最新论文解读 | 基于预训练自然语言生成的文本摘要方法
Posted 微软研究院AI头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新论文解读 | 基于预训练自然语言生成的文本摘要方法相关的知识,希望对你有一定的参考价值。

文本摘要是一种从给定文本中生成精炼信息的任务,近年来很多生成式摘要方法在基于神经网络的序列到序列模型上进行了改进。但是这些方法有一些不足:首先在解码器端,这些方法大都是从左向右的解码,因此在解码每个单词的时候只能看到上文,而无法看到下文;其次由于上下文不完整,这些方法无法在解码器端很好的利用预训练的上下文语言模型的能力。
同时,预训练的上下文语言模型(如 BERT)在很多自然语言处理任务上取得了很好的效果。本文工作希望探讨如何更好的利用此类预训练语言模型提高文本生成方法的效果。
在本文中,我们基于编码器-解码器框架提出了一种新颖的基于预训练的方法,该方法可以由给定输入序列以两阶段的方式生成输出序列。
对于编码器,我们使用 BERT 将输入序列编码为上下文语义表示。对于解码器,在我们的模型中有两个阶段,在第一阶段,我们使用基于 Transformer 的解码器来生成输出序列的草稿;在第二阶段,我们分别 mask 草稿中的每个单词并将其提供给 BERT,然后基于 BERT 生成的输入序列和草稿的上下文语义表示,由一个基于 Transformer 的解码器来预测精化每个被 mask 位置的单词。
据我们所了解,我们的方法首次将 BERT 应用于文本生成任务。作为在这方面的首次尝试,我们在文本摘要任务上验证我们方法的效果。试验结果表明,我们的模型在 CNN/Daily Mail 和 New York Times 数据集上的性能超过了当前最好的方法。
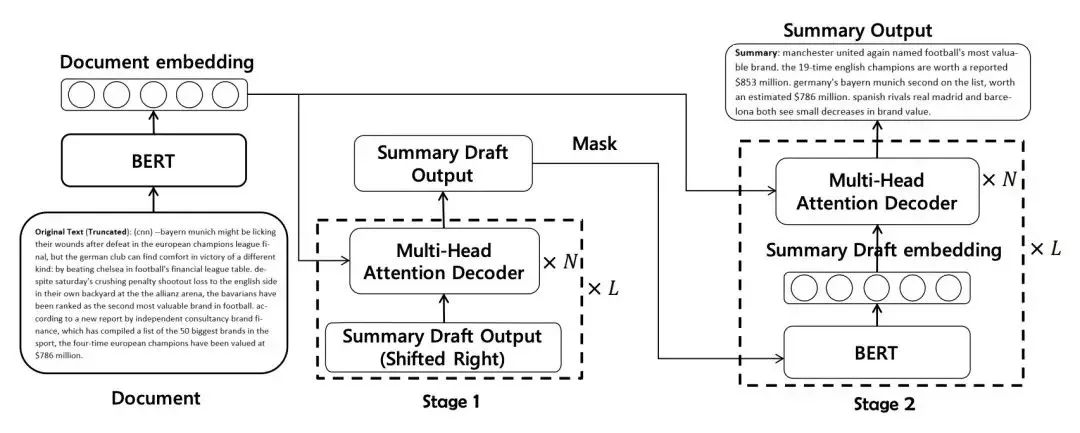
上图是作者提出的方法的结构图,它包含了一个编码器和两个解码器。方法包含以下部分:草稿生成过程以及精炼过程。
草稿生成过程中,编码器由预训练的 BERT 从输入文档中提取上下文表示,而后利用一个带有 Copy 机制的 N 层 Transformer 解码器,以从左向右的方式解码生成草稿。Copy 利用最后一层解码器的输出和编码器的输出计算注意力权重 α 和 Copy 概率,并和生成概率进行加权求和得到最终预测的概率:
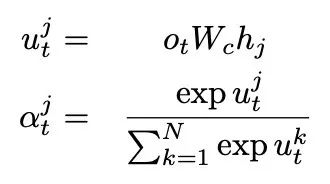
这一阶段解码器端并没有使用 BERT 产生上下文表示。该过程的损失函数定义为:
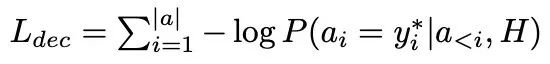
摘要精炼过程的主要目的是利用 BERT 的上下文表示提高解码器的学习能力,因此该过程使用和草稿生成阶段相同的文档编码。在解码器端,我们提出了一个单次级别的精炼解码器,该解码器接受草稿作为输入,输出精炼后的摘要。
如模型图中所示,首先依次将摘要草稿中的每个单词掩盖住,而后将掩盖后的序列输入 BERT 并得到序列的上下文表示。而后这个上下文表示被输入 N 层 Transformer 的解码器并与源文档表示进行交互预测摘要的每个单词。
尽管该解码器也是自左向右的解码顺序,但是在每个时刻解码器都能够获得完整的上下文。从 BERT 的角度来看,输入的是完整序列而不仅仅是上文,输入的分布与 BERT 的预训练过程更加一致,这能够尽可能地让 BERT 输入更好的上下文语义表示,从而帮助解码器生成更佳的摘要。
直观上看,在我们第二次解码时,每个时刻解码器能够利用到的信息更多,降低了学习的难度。
在实验中,基于实验结果我们共享了两个解码器的参数,精炼过程的损失函数定义如下。
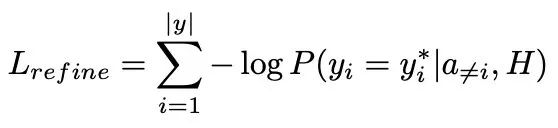
最后,由于最大化极大似然估计的目标对摘要等文本生成任务来说太过严格,可能会过度拟合,因此借鉴之前工作,我们将 ROUGE-L 作为另一个优化目标并利用强化学习对该目标进行优化,最终的学习目标是 MLE 和 ROUGE-L 的混合。
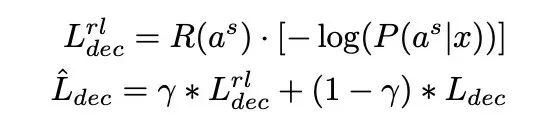
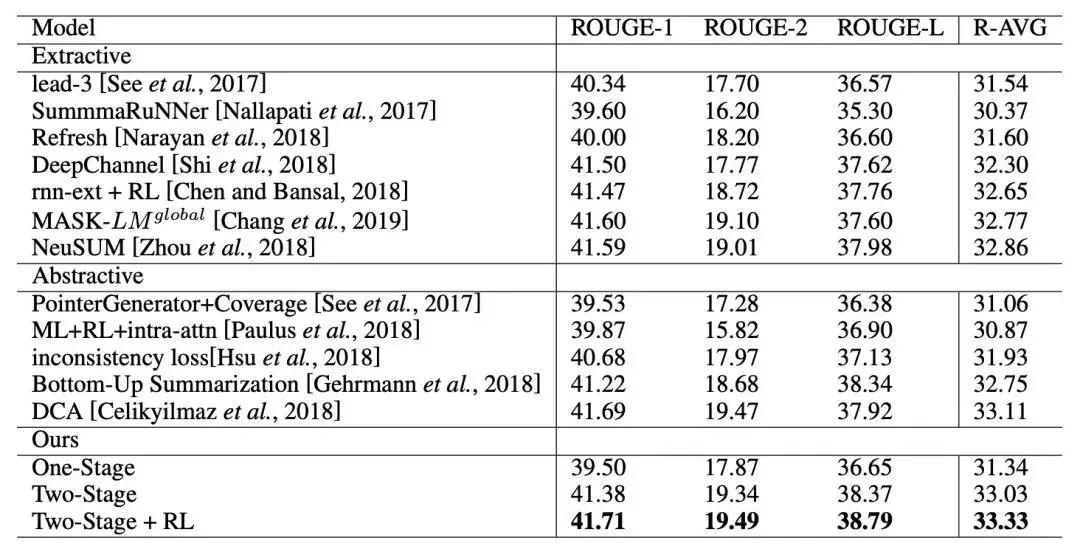
为了验证模型的效果,作者在 CNN/DailyMail 和 NYT-50 两个摘要数据集上进行了实验,并与当前一些主要方法进行了对比。其中 NYT-50 数据集是 NYT 数据集中删选所有摘要长度大于 50 的样本得到。在 CNN/DailyMail 数据集上作者进行了消融实验,以此来验证每个模块的作用。

同时,为了验证摘要长度对模型性能的影响,作者对不同长度样本下模型性能相对于抽取式和生成式基准模型的平均提高进行了计算并分析。
同生成式模型相比,相比于长度更短的样本,在摘要长度为 40-80 区间内的样本中作者提出的模型达到了更高的性能提升;而同抽取式基准模型相比,在长度超过 80 的样本上,性能提升不大,这可能是由于实验设置截断的原因,也可能是因为这个区间训练样本太少,因此抽取式模型性能不会落后太多。
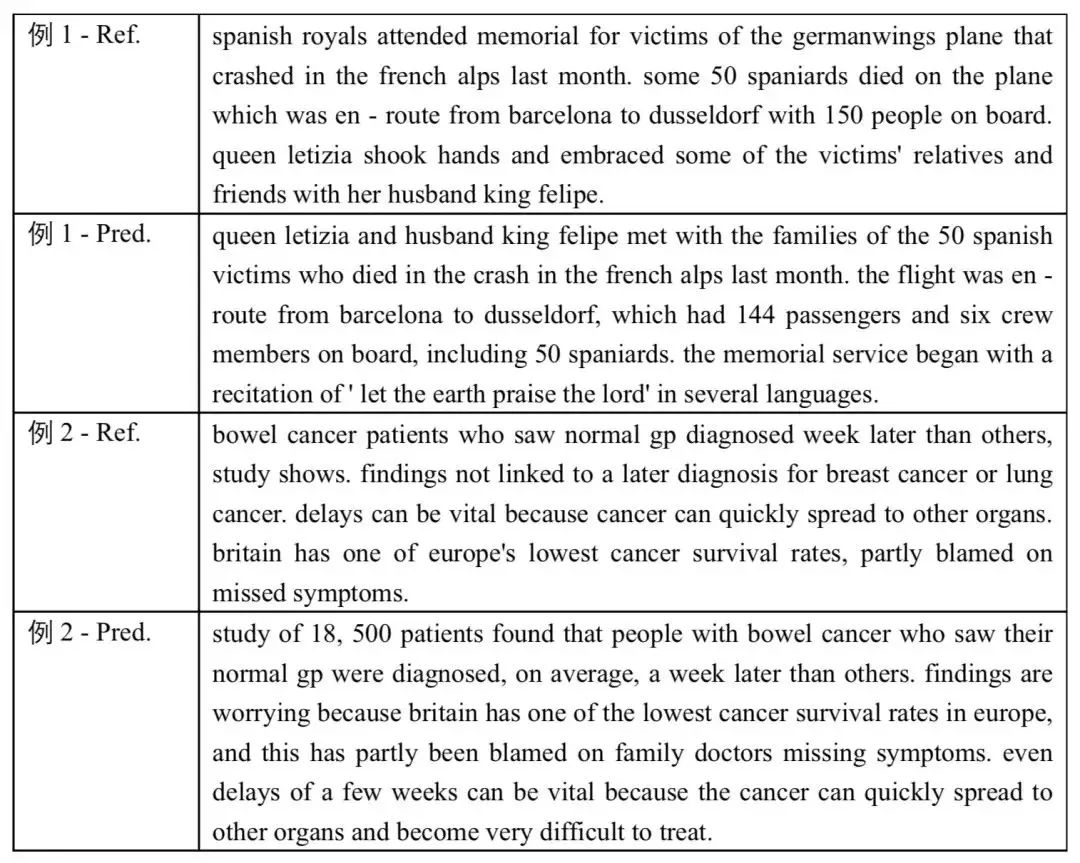
下面是两个模型预测(Pred.)和正确摘要(Ref.)的例子。
本文主要的创新点在于设计了一个两阶段解码器的模型,从而更好地在解码器端利用预训练语言模型的能力辅助文本生成。与目前 SOTA 的方法相比,在两个摘要数据集上都有一定的性能提升。
查看论文详情,请点击阅读原文。
你也许还想看:
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。
以上是关于最新论文解读 | 基于预训练自然语言生成的文本摘要方法的主要内容,如果未能解决你的问题,请参考以下文章
论文解读丨LayoutLM: 面向文档理解的文本与版面预训练