COTA:通过自然语言处理和机器学习改进Uber客户服务
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了COTA:通过自然语言处理和机器学习改进Uber客户服务相关的知识,希望对你有一定的参考价值。
我们研发了 COTA,我们的客户关注工单助手(Customer Obsession Ticket Assistant)。它是一个使用了机器学习和自然语言处理(NLP)技术的工具,可以帮助客服人员提供更好的客户支持。 在我们的客户支持平台之上,通过利用我们的 Michelangelo 机器学习即服务(Machine Learning-as-a-Service)平台,COTA 可以快速高效地解决 90%以上我们收到的客户支持工单。
在本文中,我们将讨论我们研发 COTA 背后的动机,概述其后端架构,并展示这个强大的工具是如何提高客户满意度的。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
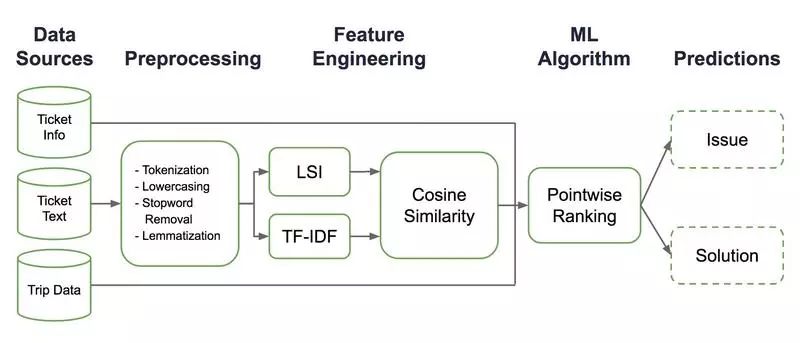
当客户向 Uber 寻求帮助时,我们必须及时引导他们找到最好的解决方案。一种方法是,让用户在报告问题时,点击一系列关于问题分类的层级结构,来确定他们问题的类型;这为我们的客服人员提供了更多关于问题的上下文,从而使他们能够更快地解决问题,如下面的图 1 所示:
图 1:Uber 客户的应用内客服流程为用户提供了一个直观且易于使用的界面。 该界面突出显示行程的细节,并列出各种可能的问题类型来引导他们。
尽管这提供了重要的上下文,但并不是解决问题所需的所有信息都可以通过这个过程获得,特别是当我们拥有如此多种多样的解决方案时。此外,客户可能会通过多种不同的方式描述与工单相关的问题,从而进一步复杂化了工单解决流程。随着 Uber 规模的不断扩大,客服人员必须能够处理不断增长的支持工单数量和工单的多样性,从技术错误到费用调整等各个方面都需要考虑。事实上,当一个客服人员打开一个工单时,他们首先要做的就是从数千个可能性中确定问题类型,这不是一件容易的事情!减少客服人员花费在识别工单问题类型上的时间非常重要,因为它能减少了解决用户问题所需的时间。
一旦选择了问题类型,下一步就是确定正确的解决方案,每种类型的工单都有不同的协议和解决方案。尽管有成千上万个可能的解决方案可供选择,为每个问题确定适当的解决方案仍然是一个耗时的过程。
我们设计了 COTA 来帮助我们的客服人员提高速度和准确性,从而改善客户体验。
简而言之,COTA 利用 Michelangelo 服务来简化,加速和标准化工单解决流程。尽管当前版本的 COTA 是由一系列向解决英语工单的客服人员推荐解决方案的模型组成的,我们也正在建立可以处理西班牙语和葡萄牙语工单的模型。
基于我们的支持平台,我们由 Michelangelo 服务驱动的模型会推荐三种最可能的问题类型和基于工单内容和行程场景的解决方案,如下所示:
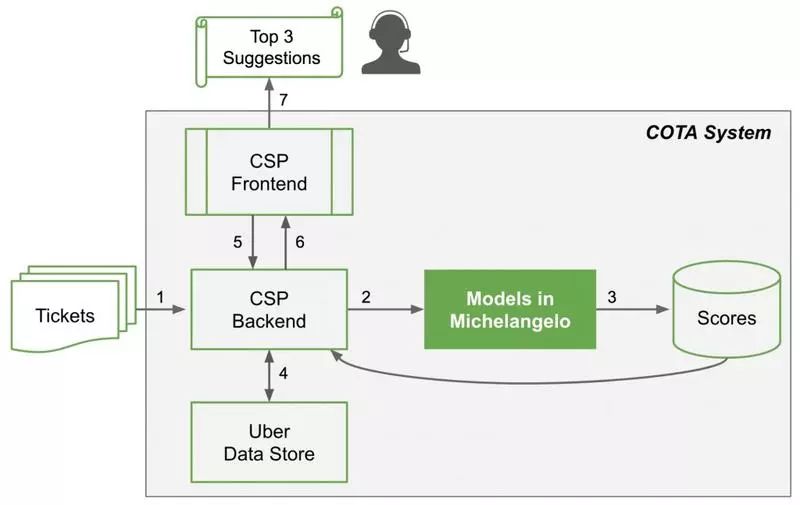
图 2:COTA 系统架构由七步工作流程组成。
一旦新的工单进入客户支持平台(CSP),后端服务收集工单的所有相关特征。
然后,后端服务将这些特征发送到 Michelangelo 服务的机器学习模型。
该模型给每个可能的解决方案预测一个分数。
后端服务接收预测结果和分数,并将其保存到我们的 Schemaless 数据存储中。
一旦客服人员打开一个工单,前端服务将触发后端服务,以检查工单是否有更新。如果没有更新,后端服务将检索出已保存的预测结果;如果有更新,它将获取更新的特征并再次执行步骤 2-4。
后端服务将按预测分数排序的一系列解决方案返回给前端。排名前三的解决方案会被建议给客服人员;从那些解决方案中,客服人员选择一个方案并解决工单。
使用了 COTA 之后的结果是很可靠的;客户服务调查的结果表明:COTA 可以将工单解决时间缩短 10%以上,同时能达到相近或更高级别的客户服务满意度。 通过让客服人员能提供更快更准确的解决方案,COTA 强大的机器学习模型使 Uber 客户支持体验更加愉快。
从系统外来看,COTA 会收集有关支持问题的上下文信息,并返回可能的解决方案,但背后还有很多事情要做。在其核心系统中,COTA 后端负责完成两项任务:确定工单类型并确定最合理的解决方案。为了实现这一点,我们的机器学习模型利用了从客户支持消息中提取的特征,行程信息和在工单提交的层次结构中客户选择的工单类型。
根据我们模型生成的特征重要性分数(并且不出所料地),识别问题类型时最有价值的特征是在通过层次结构正式提交他们的工单之前,客户向客服人员发送的关于他们问题的消息。由于用户发送的消息对于理解他们正在处理的问题很有用,我们建立了一个 NLP 管道,将多种不同语言的文本转换为对下游的机器学习模型有用特征。
我们可以建立 NLP 模型来翻译和解释不同的文本元素,包括音韵,词法,语法,句法和语义。基于这些构建单元,NLP 还可以进行字符级,单词级,短语级或句子 / 文档级的语言建模。传统的 NLP 模型是通过利用人类语言学专业知识来手工地设计特征。随着最近深度学习模式端到端训练的兴起,研究人员甚至开始开发能够解释整个文本块的模型。这种方式不必显式地解析一个句子中不同单词之间的关系,而是直接使用原始文本。
对于我们的使用场景,我们决定首先构建一个 NLP 模型,在单词级别上分析文本,以更好地理解文本数据的语义。一种流行的 NLP 方法是话题建模,其目的是使用词汇的计数统计结果来理解句子的含义。虽然话题建模没有考虑到字词顺序,但是对于诸如信息检索和文档分类之类的任务,该方法已经被证明能起到非常好的效果。
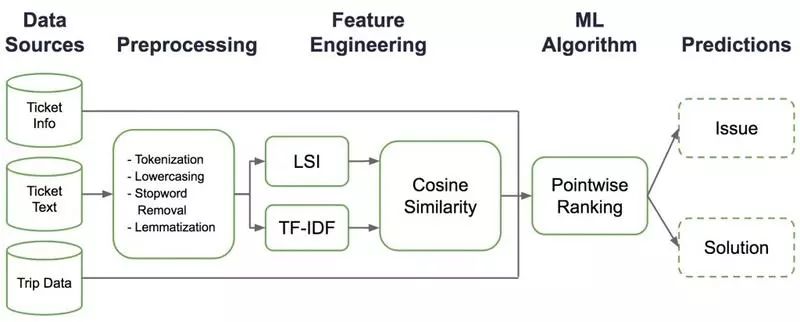
图 3:我们为工单类型识别和解决方案选择建立的 NLP 流水线由三个不同的步骤组成:预处理,特征工程和通过逐点排序算法的计算。
在 COTA 中,我们使用以下基于话题建模的 NLP 管道处理文本消息,如图 3 所示:
我们首先通过删除 html 标签来清理文本。接下来,我们对消息中的句子进行分词,并删除停用词。然后,我们进行词形化,将不同词形的单词转换成相同的基本形式。最后,我们将文档转换成一个单词集合(一个所谓的单词袋),并建立这些单词的字典。
为了理解我们的用户意图,我们在预处理之后对单词袋进行话题建模。具体来说,我们使用 TF-IDF(词频 - 逆文档频率)和 LSA(潜在语义分析)来提取话题。下面的图 4a 显示了一些我们可能从话题建模中获得的话题类型:
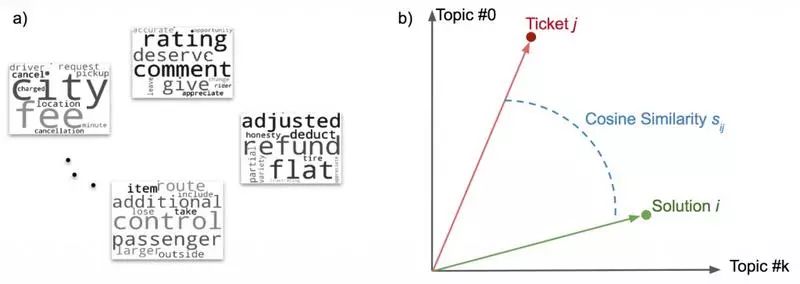
图 4:a)话题建模:我们使用 TF-IDF 和 LSA 从客户支持平台处理的客户支持工单中的富文本数据中提取话题。b)特征工程:将所有的解决方案和工单映射到话题向量空间,计算每一对解决方案和工单之间的余弦相似度。
话题建模使我们能够直接使用话题向量作为特征来执行下游的分类,用于问题类型识别和解决方案选择。然而,这种直接的方法受到话题向量的稀疏性的影响;为了给这些话题构建一个有意义的表示,我们通常需要保持话题向量拥有数百甚至数千个维度,同时很多维度的值接近于零。由于具有非常高维度的特征空间和大量的数据需要处理,训练这些模型变得非常具有挑战性。
考虑到这些因素,我们决定以间接方式使用话题建模:通过计算余弦相似度特征来执行进一步的特征工程,如图 4b 所示。以解决方案选择为例,我们收集每个解决方案的历史工单,并形成这样的解决方案的“单词袋“表示。
在这个场景下,话题模型变换是在“单词袋“表示上进行的,这个变换让我们知道每一个解决方案 i 的特征向量 Ti。我们对所有解决方案都进行这种转变。我们可以将任何新收到的工单 j 映射到解决方案 T1,T2...Tm 的话题向量空间,其中 m 是可用的可能解决方案的总数。这个过程最终得出与工单 j 对应的特征向量 tj。Ti 和 tj 之间的余弦相似度得分 sij 则表示解决方案 i 和工单 j 之间的相似性,这将特征空间从数百或数千个维度减少到一只手就能数的过来。
我们再次以解决方案选择作为例子,阐释我们的 ML 算法是如何起作用的。为了设计这个算法,我们将余弦相似度特征与其他可以用来匹配工单和解决方案的工单特征与行程特征组合到一起。凭借可用于数百种工单类型的超过 1000 种可能的解决方案,COTA 的大型解决方案空间向我们用于区分这些解决方案之间的细微差异的算法提出了挑战。
为了向客服人员给出所有可能性中最好的解决方案建议,我们使用了排名学习(learning-to-rank)的方法,并构建了基于检索的逐点排序算法。具体来说,我们将解决方案和工单对之间的正确匹配标记为正(1),并且随机抽取一部分与工单不匹配的解决方案,并将这些对标记为负(0)。使用余弦相似度以及工单和行程特征,我们可以建立一个二元分类算法,利用随机森林技术来分类每个“解决方案 - 工单”组合是否匹配。一旦算法对每一个可能的匹配进行评分,我们可以对评分进行排名,并把三个排名最高的解决方案作为建议。
下面的图 5 对使用话题向量特征的传统多类分类算法与使用修改过的余弦相似性特征的逐点排序算法的性能进行了比较:
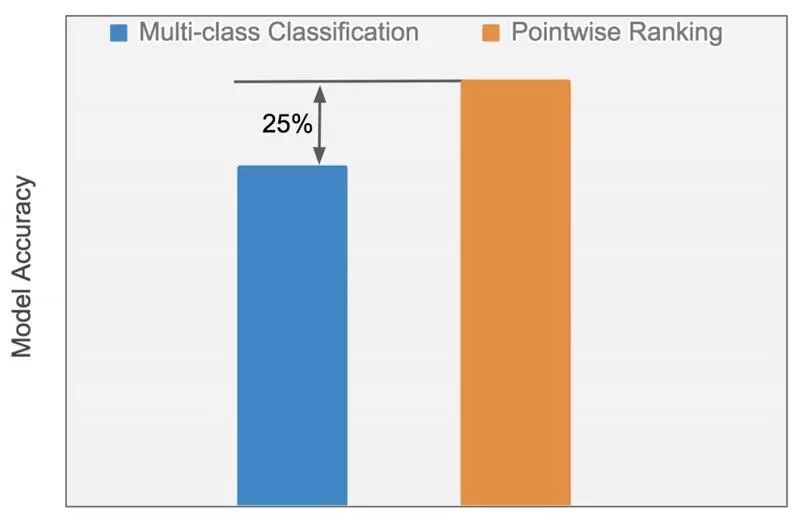
图 5:在解决方案选择任务上,逐点排序算法的精确度比多类分类算法精确度要高 25%。
基于余弦相似度的逐点排序算法优于使用未处理话题向量的多类分类算法,精确度相对提高了 25%。这个比较是在相同的数据集上使用相同类型的具有相同超参数的算法(随机森林)进行的,凸显了在排序框架中使用修改过的余弦相似特征的好处。如图 5 所示,使用逐点排序算法不仅使训练过程加快了 70%,而且显著提高了模型性能。
只有转化到现实世界中,COTA 给出的可靠的结果才有意义。为了衡量 COTA 对我们客服体验产生了多大影响,我们在英语工单上在线进行了多项受控的 A / B 测试实验。在这些实验中,我们涵盖了数以千计的客服人员,随机分配到对照组或实验组。对照组中的客服人员使用之前的工作流程,而实验组中的客服人员则使用一个经过修改的工作流程,他们可以看到一个包含关于问题类型和解决方案建议的用户界面。我们收集这些由对照组或实验组的客服人员解决的工单,并测量了一些关键指标,包括模型准确性、平均处理时间和客户满意度得分。
测试步骤进行如下:
我们首先测量了两组在线模型的表现,并将其与离线表现进行了比较。我们发现模型性能在离线和在线的情况下都是一致的。
然后,我们测量了客户满意度分数,并在对照组和实验组之间进行比较。总的来说,我们发现客户满意度往往能提高了几个百分点。这一发现表明 COTA 的确能提供与之前相同或更好的客户服务质量。
最后,为了确定 COTA 多大程度影响了工单解决的速度,我们比较了对照组和实验组之间的平均工单处理时间。我们确定,平均而言,这个新功能将工单处理时间缩短了大约 10%。通过提高客服人员的工作表现和加快工单解决速度,COTA 帮助我们的客户关注团队更好地服务于我们的用户,从而提高客户满意度。而且,COTA 加快工单解决的能力每年可以为 Uber 节省数千万美元。
COTA 的成功说服了我们继续使用机器学习技术栈进行试验,以提高系统的准确性,并为客服人员和终端用户提供更好的体验。
最近在文本分类,文本总结,机器翻译,和许多辅助性的 NLP 任务(语法和语义分析,识别文字蕴涵,命名实体识别与连接)等领域上的发展进步都是通过深度学习的方法来获得的。所以,我们开始使用深度学习进行尝试似乎是一个非常自然的选择。
在 Uber AI 实验室的研究人员的支持下,我们尝试将深度学习应用于下一代的问题类型识别和解决方案建议系统。我们基于卷积神经网络(CNN),递归神经网络(RNN)以及这两者的几种不同组合,实现了多种架构,包括分层结构和基于注意力的架构。
使用深度学习框架,我们能够以多任务学习的方式来训练我们的模型,让一个模型既能够识别问题类型,又能提出最佳解决方案。由于问题类型被组织到一个层次结构中,我们明确了我们可以使用束搜索的循环解码器来训练模型进行预测层次结构中的选择路径。这种解码器类似于序列模型的解码组件,并且能够进行更精确的预测。
为了确定最佳的深度学习架构,我们对所有类型的架构进行了大规模超参数优化,并在 GPU 集群上并行地对这些模型进行了训练。最后的结果表明,最精确的架构既适用于 CNN 也适用于 RNN。但为了我们的研究目的,我们决定寻求一种更简单的 CNN 体系结构,该架构准确度稍低,但在训练和计算方面具有更好的计算性能和更短的推断时间。最后,我们最终确定的模型提供了比原始随机森林模型高 10%的精度。
在下面的图 6 中,我们展示了一部分工单的数据覆盖率(模型正在处理的工单的百分比,x 轴)和准确度(y 轴)之间的关系。如下图 6 所示,随着数据覆盖率的降低,两种模型都变得更加精确,但是我们的深度学习模型在相同的覆盖率和较高的覆盖率下表现出更高的准确性。
图 6:我们的深度学习模型和经典模型(随机森林)识别问题类型的能力之间的比较结果,揭示了深度学习模型实现了更大的数据覆盖率和准确性。
与 Uber Michelangelo 团队合作,我们正处于这些深度学习模型产品化的最后阶段。
郑怀修和 Yi-Chia Wang 是 Uber 应用机器学习团队的数据科学家,Piero Molino 是 Uber AI Labs 的研究科学家。COTA 是客户支持平台,Applied Machine Learning,Michelangelo 和 Uber AI Labs 之间的跨职能协作。李红卫,安迪·哈里斯,莫尼斯·艾哈迈德·汗,Alexandru Grigoras,Viresh Gehlawat,Basab Maulik,Chinmay Maheshwari 和 Ron Tal 也为这个项目做出了重要贡献。
查看英文原文:
https://eng.uber.com/cota/
以上是关于COTA:通过自然语言处理和机器学习改进Uber客户服务的主要内容,如果未能解决你的问题,请参考以下文章