源码解读:Flask 上下文核心机制
Posted Python编程时光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码解读:Flask 上下文核心机制相关的知识,希望对你有一定的参考价值。
第一时间关注Python技术干货!
在上周的一篇文章中,我跟大家一起深入了解了一下Python的「 」。而今天呢,还是和上下文有关的话题。只不过这里的上下文和上一节的内容有点不一样,上下文管理器是管理代码块级别的上下文,而今天要讲的上下文是工程项目中的上下文。
可能你现在对上下文这个概念,还是不太清楚。这里再简单说明一下
一段程序或函数的运行,很多情况下,是需要依赖程序外的变量才能够运行的,一旦脱离了这些变量,程序就没法正常工作。这些外部变量,按照常规的做法,是将这些变量做为函数的参数,一个一个地传入进去。这是一种做法,对于简单的小程序完全没有问题,一旦在较大的工程项目中,还采用这样的做法,就显得过于笨重,不灵活了。
一个较好的做法是,将这些项目全局中需要频繁用到的变量值整合在一起,而这些值的集合就是上下文。只要在需要的时候,从这个上下文中取就好了。
在 Flask 中,有两种上下文
application context
request context
application context 会存储一个 app 里可以全局共享里的变量。而 request context 会存储一个从外部发起的请求的所有信息。
一个 Flask 项目里,可以有多个 app, 而在一个 app 里会有多个 request。这是它们之间的对应关系。
上面说了,上下文可以实现 信息共享,但同时有一点很重要,就是 信息隔离 。在多个 app 同时运行的时候,要能保证一个 app 不能访问和改变到另一个 app 的变量。这个很重要。
那么具体是如何做到 信息隔离 的呢?
接下来,就要提到在 Flask 中三个很常见的对象,对于有过 Flask 开发经验的你应该不会感到陌生。
Local
LocalStack
LocalProxy
这三个对象都是 werkzeug 里提供的,定义在 local.py 里,所以它们并不是Flask 中特有的, 这就意味着我们可以直接在自己的项目中使用它们,而不用依托于 Flask 的环境。
1. Local
首先是 Local ,记得在以前的「并发编程系列」的线程的 信息隔离 的时候,提过了 threading.local ,它是专门用来存储当前线程的变量,从而实现对象的线程隔离。
而 Flask 里的 Local 和这它的是一个作用。
为了搞懂这个 Local 的作用,最好的方式就是直接对比两段代码。
首先是,不使用 Local 的情况,我们新建一个类,里面有name属性,默认为 wangbm,然后开始一个线程,做的事就是将这个 name 属性改为 wuyanzu。
import time
import threading
class People:
name = 'wangbm'
my_obj = People()
def worker():
my_obj.name = 'wuyanzu'
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print(my_obj.name)
执行结果可想而知,是 wuyanzu 。说明子线程 对对象的更改可以直接影响到主线程。
接下来,我们使用 Local 来实现一下
import time
import threading
from werkzeug.local import Local
class People:
name = 'wangbm'
my_obj = Local()
my_obj.name = 'wangbm'
def worker():
my_obj.name = 'wuyanzu'
print('in subprocess, my_obj.name: '+str(my_obj.name))
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print('in mainprocess, my_obj.name: '+str(my_obj.name))
打印结果如下,可见子线程的修改并不会影响主线程
in subprocess, my_obj.name: wuyanzu
in mainprocess, my_obj.name: wangbm
那么 Local 是如何做到的呢,其实原理很简单,就是利用了基本的数据结构:字典。
当线程去修改 Local 对象里的变量(包含变量名 k1 和变量值 v1 )时,通过源码可知,他是先获取当前线程的id,作为__storage__ (这个storage是个嵌套字典)的key,而value 呢,就是一个字典,{k1: v1}
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
举例如下(伪代码)
# 0 和 1 是线程 id
self.__storage__['0'][k1] = v1
self.__storage__['1'][k2] = v2
正时因为用了线程id 作了一层封装,才得以实现了线程隔离。
如果要用图来表示,最开始的Local对象就是一个空盒子

当有不同的线程往里写数据时,Local 对象为每个线程分配了一个 micro-box。
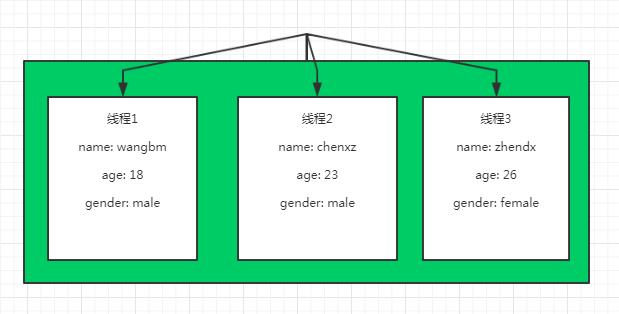
local 是需要被 localmanager 管理的,在请求结束后,会调用 localmanager.cleanup() 函数,其实是调用 local.__release_local__ 进行数据清理。是如何做到的呢,看下面这段代码。
from werkzeug.local import Local, LocalManager
local = Local()
local_manager = LocalManager([local])
def application(environ, start_response):
local.request = request = Request(environ)
...
# make_middleware会确保当request结束时,所有存储于local中的对象的reference被清除
application = local_manager.make_middleware(application)
以下就是 Local 的代码,有需要的可以直接看这里。
class Local(object):
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __iter__(self):
return iter(self.__storage__.items())
def __call__(self, proxy):
"""Create a proxy for a name."""
return LocalProxy(self, proxy)
def __release_local__(self):
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
def __delattr__(self, name):
try:
del self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
2. LocalStack
通过对 Local 的介绍,可以知道 Local 其实是通过封装了字典的,以此实现了线程隔离。
而接下来要介绍的 LocalStack ,也是同样的思想,LocalStack 是封装了 Local ,所以它既有了 Local 的线程隔离的特性,也有了栈结构的特性,可以通过 pop,push,top 来访问对象。
同样用一张图来表示
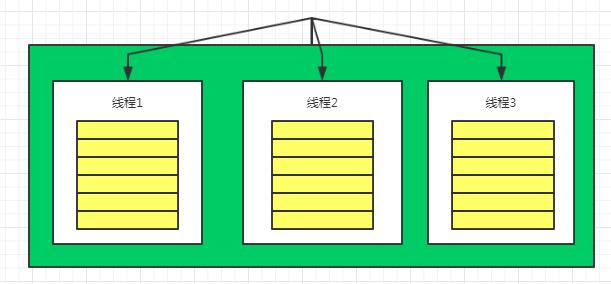
栈结构的特性,无非就是后进先出。这里就不说了,这里的重点是线程隔离的特性如何体现,还是以上面的例子,稍微做了下修改。
import time
import threading
from werkzeug.local import LocalStack
my_stack = LocalStack()
my_stack.push('wangbm')
def worker():
print('in subthread, my_stack.top is : '+str(my_stack.top) + ' before push')
my_stack.push('wuyanzu')
print('in subthread, my_stack.top is : ' + str(my_stack.top) + ' after push')
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print('in main thread, my_stack.top is : '+str(my_stack.top))
输出的结果如下,可见子线程的里的 my_stack 和主线程里的 my_stack 并不能共享,确实实现了隔离。
in subthread, my_stack.top is : None before push
in subthread, my_stack.top is : wuyanzu after push
in main thread, my_stack.top is : wangbm
在 Flask 中,主要有两种上下文,AppContext 和 RequestContext。
当一个请求发起后,Flask 会先开启一个线程,然后将包含请求信息的上下文 RequestContext 推入一个 LocalStack 对象中(_request_ctx_stack),而在推入之前,其实它会去检测另一个 LocalStack 对象(_app_ctx_stack)是否为空(但是一般 _app_ctx_stack 都不会为空),如果为空就先将app的上下文信息push到_app_ctx_stack,然后再去把请求的上下文信息push到_request_ctx_stack 里。
在flask中有三个对象比较常用
current_app
request
session
这三个对象,永远是指向LocalStack 栈顶的上下文中对应的app、request或者session,对应的源码如下:
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))
3. LocalProxy
通过上面的代码,你可以发现,我们访问LocalStack里的元素的时候,都是通过LocalProxy 来进行的有没有?
这就很奇怪了,为什么不直接访问Local 和 LocalStack呢?
这应该是个难点,我这边举个例子,也许你就明白了。
首先是不使用LocalProxy的情况
# use Local object directly
from werkzeug.local import LocalStack
user_stack = LocalStack()
user_stack.push({'name': 'Bob'})
user_stack.push({'name': 'John'})
def get_user():
# do something to get User object and return it
return user_stack.pop()
# 直接调用函数获取user对象
user = get_user()
print user['name']
print user['name']
输出结果是
John
John
使用LocalProxy后
# use LocalProxy
from werkzeug.local import LocalStack, LocalProxy
user_stack = LocalStack()
user_stack.push({'name': 'Bob'})
user_stack.push({'name': 'John'})
def get_user():
# do something to get User object and return it
return user_stack.pop()
# 通过LocalProxy使用user对象
user = LocalProxy(get_user)
print user['name']
print user['name']
输出结果
John
Bob
怎么样,看出区别了吧,直接使用LocalStack对象,user一旦赋值就无法再动态更新了,而使用Proxy,每次调用操作符(这里[]操作符用于获取属性),都会重新获取user, 从而实现了动态更新user的效果。
每次 user['name'] 的时候 就会触发 LocalProxy 类的 __getitem__,从而调用该类的 _get_current_object。而每次 _get_current_object都会返回 get_user()(在flask中对应的函数是 _lookup_req_object ) 的执行结果, 也就是 user_stack.pop()
这样就能实现每次对栈顶元素的操作,都是面对最新元素执行的。
4. 经典错误
在 Flask 中经常会遇到的一个错误是:
Working outside of application context.
这个错误,如果没有理解 flask 的上下文机制,是很难理解的。通过上面知识背景的铺垫,我们可以尝试来搞懂一下为什么会出现这样的情况。
首先我们先来模拟一下这个错误的产生。假设现在有一个单独的文件,内容如下
from flask import current_app
app = Flask(__name__)
app = current_app
print(app.config['DEBUG'])
运行一下,会报如下错误。
Traceback (most recent call last):
File "/Users/MING/PycharmProjects/fisher/app/mytest/mytest.py", line 19, in <module>
print(app.config['DEBUG'])
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/werkzeug/local.py", line 306, in _get_current_object
return self.__local()
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/flask/globals.py", line 51, in _find_app
raise RuntimeError(_app_ctx_err_msg)
RuntimeError: Working outside of application context.
你一定会奇怪吧。我明明也实例化一个app对象,但是为什么取current_app会报错呢?而如果不用current_app,就不会报错。
如果你认真学习了上面的内容,这边也就不难理解了。
从先前的研究发现,当使用current_app时,它取的是LocalStack的栈顶元素(app的上下文信息),而实际上在我们通过app = Flask(__name__)实例化一个app对象时,此时还没有将这个上下文信息写入LocalStack,自然取栈顶元素就会出错了。
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
上面我们也说过了,这个上下文什么时候push进去呢?在外部发起一起request请求后,首先就会先检查 app 的上下文信息是否已经 push 进去了,如果没有的话,就会先将其push进去。
而上面我们是以运行单个文件的方式,并没有实际产生一个 request 请求,自然 在 LocalStack 里没有 app的上下文信息。报错也是正常的。
知道了错误根源后,如何解决这种问题呢?
在Flask中,它提供了一个方法ctx=app.app_context()可以获取一个上下文对象,我们只要将这个上下文对象 手动 push 到 LocalStack 中,current_app 也就可以正常取到我们的app对象了。
from flask import Flask, current_app
app = Flask(__name__)
ctx = app.app_context()
ctx.push()
app = current_app
print(app.config['DEBUG'])
ctx.pop()
由于 AppContext 类实现了上下文协议
class AppContext(object):
def __enter__(self):
self.push()
return self
def __exit__(self, exc_type, exc_value, tb):
self.pop(exc_value)
if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)
所以你也可以这样写
from flask import Flask, current_app
app = Flask(__name__)
with app.app_context():
app = current_app
print(app.config['DEBUG'])
以上,是我学习七月的flask课程加上自己直白的文字与图片所做的笔记,希望对你在理解 Flask的上下文核心机制 会有帮助。如有讲的不对的,还请你指教一下。
-END-
推荐阅读
以上是关于源码解读:Flask 上下文核心机制的主要内容,如果未能解决你的问题,请参考以下文章