论文分享 | 自然语言推理的可分解注意力模型
Posted 广东大数据重点实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文分享 | 自然语言推理的可分解注意力模型相关的知识,希望对你有一定的参考价值。
报告人:郭泽颖
论文题目:A Decomposable Attention Model for Natural Language Inference
论文来源:EMNLP 2016
>>>> 获取完整PDF下载
本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mechanism)将问题分解为可以单独解决的子问题,从而实现了并行化。在斯坦福自然语言推理(SNLI)数据集上,本文工作取得了极好的效果,并且比之前的工作减少了一个数量级的参数数量,而且模型结构不依赖任何单词顺序信息。延伸模型加入了句子内的Attention以考虑一部分单词词序信息,得到更好的提升效果。
1.背景介绍
a) Natural Language Inference自然语言推理任务
使用自然语言进行推理的能力是许多NLP任务(如信息提取,机器翻译和问答)的基本前提条件。NLI任务是给定两个句子A和B,预测句子间的关系:
·推演(Entailment):如果文本A是真的,那么文本B一定为真。
·矛盾(Contradiction):如果文本A是真的,那么文本B一定为假。
·中性(Neutral):上述两者都不是。
例如:
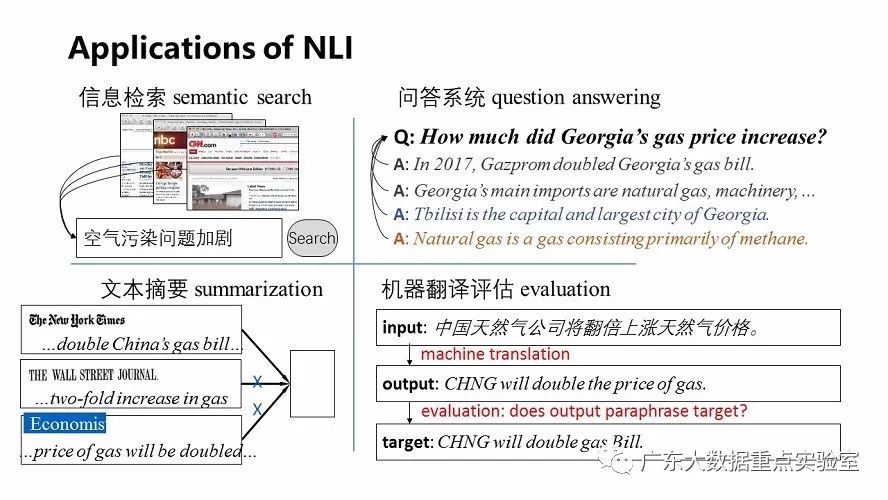
应用:文本相似度,意见挖掘,关系抽取,知识推理/问答等等。
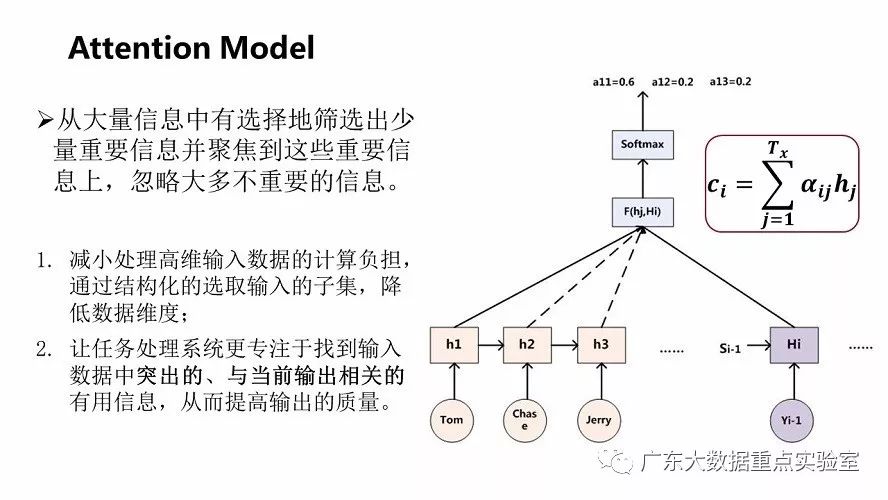
 b)Attention Model注意力模型
b)Attention Model注意力模型
人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,可以极大地提高信息处理的效率与准确性。深度学习抽象出了注意力机制的本质思想,对输入序列计算概率分布信息。
2.相关工作
自然语言推理任务的方法分为以下两种:
传统方法:
(1)基于特征结合的分类:多种相似度如词性标注、命名实体的自然语言处理基础技术;
(2)基于对齐的方法:利用文本的相关性如N-gram,动词反义词等的对应关系。
深度学习方法:
(1)基于句子表示的方法:Sentence Embedding(LSTM/CNN/…),把句子表示成向量再分类;
(2)基于句子匹配的方法:引入Attention机制,关注对判断句子蕴含关系起到重要作用的词,给予相对较高的权重。
本文主要讨论的是深度学习相关方法,下面讨论两篇相关工作:
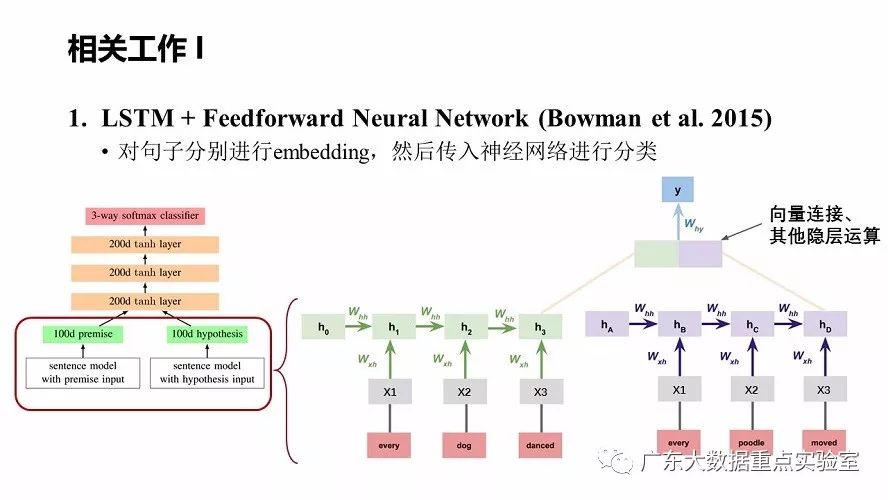
a) LSTM + Feedforward Neural Network (Bowman et al. 2015)
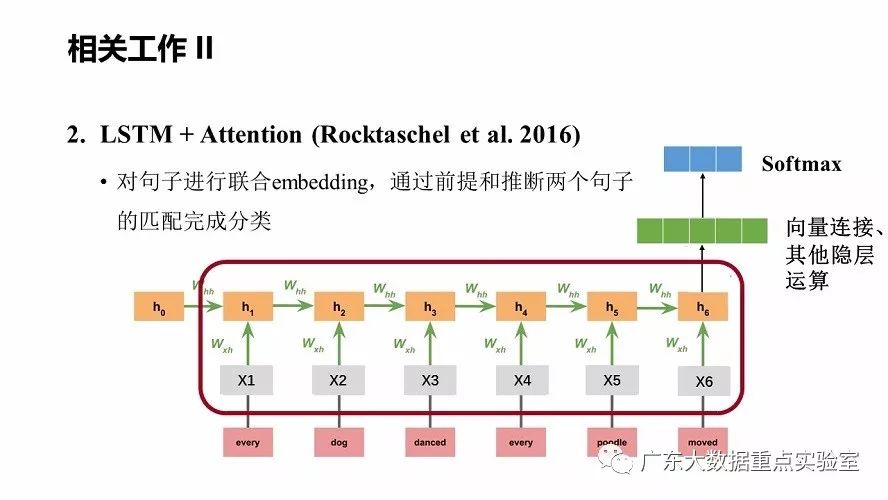
 b)LSTM + Attention (Rocktaschel et al. 2016)
b)LSTM + Attention (Rocktaschel et al. 2016)
3.本文方法
动机:
(1)现在大部分模型的工作都是利用预训练的词向量,得到句子向量表达,依赖主流的语言模型求解思路完成句子的匹配和概率生成;
(2)对句子进行编码-解码耗时、参数多,例如LSTM/GRU等模型结构,对长句子做sentence representation的时候较为困难,不一定能很好的表达语义;
(3)使用seq2seq模型还存在的问题是不能并行计算,使得时间周期长。
本文提出在NLI任务上,不需要对句子进行复杂建模,而是分解问题——单词的对齐,实现并行解决;相比其他模型减少了更多参数(减少到10%),并达到很好的效果。

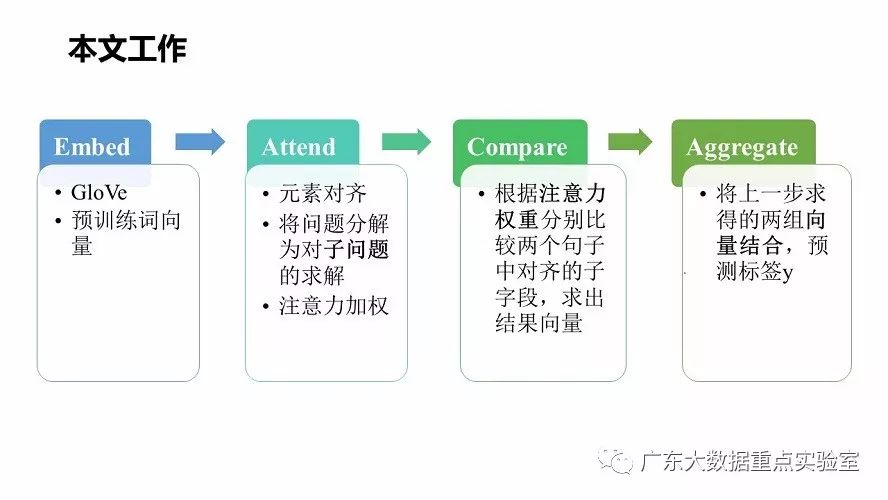
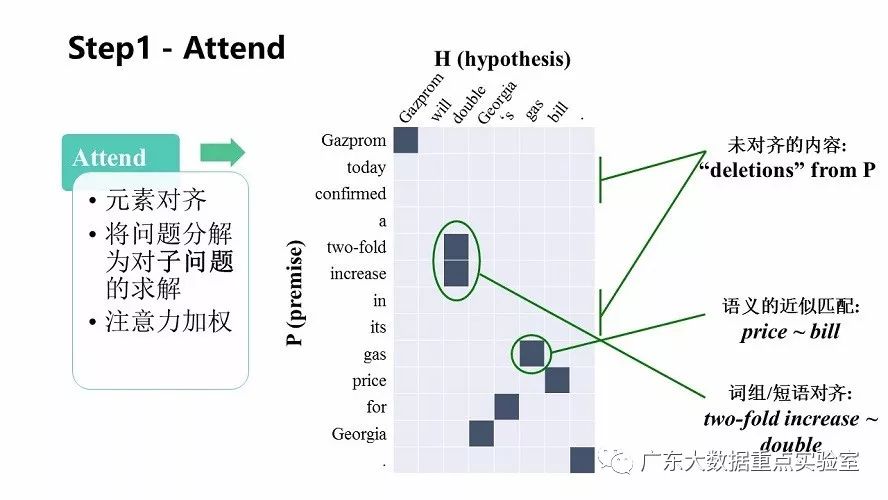
1.Attend

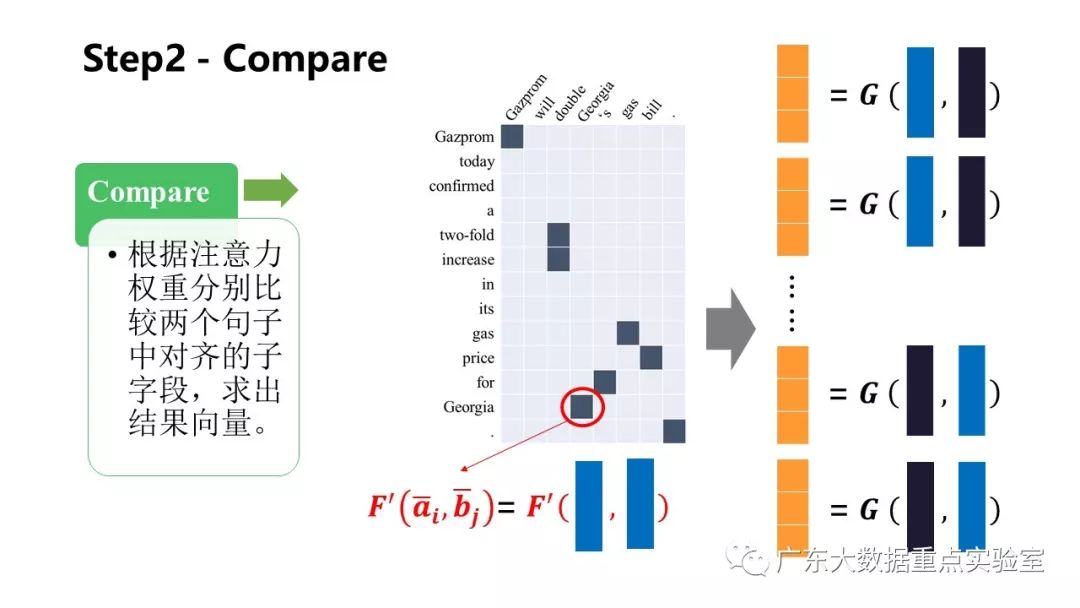
2.Compare
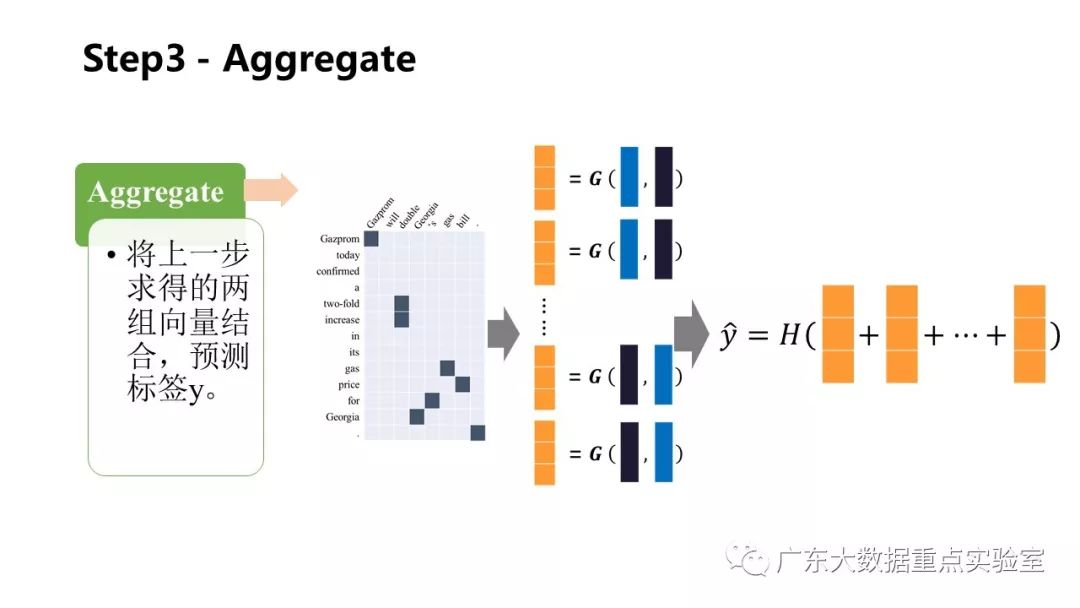
 3.Aggregate
3.Aggregate

除了上述的基础模型之外,可以在每个句子中使用句子内的attention方式来加强输入词语的语义信息。
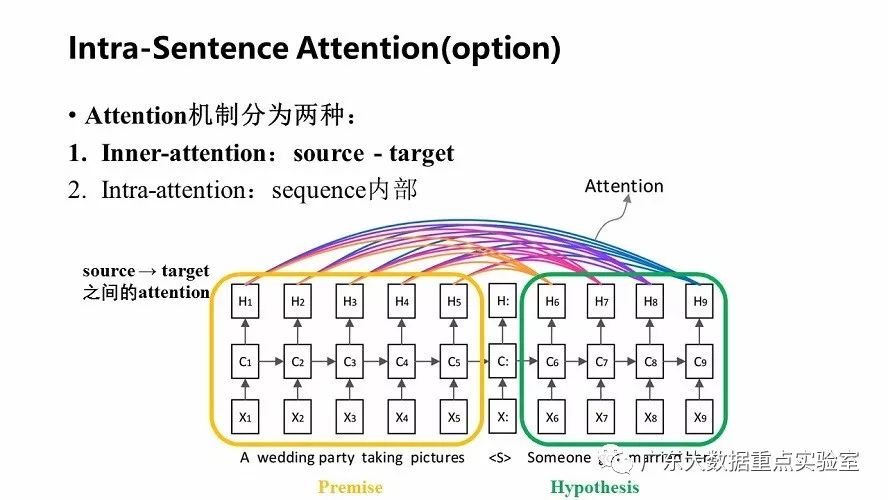
比如对于英-中机器翻译来说,source是英文句子,target是对应的翻译出的中文句子,inner-attention机制发生在target的元素query和source中的所有元素之间。
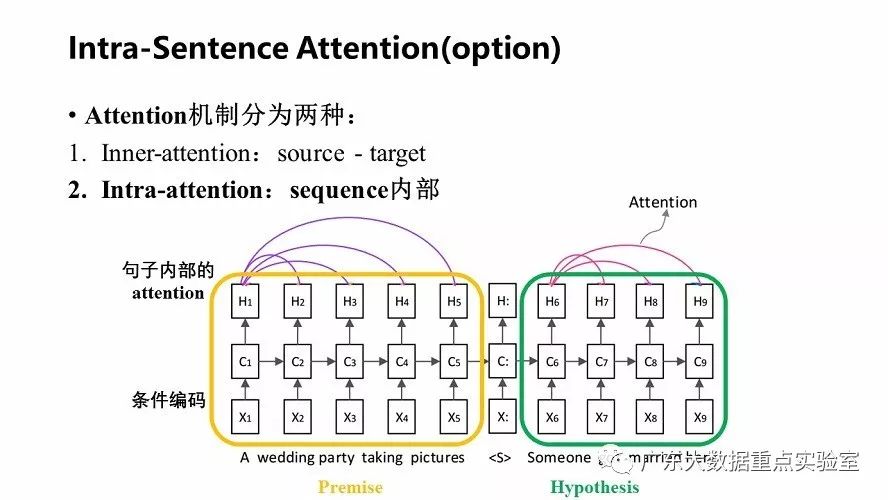
而intra-attention机制发生在source内部元素之间或者Target内部元素之间。Intra-attention可以捕获同一个句子内单词之间的联系,例如语法特征、语义特征等;计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征;可以增加计算的并行性。
4. 实验及结果
数据集:SNLI (Bowman et al. 2015)
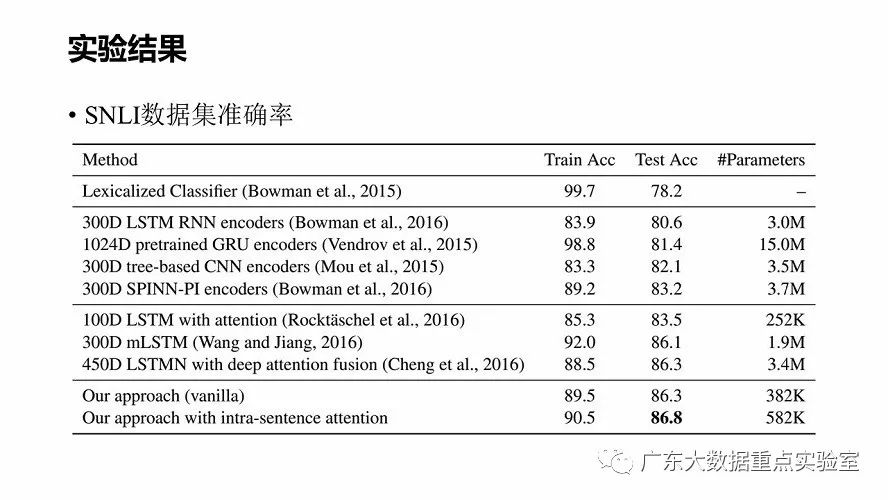
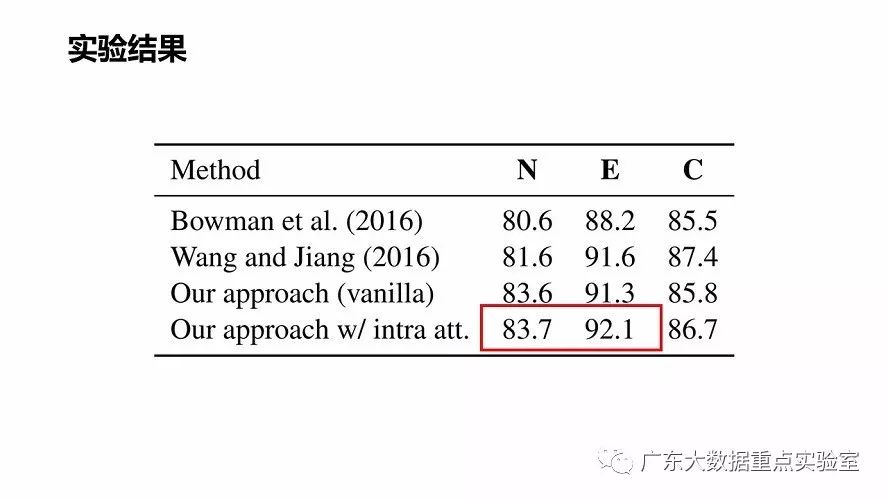
5. 总结
(1) 在NLI任务上分解成子问题,并行解决,相比其他模型减少了更多参数,并达到很好的效果;
(2) NLP工作的新思路,不需要句子结构深入建模,通过对齐文本也能达到很好的实验结果。
(3) 本文将NLI任务当做是关键问题,并直接解决这个问题,因此比单独给句子编码有巨大的优势;Bowman等其他方法则更关注问题的泛化,也是针对此来构建模型,适用的场景会比本文模型更广泛。
6. 参考文献
[1] Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of EMNLP.
[2] Tim Rocktaschel, Edward, Grefenstette, Karl Moritz Hermann, Tomáš Kočiský, and Phil Blunsom. 2016. Reasoning about entailment with neural attention. In Proceedings of ICLR
[3] Dzmitry Bahdanau, HyungHyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of ICLR
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin . 2017. Attention Is All You Need. In Proceedings of NIPS
文/编辑 by 聂梦蝶
以上是关于论文分享 | 自然语言推理的可分解注意力模型的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读117通过中文自然语言推理研究多语言预训练语言模型中的迁移学习