科普是自然语言太深,还是科大讯飞失真?
Posted 机器人文明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了科普是自然语言太深,还是科大讯飞失真?相关的知识,希望对你有一定的参考价值。
阅读关键词:自然语言理解 科大讯飞
科大讯飞事件,不仅仅是道德风险。
进入今天的主题之前,先说一则曾经风靡全球的爆炸新闻。
去年十月,一个叫“索菲亚”的美女机器人获得了沙特公民身份,一时间风光无两。因外观酷似人类,索菲亚被冠以“最像人类的机器人”头衔,但真正让其自带流量的,是她“可以和人类无障碍沟通的幽默谈吐”。

两个多月,在《早安英国》、《吉米今夜秀》和
《60 Minutes》创下超高收视率的索菲亚,成为
了举世闻名的机器人世界公民。
但事实上,所谓的“对答如流”不过是一场哗众取宠的闹剧。在一些AI行业会议上,就有做语音的企业表示说,如果索菲亚的技术水准真如她表现出来的这样,那其它语音公司可以都不用干了,潜台词是“背后肯定有猫腻”。但行业议论归议论,媒体为了博得关注依旧给普罗大众灌输着美女机器人的“谎言”。
直到一个耿直技术男实在看不下去了。
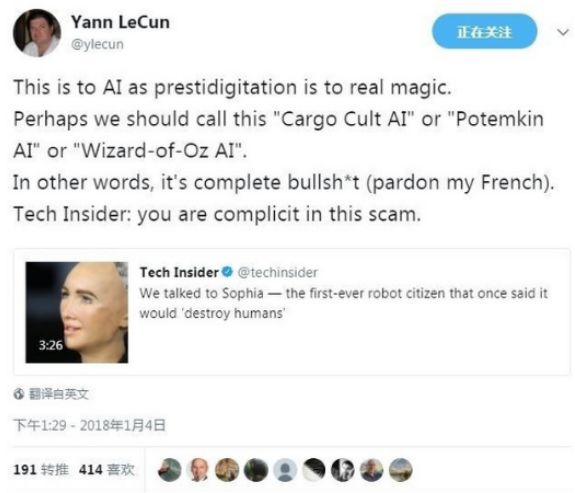
Yann LeCun:“索菲亚之于 AI,就像魔术之于真正的魔法。也许我们应该把这称为“对AI的货物崇拜”、“AI 界的波将金村”或者是“AI 版的《绿野仙踪》”。换句话说,这根本就是扯淡。”
深度学习大神一发话,这场闹剧才最终消停。从这件事不难窥探出,即使是在行业界,对于机器学习,以及深度学习能力的认知还是有限,所以才让浑水摸鱼,或者别有用心者有机可乘。
此次科大讯飞疑似将人类同传翻译成果混淆为机器同传的事件,被诟病也是因为和索菲亚类似的“扯淡”。但无论是索菲亚的事先准备,还是科大讯飞的疑似“偷梁换柱”,反映出的,是自然语言理解(NLU)的发展并没有外界想象的那么聪明,甚至还停留在“傻”的阶段。
无论是微软小冰、小娜,苹果的Siri,亚马逊Alexa,谷歌Google Assistant,三星的Bixby,宣传再怎么炫酷,实际都是理解力不及三岁儿童。
究竟是自然语言理解太深,还是这些企业都失真了呢?
最早将人工智能用于自然语言理解是在人工智能的1.0时代,这一时期,图灵机的出现证明了数字信号足以描述任何形式的计算。进入20世纪60年代,在推理和搜索的基础上,通过自然语言与人类进行交流成为语音识别和自然语言处理的最初设想。

1966年约瑟夫发明的Eliza是世界上第一个会聊天的机器人
在这个设想下,第一个可以与人聊天的机器人Eliza的运行逻辑非常简单,主要是通过抓取与对话者的聊天关键词,然后根据系统设定好的词语重新组织语言。如果对话者说“我今天很开心”,它会反问“你为什么开心”。而当它的关键词库中没有对话者说的词语和句式,就会用一些客套的话来掩盖自己搜索和推理的缺失,比如“这很有趣,请继续。”
因此,在自然语言发展的最初阶段,基于关键词搜索和推理的模式离人们所希望的大量知识存储环境下运用语言逻辑进行理解、表达还相距甚远。
这种情况延续到“积木世界”的出现。
后来,一款叫SHRDLU的语言处理系统由斯坦福大学维诺格拉德开发,借鉴逻辑思维,通过这种系统改造的机器人可以根据人类指令辨别出形状简单的积木,且可以执行简单的命令。比如,它可以识别出三角形、长方形,圆形,并可以根据人的指令将它们进行移动。
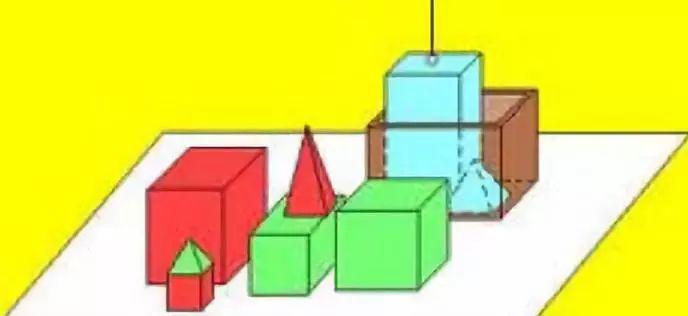
SHRDLU系统示意图(来源:冯志伟文化博客)
然而,SHRDLU的弊病也很明显,和Eliza的有限信息容纳一样,如果将SHRDLU拓展到更加丰富和复杂多变的现实环境中时,如何在超大信息量中找到它的“积木世界”,SHRDLU明显能力欠缺。
事实上,无论是Eliza还是SHRDLU,探索自然语言处理的科学家们一直想要解决的问题主要是两个:1、语言词库是否足够大?2、逻辑如何设置?
进入到人工智能2.0时代,解决这两个问题的曙光出现了。
“专家系统”以包含大量专家水平的知识和经验著称,它可以根据某一领域已有的知识和经验进行推理和判断,最终做出模拟人类专家的决策。因为这个构想可以在医学、金融等专业领域替代人类劳动,所以备受推崇。
但构想是好的,如何将知识,尤其是构建于纷繁复杂语言逻辑之上的准确知识传输给人工智能,却是一项非常复杂的工程,被称为“知识表达”。
在如何进行“知识表达”的过程中,研究哲学问题的“本体论”被应用于知识输入,即从事物的本源出发,通过分级处理,可以向计算机更准确的描述所需要的信息。
方法找到了,但现实却是摆在科学家面前的认知鸿沟更深不可测了。对于人类这样能够自由转换语境,轻松理解语义的超高智能生物来说,对本体的研究都相当困难。而要将这个人类都难以理解的思维复制到人工智能上,难度无法想象。
20世纪90年代,互联网数据革命带来的数据激增大幅解决了人工智能所需的知识积累问题,随着信息量的积累,即使机器仍然对语义无法理解,但翻译的准确度还是有极大提升。
仍待解决的,就是自然语言中的歧义问题。我们经常用外国人参加中文考试的例子来说明中国语言的博大精深:
小王和小李正在谈论小张,小王说:“说曹操,曹操就到。”——问,是谁到了?
看过《三国演义》我们知道曹操是个历史人物,这句话也是出自典籍,语义是指当在谈论某人的时候某人正好就来了,这里的某人并非指“曹操”,而是在特定语境下正在谈论的人。外国人不熟悉典籍,就不知道这个俚语是什么意思,可能无法说明曹操究竟指代的是谁。但自然语言理解只能顺着逻辑推理出是曹操到了,而无法理解小王和小李谈论的背后逻辑。
类似于这样的理解偏差数不胜数。
机器转文字只需要将所述语言准确转录,目前这个准确率各家自然语言处理公司都可以达到比较高的程度,但机器同传基本上没有哪家可以真正做到。
未来,对自然语言理解如何能够通过图灵测试,业界的主流方向还是寄托在机器学习,以及在机器学习基础上的纵向深度学习。

(根据中经社数据库整理)
业界专家认为,未来自然语言理解所面临的巨大困境在于两个方面。其一,是如何有效地将符号、逻辑意义表示与词/句向量分布表示相结合;其二,全面考虑语言各个层级间(语音、句法、词汇、语义和语用等)的相互作用,消除歧义,也是一个重要的挑战。
回到科大讯飞,想必以后类似的事件还将不断爆出,人们对AI寄予的超高期许,和为了迎合期许从而提升自我宣传的商家,两股力量会或多或少的将技术本质掩盖,而如果不是个别敏感的同传人士爆料,技术究竟发展到什么程度更多只是行业知晓,而不被外界所知。
后记
这次事件也从侧面反映出了AI与人类之间的伦理问题,在AI的大趋势下,如何划分AI与人类的劳动成果、知识产权,厂商在知识产权划分中应该承担怎样的责任,人类如何保护自身的知识产权,都应该提上日程了。
长按二维码关注,以后我们就是朋友了!
我是广告:
好文请投:tougao@gsi24.com
往 期 精 选
2018
— 完 —
以上是关于科普是自然语言太深,还是科大讯飞失真?的主要内容,如果未能解决你的问题,请参考以下文章