自然语言教育人工智能
Posted 吴老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言教育人工智能相关的知识,希望对你有一定的参考价值。
尽管有了极大的进步,人工智能在许多方面仍旧有限。例如,在计算机游戏中,如果 AI 智能体没用游戏规则预编程,在知道如何做出正确行为之前它需要进行百万次的尝试。人类能在非常短的时间内完成同样的成就,因为我们善于使用语言将过去的知识迁移到新任务中。
在必须杀死龙才能获胜的游戏中,如果需要杀死龙才能获胜,AI 智能体在理解自己必须要屠龙之前需要尝试许多其他的行为(在墙上喷火、发出一片花等)。然而,如果 AI 智能体理解语言,人类就可以简单地使用语言直接指令它「杀死龙赢得游戏。」
以视觉为基础的语言在我们如何归纳技能和将它们应用到新任务上扮演着重要的角色,而这对机器而言仍旧是一个重大挑战。对于让机器变得真正智能并且获得类人的学习能力而言,开发复杂的语言系统是非常重要的。
作为实现这一目标的第一步,我们使用监督学习和强化学习的组合开发了一个系统,该系统允许虚拟教师(virtual teacher)通过将语言与感知和行动连接起来而从头教授虚拟 AI 智能体语言,这一过程就类似于父母教导他们的小孩。
在训练后,我们的模型结果表明 AI 智能体能以自然语言的方式正确地解读教师的指令,并采取相应的行动。更重要的是,这些智能体发展出了我们所说的「zero-shot 学习能力」,这意味着智能体能理解未见过的句子。我们相信该项研究能进一步带领我们朝训练机器像人类一样学习前进。
研究概述
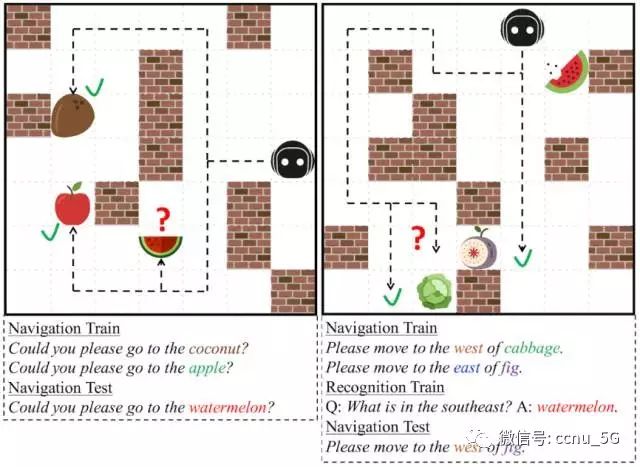
该研究发生在一个 2D 迷宫似的环境 XWORLD 中,在这里,我们的虚拟婴儿智能体需要在自然语言命令的指导下在迷宫里穿行,这个命令是由一个虚拟 teacher 发出的。开始,该智能体对语言一无所知:每个词都对其没有意义。不过,随着该智能体不断研究周围环境,如果执行对了(或者错了)命令,该 teacher 就会给出相应的奖惩。为了帮助智能体更快地学习,该 teacher 也会问些有关智能体所运动的周围环境的简单问题。该智能体需要正确回答问题。通过鼓励对的行动/回答,惩罚错误的行动/回答,该 teacher 能在多次试错时候 让该智能体理解自然语言。
示范命令的一些例子:
请导航至这个苹果(Please navigate to the apple.)
你能移动到苹果和香蕉之间的格子吗?(Can you move to the grid between the apple and the banana?)
你能去那个红苹果那里吗?(Could you please go to the red apple?)
问答对的一些例子:
问:北边的物体是什么?答:香蕉(Q:What is the object in the north? A:Banana.)
问:香蕉在哪里?答:北边(Q:Where is the banana? A:North.)
问:苹果西边的物体是什么颜色的?答:黄色(Q:What is the color of the object in the west of the apple? A:Yellow.
结果
在最后,该智能体可以正确地解读 teacher 的命令,并导航至正确的位置。更加重要的是,该智能体发展出了所谓的「zero-shot 学习能力」。这意味着即使是接受了从未执行过的新任务,如果该指令的句式的相似形式在之前已经见过足够多了,那么它仍然有能力正确地执行任务。换句话说,人工智能有能力理解由已知词和已知语法组成的新句子。
比如说,一个学会用刀切苹果的人通常知道怎样用刀切一个火龙果。应用已有知识实现新的任务对于人类而言是轻而易举的事,但对目前的端到端机器学习来说非常困难。尽管机器可能知道「火龙果」看起来是什么样子,但除非已经经过了相关数据集的训练,它无法执行「用刀切那个火龙果」的任务。相比之下,我们的智能体可以成功地迁移它所知道的火龙果外观与任务「用刀切 X」,而不需要直接去训练「用刀切火龙果」。
在下图中,我们的智能体成功地在导航测试中执行了命令,完成任务。
我们的下一步研究有两个方面:1、在当前 2D 环境中使用自然语言命令来教人工智能获得更多能力;2、把这种能力应用到虚拟 3D 环境中。虚拟的 3D 环境有更多的挑战,同时也与我们所生活的现实环境更加接近。我们的最终目标是用人类的自然语言训练出一个在真实世界中可用的物理机器人。
论文:一个用于虚拟环境中的类人语言习得的深度组合框架
(A Deep Compositional Framework for Human-like Language Acquisition in Virtual Environment)
论文链接:https://arxiv.org/pdf/1703.09831.pdf
摘要
我们在一个称作 XWORLD 的迷宫般的 2D 环境之中完成了智能体学习导航的任务。在每一个 session 中,该智能体可感知一个原始像素帧序列、一个 teacher 发出的自然语言指令和一组奖励(reward)。该智能体能以一种基础的组合式的方式从头学习 teacher 的语言,以至于完成训练之后,它可以正确地执行 zero-shot 指令:1) 指令之中词的组合以前从未出现,并且/或者 2) 指令包含从另一个任务而不是从导航学来的新的目标概念。我们端到端地训练了该智能体的深度框架:它能同时学习环境的视觉表征、语言的句法和语义以及输出行动的行动模块(action module)。我们框架的 zero-shot 学习能力来自带有参数约束的组合性(compositionality)和模块性(modularity)。我们视觉化了框架的中间输出,以证明该智能体真正可以理解如何解决问题。我们相信我们的成果能为如何在 3D 环境中训练带有相似能力的智能体提供初步的见解。
以上是关于自然语言教育人工智能的主要内容,如果未能解决你的问题,请参考以下文章