斯坦福Introduction to NLP:第十讲关系抽取
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福Introduction to NLP:第十讲关系抽取相关的知识,希望对你有一定的参考价值。
最近需要调研NLP中的关系抽取任务
找了一篇RE的综述,关于早期研究的介绍较为笼统,因此找到斯坦福的自然语言处理入门课程学习。
课程是2012年的,比较早,正好学习一下早期的RE模型。
看视频的过程中参考了这篇博客:斯坦福大学-自然语言处理入门 笔记 第十课 关系抽取(relation extraction)
相关资源:
1. 简介
关系抽取一般是指抽取关系三元组(Resource Description Framework (RDF) triples)而不是抽取复杂关系。

为什么进行关系抽取?
- 创建新的关系型知识库(knowledge bases)
- 增强目前的知识库(knowledge bases)
- 支持问题回答(question answering)
下面是一个QA的例子
The granddaughter of which actor starred in the movie “E.T.”?
(acted-in ?x “E.T.”)(is-a ?y actor)(granddaughter-of ?x ?y)
要回答“哪个演员的孙女参演了E.T?”这个问题,需要提取以下三个三元组:
- (acted-in ?x “E.T.”) // 谁参演了“E.T.”?
- (is-a ?y actor) // 谁是一个演员?
- (granddaughter-of ?x ?y) // 谁是谁的孙女?
下面是关系抽取任务中一些常见的关系:
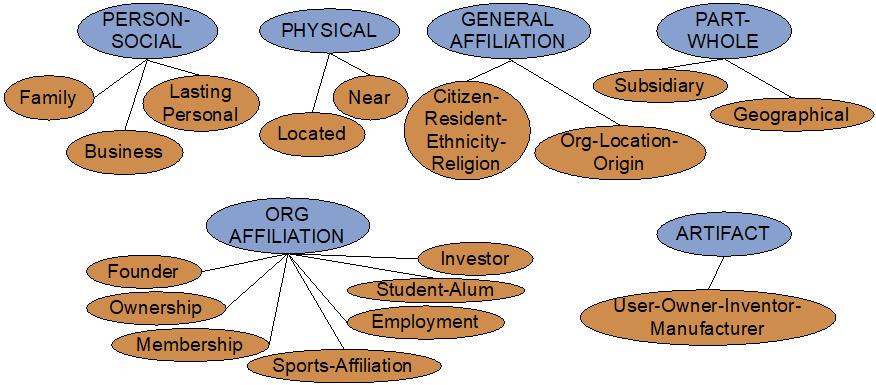
那么如何进行关系抽取呢?
在使用神经网络之前,主要有
- 人工定义模式(Hand-written patterns)
- 监督机器学习(Supervised machine learning)
- 半监督机器学习(Semi-supervised and unsupervised)
- Bootstrapping (using seeds)
- 远程监督(Distant supervision)
- Unsupervised learning from the web
2. 利用模式(pattern)进行关系抽取
2.1 抽取IS-A relations的规则
举个例子,"A, such as B"中"such as"这个短语就表名了A与B之间存在这个类与实例的包含关系。

(Hearst, 1992): Automatic Acquisition of Hyponyms

2.2 利用规则抽取更丰富的关系
主要思想:特定关系会发生在特定实体之间,如:
- ocated-in (ORGANIZATION, LOCATION)
- founded (PERSON, ORGANIZATION)
- cures (DRUG, DISEASE)
所以使用命名实体标签(named entity tag)来帮助我们进行关系抽取。
2个特定实体间的关系是可列举的
比如“药物”实体与“疾病”实体之间的关系可能是“治愈”,“预防”,“导致”等等

但人和组织这两个实体之间的关系,就不太可能是“治愈”。
比如说谁在什么组织担任什么职务?手动列举出所有可能的句式

2.3 总结
- 优点+
- 人工模式的准确度更高(high precsion)
- 可以根据特定领域进行修改
- 缺点-
- 人工模式的召回率(recall)很低
- 需要考虑所有可能的模式,工作量很大
- 不可能对所有的关系都使用这种方法
3. 使用监督学习的方法
3.1 训练流程
- 选择一组要提取的关系
- 选择一组相关的命名实体
- 查找和标记数据
- 选择一个有代表性的语料库
- 标注语料库中的命名实体
- 手工标注这些实体之间的关系
- 进入training、development和test阶段
- 在训练集中训练分类器
- 找到一句话中所有的命名实体
- 判断两个实体是否相关
- 如果是的话,就对关系进行分类
为什么训练了两个分类器?
- 因为第一步分类(判断实体是否相关)会排除大部分的无效对,可以加速分类的训练
- 可以为每个任务使用合适的特征集
3.2 构建用于关系抽取的词特征
以下面这句话为例,来提取特征。

- M1和M2的中心词,以及两者的结合
- M1和M2的词袋(bag of words)以及二元组(bigram)
- M1和M2左边和右边的单词
- M1和M2中间的单词的词袋或二元组

- 命名实体的类型
- 两个命名实体之间关联
- M1和M2的实体层级(entity level),一共三类(NAME,NOMINAL:比如the company,PRONOUN:比如it或he)

还有一些句法上的特征 - 两个实体之间的单词的基本语法块(syntactic chunk词性序列)
- 两个实体之间的树的成分路径(constituent path)
- 依赖路径(dependency path)
| 缩写 | 含义 |
|---|---|
| NP | noun phrase |
| PP | prepositional phrase |
| VP | verb phrase |

- 关于家庭的触发清单(trigger list)
- gazetter:有用的地理词列表
最终提取出了如下特征:

3.3 有监督方法的分类器与评估
可以使用任何分类器:
最大熵、朴素贝叶斯、SVM
在训练集(training set)上训练,在发展集(dev set)上调试,在测试集(test set)上测试
通过计算precision,recall以及F1评估分类结果

3.4 总结
- 优点+
- 如果有足够的手工标注的数据,并且测试集和训练集相似的话,可以得到很高的正确率
- 缺点-
- 获取标注大量的训练集花费昂贵
- 有监督模型对其他的类型的泛化能力不足
4. 使用半监督和非监督关系抽取
4.1 Relation Bootstrapping (Hearst 1992)
收集一组具有关系R的种子对(seed pair)
迭代:
- 找到有这些单词对的句子
- 查看对之间或周围的上下文,并将上下文概括为模式
- 使用模式获取更多单词对
下面是一个实例

下面是另一篇文章中的实例
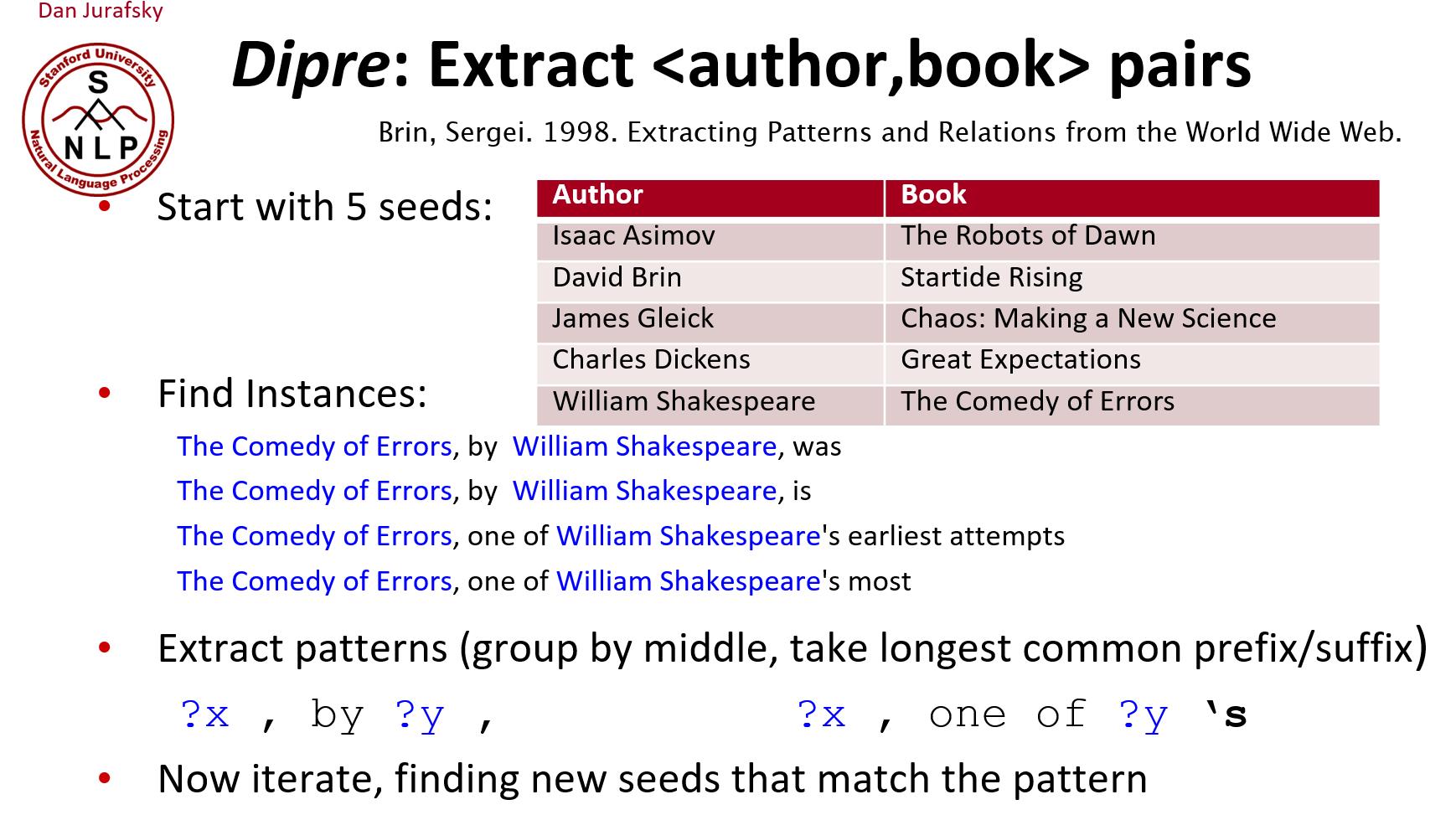
Bootstrapping 算法的输入少量实体关系数据作为种子,找到更多有某种关系的相关数据。
存在的问题是利用少量的种子数据在大规模数据中搜寻出来的结果,是否是我们真正想要的,会不会存在歧义的数据,这是 Bootstraping 算法的语义漂移问题。
4.2 Snowball
参考文献:E. Agichtein and L. Gravano 2000. Snowball: Extracting Relations from Large Plain-Text Collections. ICDL

使用类似的迭代算法
也和上面一样利用一组例子(instance)抽取特征
构建具有相似前缀、中间、后缀和的提取模式
- X和Y都必须是命名实体
- 并且为每个模式计算置信度。

4.3 远程监督(Distant Supervision)
参考文献:
[1] Snow, Jurafsky, Ng. 2005. Learning syntactic patterns for automatic hypernym discovery. NIPS 17
[2] Fei Wu and Daniel S. Weld. 2007. Autonomously Semantifying Wikipeida. CIKM 2007
[3] Mintz, Bills, Snow, Jurafsky. 2009. Distant supervision for relation extraction without labeled data. ACL09
远程监督的思想:
如果两个实体在已知知识库中存在,并且两者有相对应的某种关系(Freebase中罗列的关系之一),那么当这两个实体在其他非结构化文本中存在的时候也能够表达这种关系。认为同时包含这两个实体的所有句子也在表达这种关系,可以将这些句子作为这种关系的训练正例。
基于这种强有力的假设,远程监督算法可以利用已有的知识库,给外部非结构化文本中的句子标注某种关系标签,相当于自动语料标注,能够获取大量的标注数据供模型训练。
远程监督的两种范式
- 像监督分类:
- 使用具有许多特征的分类器
- 由详细的人工知识指导
- 不需要迭代扩展模式
- 像无监督分类:
- 使用大量未标记的数据
- 对训练语料库中的体裁问题不敏感
有监督的做法

- 对每个关系(relation)中的每一对元组,在语料库中找到同时包含这两个实体的句子
- 抽取高频的特征(语法分析、单词等)
- 用几千个模式来训练有监督分类模型
4.4 无监督关系抽取
参考文献
M. Banko, M. Cararella, S. Soderland, M. Broadhead, and O. Etzioni. 2007. Open information extraction from the web. IJCAI

开放信息抽取:
在没有训练数据和关系列表的情况下,从网页中抽取关系
- 利用语法数据(parsed data)训练一个“值得信任的元组”的分类器
- 抽取所有名词短语之间的关系,并且如果分类器认为值得信任的话,就将之保留
- 基于这种关系出现的频率来对该关系排序
(这一块儿完全没看懂)
4.5 半监督和无监督RE模型的评估
因为抽取的都是来自互联网语料的新关系,因此我们无法计算准确率(不知道哪些是正确的,即不知道真正例有多少)和召回率(不知道那些是错过的,即不知道假反例有多少)
我们只能大致计算一个准确率。计算的方法是,从结果中随机抽取一些关系,人工来判断这些关系是否是正确的。
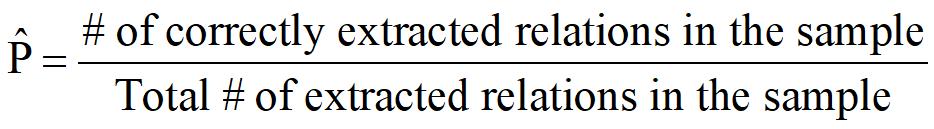
我们也可以基于不同水平的recall来计算precision(Can also compute precision at different levels of recall.)
- 前1000个新关系,前10000个新关系,前100000个新关系的precision
- 每一种都进行随机取样
但是没有办法进召回率评估
以上是关于斯坦福Introduction to NLP:第十讲关系抽取的主要内容,如果未能解决你的问题,请参考以下文章