第63讲 Python自然语言处理(NLP)—word2vec
Posted 小叮当说SAS数据处理与统计分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第63讲 Python自然语言处理(NLP)—word2vec相关的知识,希望对你有一定的参考价值。
Python除了在机器学习和深度学习方面很强大,在自然语言处理(NLP)方面也非常强大,比如分析人物对话,下面我们来看看一个自然语言处理的实际例子。
这里以分析《人民的名义》txt格式小说中人物为例。
第一段程序加入下面的一系列人名是为了结巴分词能更准确的把人名分出来。
第二段程序的作用是将整个小说人民的名义(in_the_name_of_people.txt)中语句进行中文分词,即是把句子按照中文语法规则进行切片成一个一个的常见词语。存在文件in_the_name_of_people_segment.txt中。
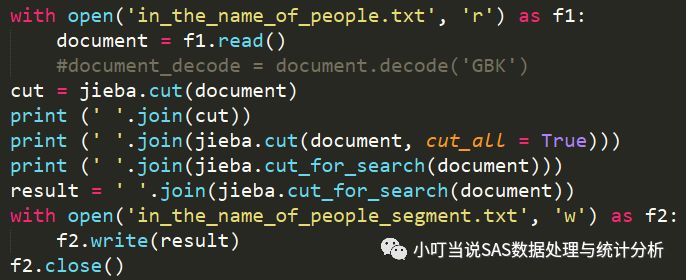
下面是文件in_the_name_of_people_segment.txt中分词的局部结果。

第三段程序是使用word2vec提供的LineSentence类来读文件,然后套用word2vec模型。

自然语言处理模型建立完后,就是我们想要的应用:

高育良 0.967257142067 李达康 0.959131598473 田国富 0.953414440155 易学习 0.943500876427 祁同伟 0.942932963371

0.961137455325 0.935589365706
输出不同类的为"刘庆祝"
好了,今天相关Python自然语言处理的一个实际例子就讲到这里啦,是不是很有意思,可以从人物对话中分析人物性格,人物相似度以及人物分类等等。因此,可以联想到其他场景的应用,只要给出人物或物质(比如蛋白、基因序列等)文本性质的资料,就可以对某些人物或物质进行分类。
以上是关于第63讲 Python自然语言处理(NLP)—word2vec的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福Introduction to NLP:第十讲关系抽取