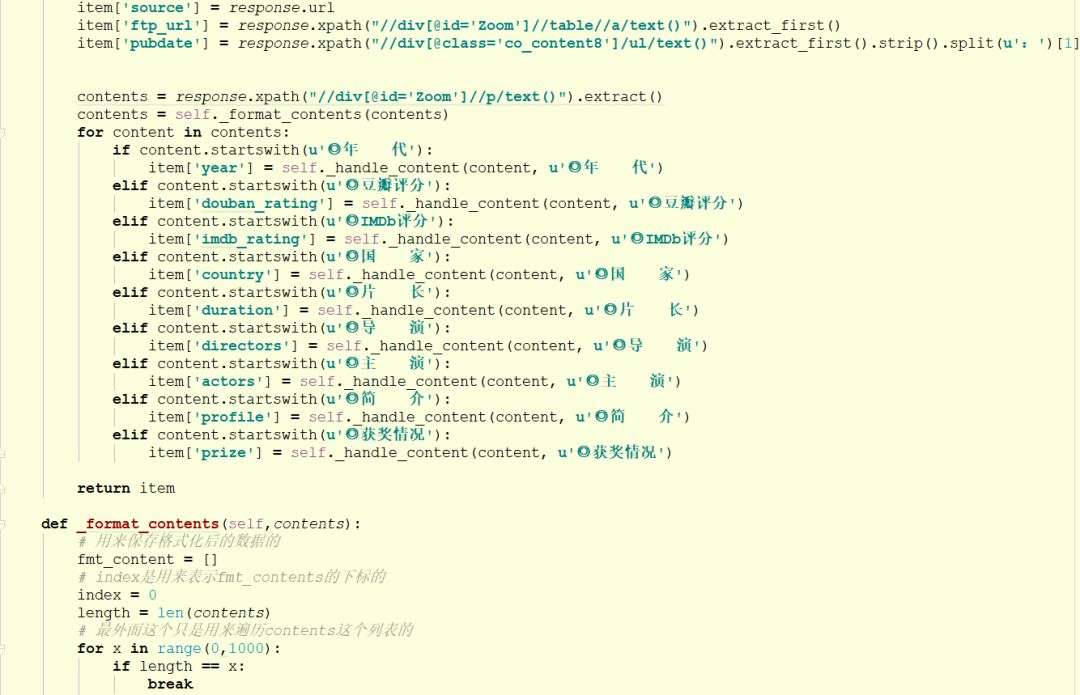

数据存储
这里我们把爬取下来的数据存储到MySQL数据库中。需要在pipeline中进行实现。示例代码如下:
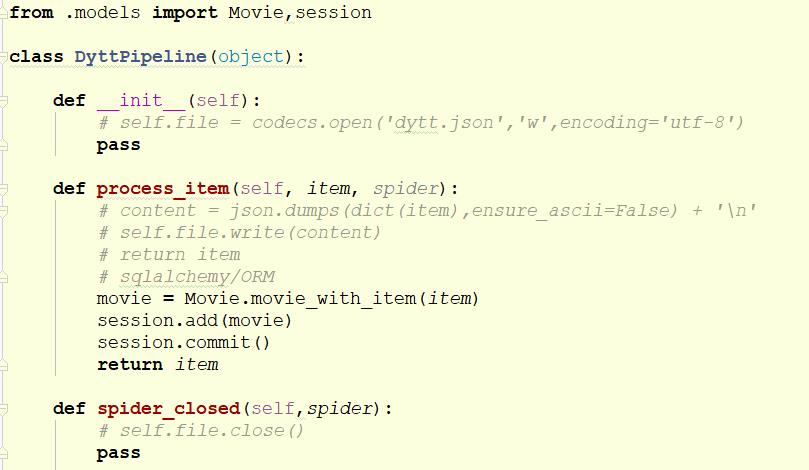
以上便是爬虫部分的讲解和示例代码演示,当然因为篇幅限制,无法把所有细节都介绍到位,如果您对这个项目还有不懂的地方
我们在9月12日在网易云课堂会有直播,从零开始开始讲解,如何分析页面,如何提取元素,scrapy框架是如何运行的等。有什么不懂的还可以和老师进行互动,相信你一定可以学会的!
04
网站实现
网站这里我们用的是Flask框架。在后台做好数据的提取,在前端做好页面的显示。示例代码如下:
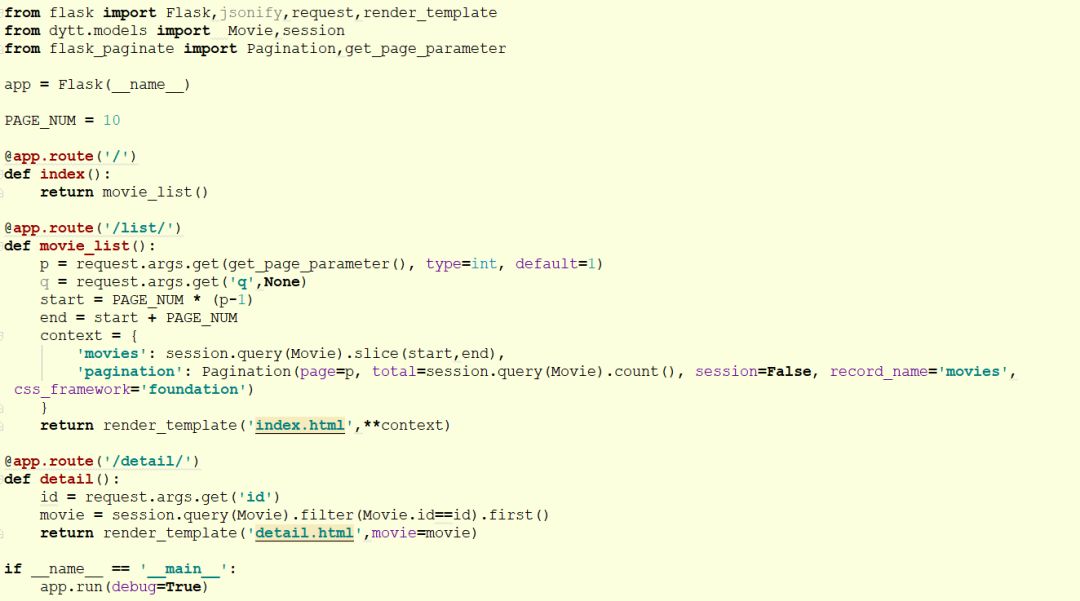
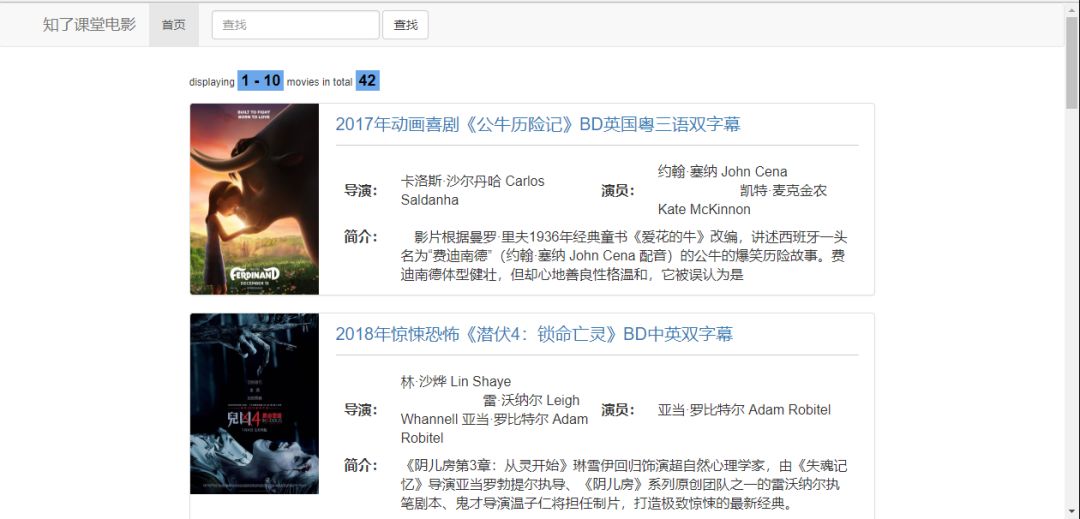
做完后的效果图如下(只是简简单单的做了个demo,UI还需要进一步美化):
05
总结
这个项目可以说是用到了Python大部分的技术要点。有Python网络爬虫、Scrapy框架、Python web开发、Flask框架等,内容比较丰富,知识点太多。无法通过一篇简单的文章把所有技术细节都介绍到位。
如果您对这个项目感兴趣,并且想要进一步学习,可以在9月12日晚8点半,知了课堂和网易云课堂联合举办了一场免费的直播盛宴,
我将从零开始,为您讲述这个项目背后的一切技术要点,您将获得以下收益:
Python实战体验
网络爬虫实战技巧
数据解析技术要点
Python web开发技术流程
Flask、Django框架的使用
数据爬下来,如何产生价值
用爬虫和Flask/Django技术实现自己的电影网站
9月12日
免费直播课程等你来!

悄咪咪告诉你
网易云课堂“职场新势力周”活动已经开始了!
更多优惠、更多福利等你来!
点击“阅读原文",查看“职场新势力周”更多优惠课程!
以上是关于用爬虫和Flask打造属于自己的电影网站!的主要内容,如果未能解决你的问题,请参考以下文章