条件随机场介绍—— An Introduction to Conditional Random Fields
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了条件随机场介绍—— An Introduction to Conditional Random Fields相关的知识,希望对你有一定的参考价值。
2. 模型
本部分从建模的角度讨论条件随机场,解释条件随机场如何将结构化输出上的概率分布表示为高维输入向量的函数。条件随机场即可以理解为逻辑回归在任意图结构上的扩展,也可以理解为结构化数据的生成模型(如隐马尔可夫模型)的判别化。
本部分首先对图模型做一个简单的介绍(2.1节),并对NLP中的生成模型和判别模型进行分析(2.2节)。然后给出条件随机场的正式定义,包括常用的线性链条件随机场(2.3节)和任意图结构(general graphical structures)的条件随机场(2.4节)。由于条件随机场的精度高度依赖它所使用的特征集,我们还将介绍最常使用的特征工程技巧(2.5节)。最后,给出了两个条件随机场应用的例子(2.6节),并对条件随机场在各领域的使用做简要综述(2.7节)。
2.1 图模型
图模型是多元概率分布的表达和推断强有力的工具。其有效性已经在很多随机建模领域得到证明,包括编码理论[89]、计算机视觉[41]、知识表达[103]、贝叶斯统计[40],以及自然语言处理[11, 63]等。
直接表示多变量的分布很困难。例如,如果要存储\\(n\\)个二值变量,需要\\(O(2^n)\\)数量级的浮点数。图模型的思想是将多变量的分布表示为多个局部函数(local functions)的乘积,每个局部函数仅依赖一个较小的变量集合。这种因子分解的方式与变量间的条件独立关系紧密相关——因子分解和条件独立这两种类型的信息都可以很容易的用图表示。实际上,正是因子分解、条件独立以及图结构之间的这种关系构成了基于图的建模框架的强大功能:条件独立的视角在设计模型的时候非常有用,因子分解的视角在设计推断算法的时候非常有用。
本节的其余部分,我们从因子分解和条件独立两个角度介绍图模型,重点关注基于无向图的模型。关于图模型及近似推断请参考Koller 和Friedman的书[57](《概率图模型:原理与技术》)。
2.1.1 无向模型
考虑随机变量集合\\(Y\\)上的概率分布。记\\(s\\in 1,2,\\cdots,|Y|\\)为变量的下标。每个变量\\(Y_s\\in Y\\)的值来自集合\\(\\mathcal{Y}\\),它可以是连续或是离散的,本文主要考虑离散的情况。向量\\(\\mathbf{y}\\)表示\\(Y\\)的任意取值。记\\(\\mathbf{1}_{\\{y=y‘\\}}\\)为\\(y\\)的指示函数,当\\(y=y‘\\)时值为\\(1\\),否则为\\(0\\)。此外,我们还需要用于将概率分布边缘化的符号。对于一个固定的变量值\\(y_s\\),我们用\\(\\sum_{\\mathbf{y} \\backslash y_s}\\)表示对\\(\\mathbf{y}\\)中所有值等于\\(y_s\\)的变量\\(Y_s\\)求和【求边缘分布】。
本文中的符号表示:一般情况下大写为随机变量或随机向量(粗体),小写为随机变量或向量(粗体)的取值,花体为取值空间。
假设概率分布\\(p\\)可以表示为因子的乘积,每个因子的形式为\\(\\Psi_a(\\mathbf{y}_a)\\),其中\\(a\\)是取值为\\(1\\)到\\(A\\)的下标,\\(A\\)为因子的数量。因子\\(\\Psi_a(\\mathbf{y}_a)\\)为非负标量,可以被认为是\\(\\mathbf{y}_a\\)中各个取值之间的相容性的度量。数值之间具有较高的相容度就表示它们具有较高的概率。因子分解使我们能更有效的表示概率分布\\(p\\),因为集合\\(Y_a\\)要远小于完全变量集合\\(Y\\)。
无向图模型是一族概率分布,其中每个因子分解对应一组因子集合。严格地,给定\\(Y\\)的一组子集\\(\\{Y_a\\}_{a=1}^A\\),无向图模型是能写为如下形式的所有的概率分布的集合
\\[
p(\\mathbf{y})=\\frac{1}{Z}\\prod_{a=1}^A\\Psi_a(\\mathbf{y}_a),
\\tag{2.1}
\\]
其中,对任意选择的因子$\\mathcal{F}={\\Psi_a} \\(,都有\\)\\Psi_a(\\mathbf{y}_a)\\ge 0 (\\text{for all }\\mathbf{y}_a)$。因子也可称为局部函数(local functions)或相容性函数(Compatibility functions)。通常把无向模型定义的概率分布称为随机场。
常量\\(Z\\)是归一化因子,用以保证概率分布\\(p\\)的和为\\(1\\),定义为
\\[
Z=\\sum_\\mathbf{y}\\prod_{a=1}^A\\Psi_a(\\mathbf{y}_a).
\\tag{2.2}
\\]
\\(Z\\)可以被看作因子集合\\(\\mathcal{F}\\)的函数,被称为配分函数(partition function)。注意式(2.2)中,在\\(\\mathbf{y}\\)上的求和运算量是指数级的,因此\\(Z\\)的计算通常比较困难,但是可以通过近似方法来求得(第4节)。
术语“图模型”的由来,是因子分解(式2.1)可以利用图(graph)简洁地表示。其实更自然的表示形式是因子图(factor graphs)[58]。因子图是一种两分图(bipartite graph)\\(G=(V,F,E)\\),其中节点集合\\(V=\\{1,2,\\cdots,|Y|\\}\\)表示模型中的随机变量,节点集合\\(F=\\{1,2,\\cdots,A\\}\\)表示模型中的因子。因子图的含义是如果变量节点\\(Y_s \\ \\ (s\\in V)\\)与因子节点\\(\\Psi_a \\ \\ (a \\in F)\\)相连,则\\(Y_s\\)是\\(\\Psi_a\\)的参数(argument)。因此,因子图直接地描述了概率分布\\(p\\)是如何被分解为局部函数之积的。
下面,我们对因子图是否能描述一个给定的概率分布给出严格定义。令\\(N(a)\\)为因子图中第\\(a\\)个因子的邻节点下标集合。于是:
定义2.1 对于概率分布\\(p(\\mathbf{y})\\),如果存在一组局部函数\\(\\Psi_a\\)使得\\(p\\)可以写为下式的形式,
\\[
p(\\mathbf{y})=Z^{-1}\\prod_{a \\in F}\\Psi_a(\\mathbf{y}_{N(a)})
\\tag{2.3}
\\]
则它可以分解为一个因子图\\(G\\)。
因子图与一组随机变量子集以同样的方式描述无向模型。式(2.1)将一组随机变量子集看作邻居关系(neighborhoods)\\(\\{Y_{N(a)}| \\forall a \\in F \\}\\)。定义2.1中的无向图模型,等价于根据\\(G\\)进行因子分解的所有概率分布的集合。
例如,图2.1为一个具有三个随机变量的因子图。图中,圆表示随机变量节点,方块表示因子节点,并根据相应的变量或因子进行了标记。该因子图描述了所有能写为\\(p(y_1,y_2,y_3)=\\Psi_1(y_1,y_2)\\Psi_2(y_2,y_3)\\Psi_3(y_1,y_3)\\)的\\(\\mathbf{y}=(y_1,y_2,y_3)\\)的概率分布的集合。
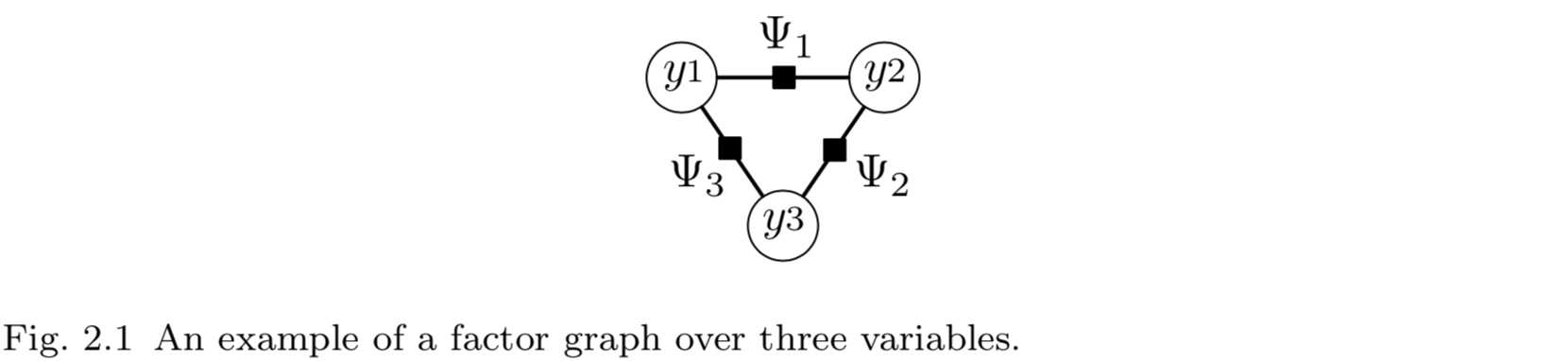
图模型的因子分解和变量之间的条件独立之间有紧密的关系。这种关系可以通过另一种无向图来理解,称为马尔可夫网络。马尔可夫网络中仅有随机变量节点,不包含因子节点。令\\(G\\)为一个无向网络,节点为随机变量(下标为\\(V=\\{1,2,\\cdots,|Y|\\}\\))。对于下标为\\(s \\in V\\)的随机变量,令\\(N(s)\\)表示它在\\(G\\)中的邻节点下标集合。如果\\(G\\)满足局部马尔可夫性,那么就可以说分布\\(p\\)是关于\\(G\\)马尔可夫的。局部马尔可夫性:任意两个变量\\(Y_s, Y_t \\in Y\\),变量\\(Y_s\\)在给定邻节点\\(Y_{N(s)}\\)的条件下独立于\\(Y_t\\)【注:\\(p(Y_s,Y_t|Y_{N(s)})=p(Y_s|Y_{N(s)})p(Y_t|Y_{N(s)})\\)】。直觉上,这意味着\\(Y_{N(s)}\\)本身包含了预测\\(Y_s\\)所需的全部有用信息。
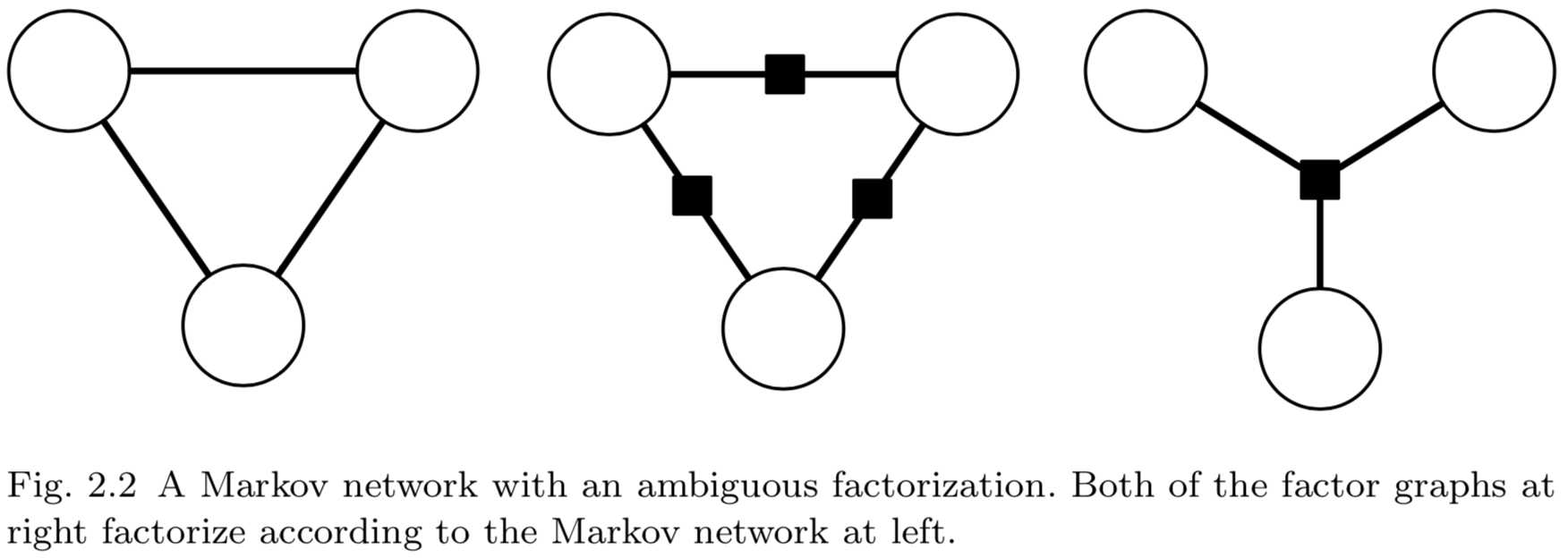
从因子分解的角度看,马尔可夫网络具有模糊性。考虑图2.2(左)所示的三个节点的马尔可夫网络。任意能够因子分解为\\(p(y_1,y_2,y_2)\\propto f(y_1,y_2,y_2)\\)(\\(f\\)为正函数)的概率分布都满足该马尔可夫网络。然而,我们可能希望使用一种更严格的参数化形式,即\\(p(y_1,y_2,y_2)\\propto f(y_1,y_2)g(y_2,y_3)h(y_1,y_3)\\)。第二种模型是第一种模型的严格子集,因此不需要那么多的数据来精确地估计概率分布。但是马尔可夫网络不能区分这两种参数化形式。相比之下,因子图更明确地描述了因子分解。
2.1.2 有向模型
无向模型中的局部函数不需要直接的概率解释(可以不是概率函数),有向图模型则描述一个分布如何被分解为局部条件概率分布。令\\(G\\)为有向无环图,其中\\(\\pi (s)\\)为\\(G\\)中节点\\(Y_s\\)的父节点下标集合。有向图模型是因子分解为如下形式的概率分布族:
\\[
p(\\mathbf{y})=\\prod_{s=1}^S p(y_s|\\mathbf{y}_{\\pi(s)}).
\\tag{2.4}
\\]
我们称概率分布\\(p(y_s|\\mathbf{y}_{\\pi(s)})\\)为局部条件分布。注意\\(\\pi{(s)}\\)可以为空集,即节点无父节点。这种情况下,\\(p(y_s|\\mathbf{y}_{\\pi(s)}) = p(y_s)\\)。
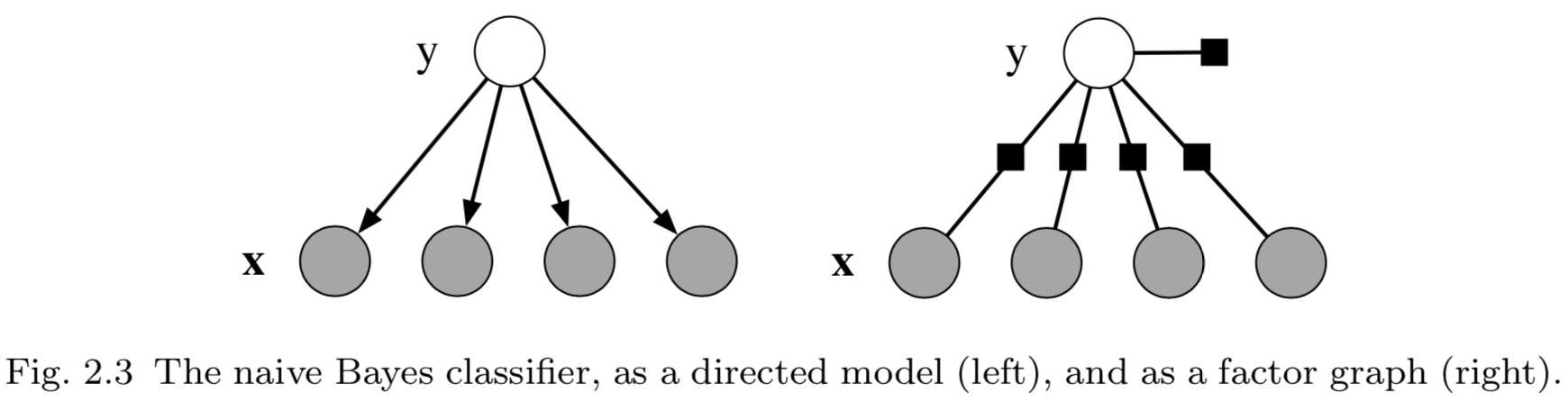
如引言部分所示,\\(p\\)需要被归一化。有向模型可以被认为是一种特殊的因子图,其中单个因子都通过特殊的方式被局部归一化,它满足(a)因子等于变量子集上的条件分布,(b)归一化常量\\(Z=1\\)。有向模型常用于表示生成式模型,如2.2.3节所示。有向模型的一个例子是贝叶斯模型(式2.7),如图2.3(左图)所示。图中,阴影节点表示在数据集中观测到的变量。在本文中会使用多次使用这种表示方式。
2.1.3 输入和输出
本文考虑待预测变量已知的情况。模型中的变量分为变量\\(X\\)的集合和输出变量集合\\(Y\\),假设\\(X\\)总是可观测的,需要预测的是输出变量\\(Y\\)。例如,\\(\\mathbf{x}\\)表示一个句子中的单词构成的向量,\\(\\mathbf{y}\\)为\\(\\mathbf x\\)中每个单词对应的词性标记所构成的向量。
我们感兴趣的是构建变量\\(X\\cup Y\\)的联合分布,基于前中文介绍的标记,\\(X\\)和\\(Y\\)上的无向图模型表示为
\\[
p(\\mathbf{x},\\mathbf{y})=\\frac{1}{Z}\\prod_{a=1}^A \\Psi_a (\\mathbf{x}_a, \\mathbf{y}_a),
\\tag{2.5}
\\]
其中,每个局部函数\\(\\Psi_a\\)依赖于两个变量子集\\(X_a \\subseteq X\\)和\\(Y_a \\subseteq Y\\)。归一化常量为
\\[
Z=\\sum_{\\mathbf{x},\\mathbf{y}} \\prod_{a \\in F} \\Psi_a(\\mathbf{x}_a, \\mathbf{y}_a),
\\tag{2.6}
\\]
其中涉及到对全部\\(\\mathbf{x}\\)和\\(\\mathbf{y}\\)求和。
此处,\\(\\mathbf{x}\\)和\\(\\mathbf{y}\\)无条件依赖关系,\\(X\\)和\\(Y\\)作为网络中的节点具有相同的地位
2.2 生成模型 VS 判别模型
本节我们讨论几种简单的用于自然语言处理的图模型。尽管这些模型已经广为人知,但介绍它们不仅能使上一节的定义更为清晰,而且能够引出条件随机场中的一些问题。我们会特别关注隐马尔可夫模型,原因在于它与线性链条件随机场紧密相关。
本节的主要目的是对比生成模型(Generative models)和判别模型(Discriminative models)。在接下来讨论的几个模型中,两个是生成模型(朴素贝叶斯和隐马尔可夫)一个是判别模型(逻辑回归)。生成模型是那些描述了标记向量\\(\\mathbf{y}\\)是如何按概率生成特征向量\\(\\mathbf{x}\\)的模型。判别模型则相反,它直接描述了如何为给定特征向量\\(\\mathbf{x}\\)分配一个标记\\(\\mathbf{y}\\)。理论上说,两种模型可以利用贝叶斯规则相互转换,但实际上两种方法是不同的,都有各自的优缺点(见2.2.3节)。
2.2.1 分类
首先我们来讨论分类(classification)问题,即给定特征向量\\(\\mathbf{x}=(x_1,x_2,\\cdots,x_K)\\),预测离散取值的类别标记\\(y\\)。解决该问题的一种简单的方法是,假设一旦类别标记能够确定,则所有特征是相互独立的。这就是是朴素贝叶斯分类器(naive Bayes classifier)。它基于一个联合概率模型,其形式为:
\\[
p(y,\\mathbf{x})=p(y)\\prod_{k=1}^K p(x_k | y).
\\tag{2.7}
\\]
该模型可以描述为图2.3(左)所示的有向模型。如果因子定义为\\(\\Psi(y)=p(y)\\),每个特征\\(x_k\\)的因子为\\(\\Psi_k(y,x_k)=p(x_k|y)\\) ,也可以用因子图表示将该模型,如图2.3(右)所示。
另一种可以自然地表示为图模型的分类器是逻辑回归(在自然语言处理领域作为最大熵模型而知名)。该分类器的思想是假设每个类别的对数概率\\(\\log p(y|\\mathbf{x})\\)为\\(\\mathbf{x}\\)的线性函数【本文中的log都是指自然对数】,再乘以一个规范化常数。这样,就得到条件分布:
\\[
p(y|\\mathbf{x})=\\frac{1}{Z}\\exp \\left\\{ \\theta_y + \\sum_{j=1}^K \\theta_{y,j}x_j\\right\\},
\\tag{2.8}
\\]
其中\\(Z(\\mathbf{x})=\\sum_y \\exp\\{\\theta_y + \\sum_{j=1}^k \\theta_{y,j}x_j\\}\\)为归一化常量。\\(\\theta_y\\)是偏差权重(bias weight),与朴素贝叶斯模型中的\\(\\log p(y)\\)类似【式2.7】。不同于为每个类使用一个权重向量(式2.8),我们还可以使用不同的标记,令所有类别使用同一个权重集合。这样表示的关键在于定义一个特征函数集合,每个特征函数的值仅在对应的类别中才不为0。于是,为特征权重定义函数\\(f_{y‘,j}(y,\\mathbf{x})=\\mathbf{1}_{\\{y‘=y\\}}x_j\\),为偏差权重定义函数\\(f_{y‘}(y,\\mathbf{x})=\\mathbf{1}_{\\{y‘=y\\}}\\)。现在,我们可以利用\\(f_k\\)来表示每个特征函数\\(f_{y‘,j}\\),利用\\(\\theta_k\\)表示相应的权重\\(\\theta_{y‘,j}\\)。利用这种标记技巧,逻辑回归模型变为:
\\[
p(y|\\mathbf{x})=\\frac{1}{Z(\\mathbf{x})}\\exp \\left\\{ \\sum_{k=1}^K \\theta_k f_k(y,\\mathbf{x})\\right\\}.
\\tag{2.9}
\\]
我们引入这种表示方法的原因,是它会应用在稍后介绍的CRFs中。
2.2.2 序列模型
分类器仅能预测单一的类别变量,而图模型能够为许多相互依赖的变量构建预测模型。本节中,我们讨论变量之间(可能是)最简单形式的依赖,模型的输出变量为一个序列。我们以自然语言处理中的命名实体识别(named-entity recognition, NER)问题为例,引出该模型。命名实体识别,是识别并分类文本中的专有名称,包括位置,例如China;人名,例如George Bush;组织,例如United Nations。命名实体识别的任务,是切分出给定句子中属于实体的词并对实体类型进行分类(人,组织,位置等等)。该问题的难点,是很多命名实体字符串的出现频率很低,即便是在大规模训练集中也是如此,因此必须利用上下文信息进行识别。
命名实体识别的方法之一,是独立地将每个词分类为PERSON、LOCATION、ORGANIZATION或OTHER(不是命名实体)。该方法的问题在于它假设给定输入,所有的命名实体标记是独立的。实际上,命名实体标记在相邻的词之间是相互依赖的;例如,尽管New York是个位置,但New York Times是一个组织。可以将输出变量排成一个线性链来放松该独立性假设。隐马尔可夫模型采用了这种方法[111]。隐马尔可夫模型假设观测序列\\(X=\\{x_t\\}_{t=1}^T\\)背后隐含着一个状态序列\\(Y=\\{y_t\\}_{t=1}^T\\)。令\\(S\\)为所有可能状态组成的有限集,\\(O\\)为所有可能观测值组成的有限集。对所有的\\(t\\)有\\(x_t \\in O, y_t \\in S\\)。在命名实体问题中,每个观测\\(x_t\\)是位于\\(t\\)位置的词,每个状态\\(y_t\\)是命名实体标记,即PERSON、LOCATION、ORGANIZATION或OTHER中的一种。
为了便于构建联合分布模型\\(p(\\mathbf{y},\\mathbf{x})\\),隐马尔可夫模型有两个独立性假设。第一,假设每个状态仅依赖于前驱状态(immediate predecessor),也就是说给定前驱状态\\(y_{t-1}\\),状态\\(y_t\\)与所有的\\(y_1,y_2,\\cdots, y_{t-2}\\)都不相关。第二,每个观测\\(x_t\\)仅依赖于当前状态\\(y_t\\)。基于这两个假设,可以利用三个概率分布来描述隐马尔可夫模型:初始状态分布\\(p(y_1)\\);转移概率\\(p(y_t|y_{t-1})\\);观测概率\\(p(x_t|y_t)\\)。状态序列\\(\\mathbf{y}\\)和观测序列\\(\\mathbf{x}\\)的联合概率可以因子分解为
\\[
p(\\mathbf{y},\\mathbf{x})=\\prod_{t=1}^T p(y_t|y_{t-1})p(x_t|y_t).
\\tag{2.10}
\\]
为了简化其见,领虚拟初始状态\\(y_0\\)作为每个状态序列的第一个状态。这样就可以将初始状态分布\\(p(y_1)\\)记为\\(p(y_1|y_0)\\)。
隐马尔可夫模型已经在自然语言处理中的许多序列标注任务得到应用,如词性标记、命名实体识别、信息抽取等。
2.2.3 比较
不管是生成模型还是判别模型,都是\\((\\mathbf{y}, \\mathbf{x})\\)上分布的描述,但是其思路不同。生成模型,如朴素贝叶斯分类器和隐马尔可夫模型,是因子分解为\\(p(\\mathbf{y},\\mathbf{x})=p(\\mathbf{y})p(\\mathbf{x}|\\mathbf{y})\\)的联合分布族。它描述了根据已知标记,如何生成特征样本。判别模型,如逻辑回归是条件分布族\\(p(\\mathbf{y}|\\mathbf{x})\\),直接针对分类规则进行建模。理论上来说,判别模型也可以通过乘以边缘分布\\(p(\\mathbf{x})\\)得到联合分布\\(p(\\mathbf{y},\\mathbf{x})\\),但几乎没有需要这样做的情况。
判别模型和生成模型概念上的主要不同之处在于条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)不包含模型\\(p(\\mathbf{x})\\),它对于分类来说不是必要的。\\(p(\\mathbf{x})\\)的构建通常比较困难,因为它包含了许多高度相互依赖的特征。例如,在命名实体识别中,原始的隐马尔可夫模型仅使用了一个特征,即词汇本身。但是很多词,特别是专有命词,不会出现在训练集中,因此词汇本身作为特征信息量不足。为了对未知词汇进行标记,我们还需要使用其他特征,如首字母大小写、相邻的词、前缀和后缀、是否出现在预先定义的人或位置的列表中,等等。
判别模型的优点在于它能够利用更丰富的、重叠的特征。为了更好的进行理解,考虑式(2.7)的朴素贝叶斯分布族。它是一个联合分布族,其条件分布都为“逻辑回归形式”(式2.9)。但是存在其他的联合模型,有的\\(\\mathbf{x}\\)之间有着复杂的依赖关系,其条件分布也为式(2.9)的形式。通过直接构建条件分布,我们可以不必理会\\(p(\\mathbf{x})\\)的形式。判别模型,如条件随机场,假设\\(\\mathbf{y}\\)之间是条件独立的,并假设了\\(\\mathbf{y}\\)是如何依赖\\(\\mathbf{x}\\)的,但是对于\\(\\mathbf{x}\\)之间的依赖关系并没有做任何假设。这也可以理解为图的形式。假设有一个因子图表示联合分布\\(p(\\mathbf{y},\\mathbf{x})\\)。如果我们为条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)构建图,那么任何仅依赖于\\(\\mathbf{x}\\)的因子都不会出现在图结构中。原因在于它们是条件独立的,关于\\(\\mathbf{y}\\)是常数。
为了在生成模型中包含相关的特征,我们有两种选择。第一,利用增强的模型来表示输入之间的相关性,即向每个\\(\\mathbf{x}_t\\)中添加有向边。但是这样做常常很难实现。例如,很难想像如何对词的大小写和词的后缀之间的依赖关系建模,我们也特别不希望这么做,因为我们可能以任何形式观察测试句子。
第二个选择是简化独立性假设,如朴素贝叶斯假设。例如,在朴素贝叶斯假设下隐马尔可夫模型的形式可能为\\(p(\\mathbf{x},\\mathbf{y})=\\prod_{t=1}^Tp(y_t|y_{t-1})\\prod_{k=1}^Kp(x_{tk}|y_t)\\)。这种思路在某些情况下很有效。但是也可能存在问题,因为独立性假设可能会影响性能。例如,尽管朴素贝叶斯分类器在文档分类中非常有效,但是在很多应中的表现都不如逻辑回归[19]。
进一步地,朴素贝叶斯也可能会得到较差的概率估计。例如,假设要为一个两分类问题训练朴素贝叶斯分类器,其中所有特征都是重复的。也就是说,给定初始特征向量\\(\\mathbf{x}=(x_1,x_2,\\cdots,x_K)\\),我们将其转化为\\(\\mathbf{x}‘=(x_1,x_1,x_2,x_2,\\cdots,x_K,x_K)\\),然后运行朴素贝叶斯算法。尽管没有向数据中添加任何新信息,该变化将会提高概率估计的信度,意思是朴素贝叶斯估计\\(p(y|\\mathbf{x}‘)\\)比起\\(p(y|\\mathbf{x})\\)要更远离0.5(更大或更小)。
类似朴素贝叶斯的假设在扩展至序列模型时的问题优其严重,因为推断过程需要合并模型各部分的证据。如果各标记的概率估计的信度都过高的话,那么就很难合理地将它们合并。
朴素贝叶斯和逻辑回归的不同之处仅在于前者是生成模型,而后者是判别模型。在离散输入下,这两个分类器在其他方面完全相同。朴素贝叶斯和逻辑回归的假设空间相同,从某种意义上来说,任何逻辑回归分类器都可以转化为一个具有相同决策边界的朴素贝叶斯分类器,反之亦然。另一种解释这种情况的说法是,如果我们将朴素贝叶斯模型(式2.7)与逻辑回归(式2.9)生成式地描述为下式(2.11),则它们定义了相同的概率分布族:
\\[
p(y,\\mathbf{x})=\\frac{\\exp\\{\\sum_k\\theta_k f_k(y,\\mathbf{x})\\}}{\\sum_{\\tilde{y},\\tilde{\\mathbf{x}}}\\exp\\{\\sum_k\\theta_kf_k(\\tilde{y}, \\tilde{\\mathbf{x}})\\}}.
\\tag{2.11}
\\]
这意味着如果对朴素贝叶斯模型(式2.7)通过条件似然最大化进行训练,我们就会得到与逻辑回归同样的分类器。反之,如果逻辑回归模型被生成式地表示,即像式(2.11)一样,通过联合似然\\(p(y,\\mathbf{x})\\)最大化进行训练,则我们可以得到与朴素贝叶斯相同的分类器。根据Ng和Jordan[98]的说法,朴素贝叶斯和逻辑回归构成了一对生成-判别对(generative-discriminative pair)。最新的关于生成模型和判别模型的研究参见Liang和Jordan[72]。
大体上来说,生成模型和判别模型如此不同的原因是不明确的,因为我们总是可以利用贝叶斯规则在两种方法之间进行转换。例如,在朴素贝叶斯模型中,很容易将联合概率\\(p(\\mathbf{y})p(\\mathbf{x}|\\mathbf{y})\\)转换为条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)。实际上,该条件具有与逻辑回归模型(式2.9)相同的形式。如果我们从数据中获得一个“真实”的生成模型,即生成样本数据的分布\\(p^*(\\mathbf{y},\\mathbf{x})=p^*(\\mathbf{y})p^*(\\mathbf{x}|\\mathbf{y})\\),然后我们可以简单的计算真正的\\(p^*(\\mathbf{y}|\\mathbf{x})\\),这正是判别模型。但是我们不可能得到真实的分布,于是造成实践中两种方法是不同的。先估计\\(p(\\mathbf{y})p(\\mathbf{x}|\\mathbf{y})\\)然后计算\\(p(\\mathbf{y}|\\mathbf{x})\\)(生成式方法),与直接求得\\(p(\\mathbf{y}|\\mathbf{x})\\)相比,得到的是模型的不同估计。换句话说,生成模型和判别模型的目的是一样的,都是估计\\(p(\\mathbf{y}|\\mathbf{x})\\),但采用了不同的实现途径。
文献Minka[93]给出了生成模型和判别模型区别的另一种观点。假设生成模型\\(p_g\\)的参数为\\(\\theta\\)。根据定义,其形式为:
\\[
p_g(\\mathbf{y},\\mathbf{x};\\theta)=p_g(\\mathbf{y};\\theta)p_g(\\mathbf{x}|\\mathbf{y};\\theta).
\\tag{2.12}
\\]
也可以利用概率的链式规则将\\(p_g\\)重写为:
\\[
p_g(\\mathbf{y},\\mathbf{x};\\theta)=p_g(\\mathbf{x};\\theta)p_g(\\mathbf{y}|\\mathbf{x};\\theta).
\\tag{2.13}
\\]
其中\\(p_g(\\mathbf{x};\\theta)\\)和\\(p_g(\\mathbf{y}|\\mathbf{x};\\theta)\\)通过推断进行计算,即\\(p_g(\\mathbf{x};\\theta)=\\sum_{\\mathbf{y}}p_g(\\mathbf{y},\\mathbf{x};\\theta)\\),\\(p_g(\\mathbf{y}|\\mathbf{x};\\theta)=p_g(\\mathbf{y},\\mathbf{x};\\theta)/p_g(\\mathbf{x};\\theta)\\) 【因为\\(p_g(\\mathbf{y},\\mathbf{x},\\theta)\\)已知】。
接下来,将该生成模型与相同联合分布族上的判别模型进行比较。为了进行比较,还需要定义输入数据的先验概率\\(p(\\mathbf{x})\\),使得\\(p(\\mathbf{x})\\)可以通过一些参数配置从\\(p_g\\)中得到。即\\(p(\\mathbf{x})=p_c(\\mathbf{x};\\theta‘)=\\sum_{\\mathbf{y}}p_g(\\mathbf{y},\\mathbf{x}|\\theta‘)\\),其中\\(\\theta‘\\)一般与式(2.13)中的\\(\\theta\\)不同。然后,将其与条件分布\\(p_c(\\mathbf{y}|\\mathbf{x};\\theta)\\)结合,\\(p_c(\\mathbf{y}|\\mathbf{x};\\theta)\\)也可以从\\(p_g\\)中得到,即\\(p_c(\\mathbf{y}|\\mathbf{x};\\theta)=p_g(\\mathbf{y},\\mathbf{x};\\theta)/p_g(\\mathbf{x};\\theta)\\)。于是可得到如下分布:
\\[
p_c(\\mathbf{y},\\mathbf{x})=p_c(\\mathbf{x};\\theta‘)p_c(\\mathbf{y}|\\mathbf{x};\\theta).
\\tag{2.14}
\\]
比较式(2.13)和式(2.14),可以看出条件的方法能更自由的拟合数据,因为它不要求\\(\\theta = \\theta‘\\)。直觉上,由于式(2.13)中的参数\\(\\theta\\)在输入分布和条件分布都使用了,因此参数集必须要同时较好的满足两个分布。潜在的代价是降低\\(p(\\mathbf{y}|\\mathbf{x})\\)的精度以提高\\(p(\\mathbf{x})\\)的精度。然而,前者是我们所关心的,后者是我们不关心的。不过,从另一方面说,自由度的增加也使得训练数据过拟合的风险增大了,从而降低了对未知数据的泛化能力。
尽管直到目前我们都在强调缺点,但是生成模型也的确有其优点。首先,生成模型在处理潜变量、部分标注数据和未标注数据的时候更加自然。在最极端情况下,当数据完全未标注时,生成模型可以使用无监督学习方法训练,而判别模型的无监督学习则不够自然,还是一个待解决的问题。
第二,生成模型在某些情况下比判别模型好,直觉上是因为输入模型\\(p(\\mathbf{x})\\)对条件模型有平滑作用。Ng和Jordan[98]声称这种情况在数据集较小的时候优其明显。不过,对于给定数据集要判断生成模型好还是判别模型好是不可能的。最后,在某些情况下生成模型更可取。例如,实际问题需要一个自然的生成模型,或者实际应用要求模型既能预测输入特征又能预测输出特征。
由于生成模型的形式为\\(p(\\mathbf{y},\\mathbf{x})=p(\\mathbf{y})p(\\mathbf{x}|\\mathbf{y})\\),因此可以自然地用有向图表示,其中输出\\(\\mathbf{y}\\)拓扑上是输入的前驱。类似地,判别模型使用无向图表示更加自然地。不过,情况也并非总是如此。例如,马尔可夫随机场(式2.32)是无向的生成模型,而MEMM(式6.2)是有向判别模型。利用有向图(其中\\(\\mathbf{x}\\)是\\(\\mathbf{y}\\)的前驱)描述判别模型也是有用的。
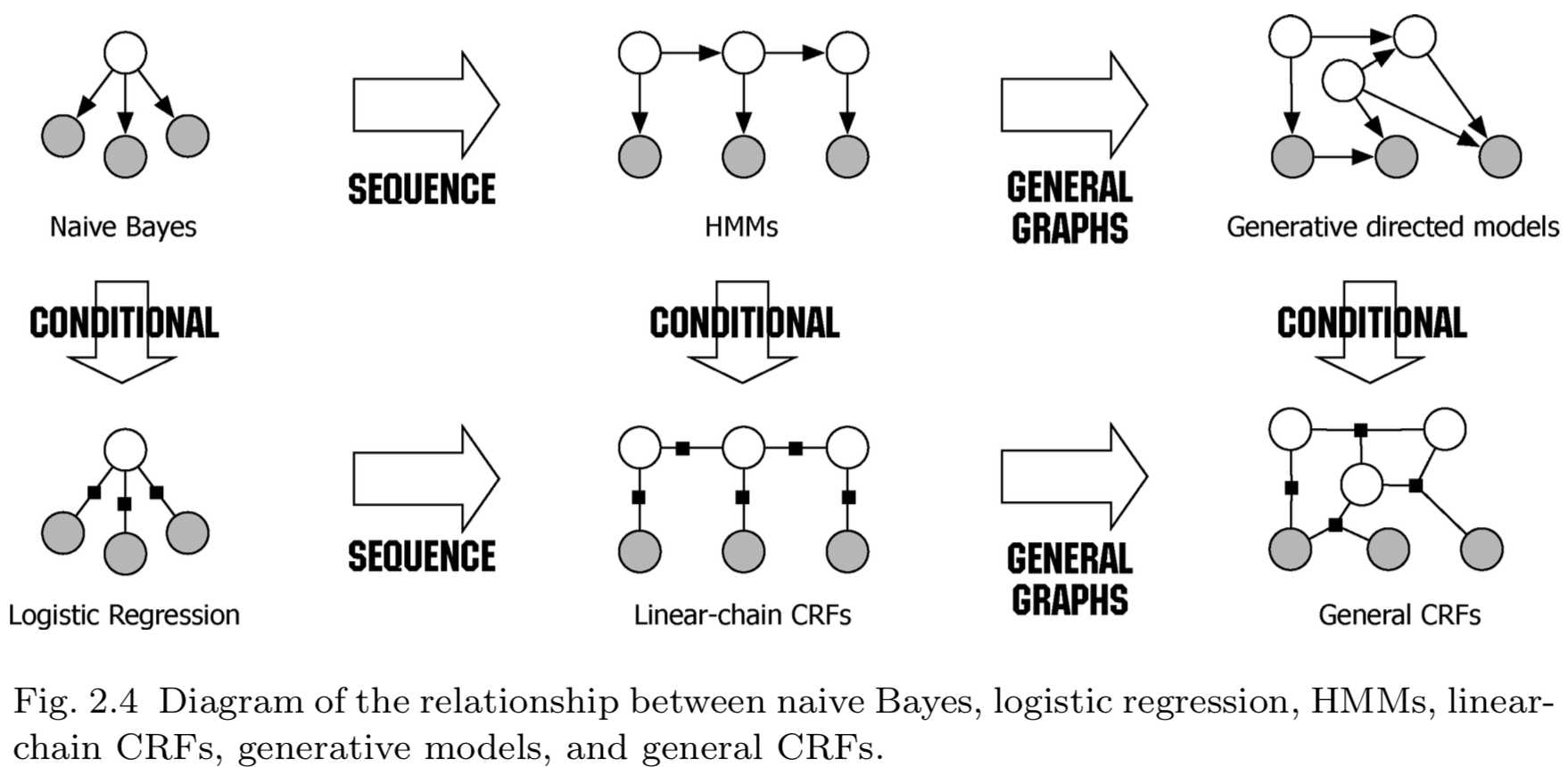
隐马尔可夫模型与线性链条件随机场的关系与朴素贝叶斯和逻辑回归的关系类似。正如朴素贝叶斯与逻辑回归是一个生成-判别对,隐马尔可夫也可以导出一个判别模型,该模型是条件随机场的特例,我们在下一节将会讨论这个问题。朴素贝叶斯、逻辑回归、生成模型、条件随机场的类比关系如图2.4所示。
2.3 线性链条件随机场
为了引出线性链条件随机场,我们首先考虑隐马尔可夫模型中的联合分布\\(p(\\mathbf{y},\\mathbf{x})\\)和对应的条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)。关键点在于,该条件分布实际上是一个具有特殊的特征函数的条件随机场。
首先,我们将式(2.10)所示的隐马尔可夫联合分布重写为一种更易于扩展的形式。即
\\[
p(\\mathbf{y},\\mathbf{x}) = \\frac{1}{Z} \\prod_{t=1}^T\\exp \\left\\{
\\sum_{i,j \\in S}\\theta_{ij}\\mathbf{1}_{\\{y_{t}=i\\}} \\mathbf{1}_{\\{y_{t-1}=j\\}}
+\\sum_{i \\in S} \\sum_{o \\in O} \\mu_{oi} \\mathbf{1}_{\\{y_t=i\\}} \\mathbf{1}_{\\{x_t = o\\}}
\\right\\},
\\tag{2.15}
\\]
其中,\\(\\theta = \\{\\theta_{ij}, \\mu_{oi}\\}\\)是分布的实值参数,\\(Z\\)是归一化常数。如果式(2.15)中没有\\(\\frac{1}{Z}\\)项则在某些\\(\\theta\\)的取值下得到的并不是一个概率函数,例如,将所有参数取值为1。
原文脚注:并非所有\\(\\theta\\)的取值都是有效的,因为\\(Z\\)的求和定义,即\\(Z=\\sum_\\mathbf{y}\\sum_{\\mathbf{x}} \\prod_{t=1}^T\\exp \\left\\{ \\sum_{i,j \\in S}\\theta_{ij}\\mathbf{1}_{\\{y_{t}=i\\}} \\mathbf{1}_{\\{y_{t-1}=j\\}} +\\sum_{i \\in S} \\sum_{o \\in O} \\mu_{oi} \\mathbf{1}_{\\{y_t=i\\}} \\mathbf{1}_{\\{x_t = o\\}}\\right\\}\\) ,可能并不会收敛。例如,一个具有一个参数的模型,\\(\\theta_{00}>0\\)。该问题其实对条件随机场来说并不是个问题,因为条件随机场中对\\(Z\\)中的求和常常是基于一个有限集。
现在,令人感兴趣的是式(2.15)描述了与式(2.10)所示的几乎完全相同类型的隐马尔可夫型。每一个同质隐马尔可夫模型都可以通过下面的参数设置写成式(2.15)的形式,
\\[
\\begin{align}
\\theta_{ij} & = \\log p(y‘ = i | y= j) \\\\mu_{oi} & = \\log p(x=o | y =i)\\Z &= 1
\\end{align}
\\]
反方向的转换也可以,即每个如式(2.15)所示的因子分解都是一个隐马尔可夫模型(但不是一定是同质隐马尔可夫模型,这是个恼人的技术问题)。这在第4.1节利用前-向后向算法构建相应的隐马尔可夫模型部分可以看出来。因此,尽管该参数化过程增加了灵活性,但我们并没有向隐马尔可夫模型的分布族中添加任何新的分布。
通过引入特征函数,我们可以将式(2.15)写得更简洁一些,就像在式(2.9)所示的逻辑回归中那样。每个特征函数的形式为\\(f_k(y_t,y_{t-1},x_t)\\)。为了再现式(2.15),每个状态转移\\((i,j)\\)都需要一个特征函数\\(f_{ij}(y,y‘,x)=\\mathbf{1}_{\\{y=i\\}}\\mathbf{1}_{\\{y‘=j\\}}\\),每个状态-观测对\\((i,o)\\)也需要一个特征函数\\(f_{io}(y,y‘,x)=\\mathbf{1}_{\\{y=i\\}}\\mathbf{1}_{\\{x=o\\}}\\)。令\\(f_k\\)为更通用的函数,来涵盖\\(f_{ij}\\)和\\(f_{io}\\)。于是,可以将隐马尔可夫模型写为:
\\[
p(\\mathbf{y},\\mathbf{x})=\\frac{1}{Z}\\prod_{t=1}^T\\exp \\left\\{ \\sum_{k=1}^K \\theta_k f_k (y_t,y_{t-1},x_t) \\right\\}.
\\tag{2.16}
\\]
再一次,式(2.16)定义了与式(2.15)完全一样的分布族,当然也与式(2.10)所定义的分布族一样。
最后一步,是给出式(2.16)所对应的条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)。即:
\\[
p(\\mathbf{y}|\\mathbf{x})=\\frac{p(\\mathbf{y},\\mathbf{x})}{\\sum_{\\mathbf{y}‘}p(\\mathbf{y}‘,\\mathbf{x})}
=\\frac{\\prod_{t=1}^T\\exp\\left\\{ \\sum_{k=1}^K \\theta_k f_k(y_t,y_{t-1},x_t) \\right\\}}{\\sum_{\\mathbf{y}‘} \\prod_{t=1}^T\\exp\\left\\{ \\sum_{k=1}^K \\theta_k f_k(y‘_t,y‘_{t-1},x_t) \\right\\}}
\\tag{2.17}
\\]
条件分布(2.17)是一种特殊的线性链条件随机场,它仅以当前词汇本身做为特征。但其他类型的条件随机场可以利用输入数据的更丰富的特征,如当前词汇的前缀后缀、前后相邻的词,等等。这种扩展仅要求对现有的式子做很小的改变。仅需将特征函数变为比指示函数更一般化的形式。这就引出了线性链条件随机场的一般定义:
定义 2.2 令\\(Y, X\\)为随机向量,\\(\\theta=\\{\\theta_k\\} \\in \\Re^K\\)为参数向量,\\(\\mathcal{F}=\\{f_k(y,y‘,\\mathbf{x}_t)\\}_{k=1}^K\\)是实值特征函数集合。线性链条件随机场是具有如下形式的分布\\(p(\\mathbf{y}|\\mathbf{x})\\)
\\[
p(\\mathbf{y}|\\mathbf{x}) = \\frac{1}{Z(\\mathbf{x})} \\prod_{t=1}^T \\exp \\left\\{ \\sum_{k=1}^K\\theta_kf_k(y_t,y_{t-1},\\mathbf{x}_t) \\right\\},
\\tag{2.18}
\\]
其中\\(Z(\\mathbf{x})\\)是一个依赖于输入的规范化函数
\\[
Z(\\mathbf{x}) = \\sum_{\\mathbf{y}} \\prod_{t=1}^T \\exp \\left\\{ \\sum_{k=1}^K\\theta_kf_k(y_t,y_{t-1},\\mathbf{x}_t) \\right\\}.
\\tag{2.19}
\\]
注意:式(2.18)中的\\(\\mathbf{x}_t\\)为个体(如输入序列中的第\\(t\\)个单词)相关的特征向量,而式(2.17)中相应的\\(x_t\\)表示具体的个体(第\\(t\\)个单词本身)。
从定义可看出,线性链条件随机场可以描述为\\(\\mathbf{x}\\)和\\(\\mathbf{y}\\)上的因子图,即
\\[
p(\\mathbf{y}|\\mathbf{x})=\\frac{1}{Z(\\mathbf{x})} \\prod_{t=1}^T \\Psi_t(y_t,y_{t-1}, \\mathbf{x}_t)
\\tag{2.20}
\\]
其中每个局部函数具有特殊的对数线性形式:
\\[
\\Psi_t(y_t,y_{t-1}, \\mathbf{x}_t)=\\exp \\left\\{
\\sum_{k=1}^K \\theta_kf_k(y_t,y_{t-1}, \\mathbf{x}_t)
\\right\\}.
\\tag{2.21}
\\]
这种形式在我们下节讨论任意结构条件随机场的时候会很有用。
通常,参数向量\\(\\theta\\)从数据中学习得到,参见第5部分。
根据前文的分析,我们知道如果联合分布\\(p(\\mathbf{y},\\mathbf{x})\\)的因子分解为隐马尔可夫模型,则相关的条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)为线性链条件随机场。这种像隐马尔可夫模型一样的条件随机场如图2.5所示。不过,其他类型的线性链条件随机场也非常有用。例如,在隐马尔可夫模型中,无论输入是什么,从状态\\(i\\)到状态\\(j\\)的转移会得到同样的概率评分,\\(\\log p(y_t=j|y_{t-1}=i)\\)。在条件随机场中,我们可以简单地通过添加一个特征\\(\\mathbf{1}_{\\{y_t=j\\}}\\mathbf{1}_{\\{y_{t-1}=1\\}}\\mathbf{1}_{\\{x_t=o\\}}\\),来允许状态转移\\((i,j)\\)的概率评分依赖于当前观测向量。具有这种转移特征的条件随机场如图2.6所示。这种条件随机场常用在文本处理应用中。
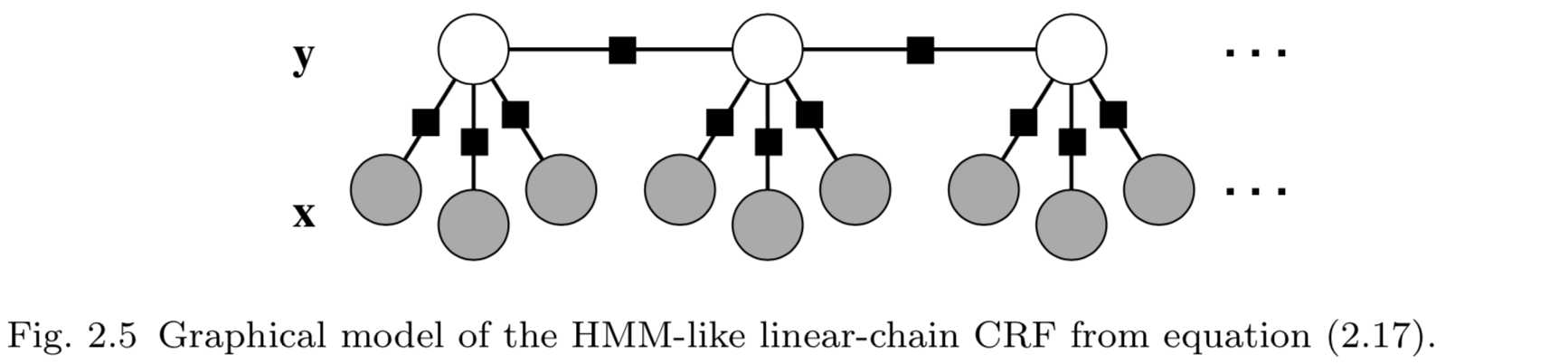
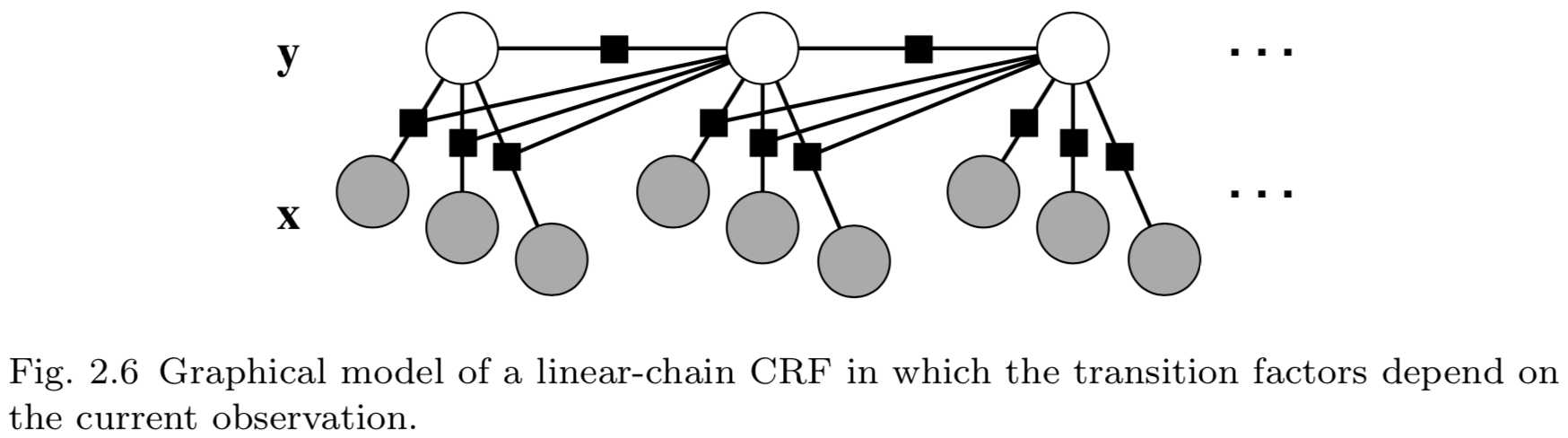
实际上,由于条件随机场不考虑变量\\(\\mathbf{x}_1,\\cdots,\\mathbf{x}_T\\)之间的依赖关系,我们可以允许因子\\(\\Psi_t\\)依赖于整个观测向量\\(\\mathbf{x}\\)而不破坏线性图结构——允许我们将\\(\\mathbf{x}\\)看作单一变量。结果,特征函数可以重写为\\(f_k(y_t,y_{t-1},\\mathbf{x})\\),能够将输入变量\\(\\mathbf{x}\\)作为整体进行度量。不仅限于线性链条件随机场,任意结构条件随机场也具有这种特点。具有这种结构的线性链条件随机场的图如图2.7所示。图中,我们并不再把\\(\\mathbf{x}_1,\\cdots,\\mathbf{x}_T\\)作为单个节点表示,而是将\\(\\mathbf{x}=(\\mathbf{x}_1,\\cdots,\\mathbf{x}_T)\\)作为单一的大观测节点,所有因子依赖于该节点。
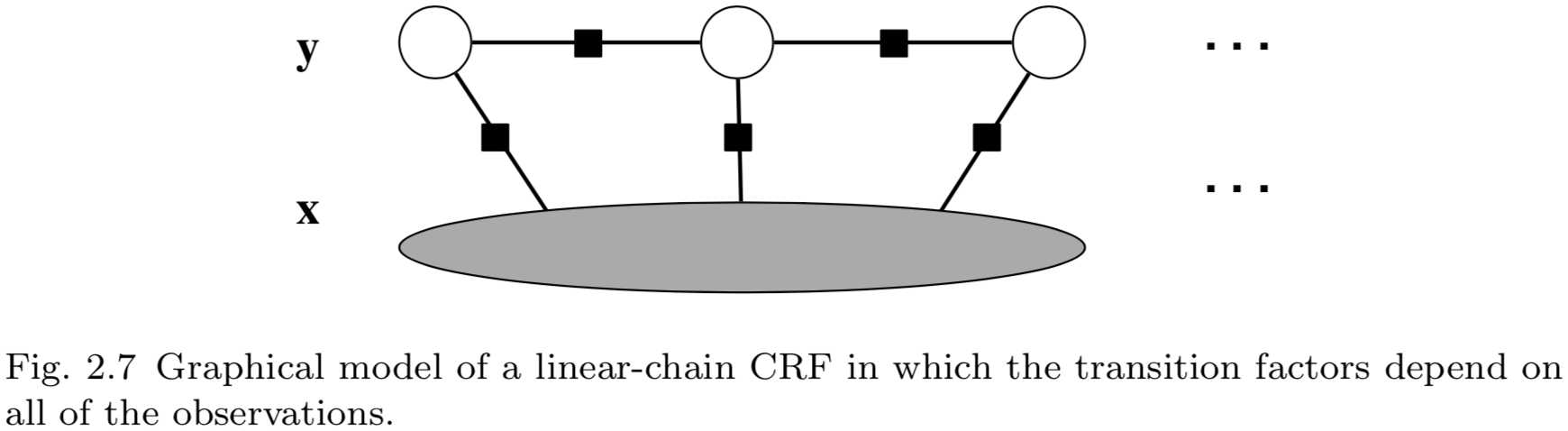
为了说明每个特征都可以依赖于所有时间步观测值的线性链条件随机场,我们将\\(f_k\\)中的观测值参数写为一个向量\\(\\mathbf{x}_t\\),该向量应该理解为包含所有需要在时间\\(t\\)计算特征的全局观测值\\(\\mathbf{x}\\)。例如,如果条件随机场使用了后继词\\(x_{t+1}\\)作为特征,则特征向量\\(\\mathbf{x}_t\\)包含词\\(x_{t+1}\\)。
最后,注意到归一化常数\\(Z(\\mathbf{x})\\)对所有可能的状态序列进行求和,包含了指数级的项数。不过,可以利用前向-后向算法高效的计算,参见4.1节。
2.4 任意结构条件随机场
本节我们将线性链条件随机场扩展至任意图结构之上,与Lafferty等[63]最早给出的条件随机场定义一致。从概念上来说,这种扩展非常直接,只需简单地从线性链因子图转移至任意结构的因子图之上。
定义 2.3 令\\(G\\)为\\(X\\)和\\(Y\\)之上的因子图。如果对\\(X\\)的任意取值\\(\\mathbf{x}\\),分布\\(p(\\mathbf{y}|\\mathbf{x})\\)能因子分解为\\(G\\),则\\((X,Y)\\)是一个条件随机场。
因此,每个条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)都是对应着因子图(或许没有什么价值)的条件随机场。如果\\(F=\\{\\Psi_a\\}\\) 是\\(G\\)中的因子集合,则条件随机场的条件分布为
\\[
p(\\mathbf{y}|\\mathbf{x})=\\frac{1}{Z(\\mathbf{x})}\\prod_{a=1}^A \\Psi_a (\\mathbf{y}_a, \\mathbf{x}_a).
\\tag{2.22}
\\]
上式与无向图模型一般定义(式2.1)的不同之处在于归一化常量变为归一化函数\\(Z(\\mathbf{x})\\)。由于条件能够使图模型得到简化,因此\\(Z(\\mathbf{x})\\)可以计算,而常量\\(Z\\)则通常难以计算。
正如我们在隐马尔可夫和线性链条件随机场中所做的那样,令\\(\\log \\Psi_a\\)为预定特征集上的线性函数,即
\\[
\\Psi_a(\\mathbf{y}_a,\\mathbf{x}_a)=\\exp \\left\\{ \\sum_{k=1}^{K(A)} \\theta_{ak} f_{ak}(\\mathbf{y}_a, \\mathbf{x}_a) \\right\\},
\\tag{2.23}
\\]
其中,不管是特征函数\\(f_{ak}\\)还是权值\\(\\theta_{ak}\\)的下标都包含\\(a\\),用以强调每个特征在不同因子中有不同的权值。甚至不同的因子有着不同的特征函数集。注意如果\\(\\mathbf{x}\\)和\\(\\mathbf{y}\\)是离散的,则对数线性假设(式2.23)没有其他的限制,因为我们可以为每个取值\\((\\mathbf{y}_a, \\mathbf{x}_a)\\)选择不同的指示函数\\(f_{ak}\\),与我们将隐马尔可夫转换成线性链条件随机场所采用的方法类似。
合并式(2.22)和式(2.23),具有对数线性因子的条件随机场的条件分布为:
\\[
p(\\mathbf{y}|\\mathbf{x}) = \\frac{1}{Z(\\mathbf{x})} \\prod_{\\Psi_A \\in F} \\exp \\left\\{
\\sum_{k=1}^{K(A)} \\theta_{ak}f_{ak}(\\mathbf{y}_a, \\mathbf{x}_a)
\\right\\}.
\\tag{2.24}
\\]
另外,大多数应用模型常常依赖参数绑定。例如,在线性链条件随机场中,各个时间步中的因子\\(\\Psi_t(y_t,y_{t-1},\\mathbf{x}_t)\\)通常会使用相同的权重。为进一步说明,我们将\\(G\\)的因子划分为\\(\\mathcal{C}=\\{C_1, C_2, \\cdots, C_P\\}\\),其中每个\\(C_p\\)是一个团模板(clique template),团模板是一组共享特征函数集\\(\\{f_{pk}(\\mathbf{x}_c,\\mathbf{y}_c)\\}_{k=1}^{K(p)}\\)和相应的参数集\\(\\theta_p \\in \\Re^{K(p)}\\)的因子。利用团模板,条件随机场可以写为
\\[
p(\\mathbf{y}|\\mathbf{x})=\\frac{1}{Z(\\mathbf{x})}\\prod_{C_p \\in \\mathcal{C}} \\prod_{\\Psi_c \\in C_p} \\Psi_c(\\mathbf{x}_c, \\mathbf{y}_c; \\theta_p) ,
\\tag{2.25}
\\]
其中,每个模板因子的参数化形式为
\\[
\\Psi_c(\\mathbf{x}_c, \\mathbf{y}_c; \\theta_p)=\\exp \\left\\{
\\sum_{k=1}^{K(p)} \\theta_{pk}f_{pk}(\\mathbf{x}_c, \\mathbf{y}_c)
\\right\\},
\\tag{2.26}
\\]
规范化函数为
\\[
Z(\\mathbf{x})=\\sum_{\\mathbf{y}} \\prod_{C_p \\in \\mathcal{C}} \\prod_{\\Psi_c \\in C_p} \\Psi_c(\\mathbf{x}_c, \\mathbf{y}_c; \\theta_p).
\\tag{2.27}
\\]
团模板的思想指定了图中的重复结构及模型的参数绑定。例如,在线性链条件随机场中,整个网络构成一个团模板\\(C_0=\\{\\Psi_t(y_t,y_{t-1},\\mathbf{x}_t)\\}_{t=1}^T\\),于是\\(\\mathcal{C}=\\{C_0\\}\\)是一个单元素集合( singleton set)。如果我们希望每个因子\\(\\Psi_t\\)在每个时间步\\(t\\)具有不同的参数,类似于非同质隐马尔可夫模型,可以令\\(\\mathcal{C}=\\{C_t\\}_{t=1}^T\\)为\\(T\\)个模板,其中\\(C_t=\\{\\Psi_t(y_t,y_{t-1},\\mathbf{x}_t)\\}\\)。
在任意结构条件随机场中,因子可以有不同的特征集和参数集。当然,其中有的因子也可以有相同的特征集和参数集。团模板就是那些具有相同特征集和参数集的因子的集合。若团模板确定,则可将条件随机场由因子表示形式转化为团模板表示形式。每个团模板中,参数集和特征集固定不变,因此称为参数绑定。
定义任意结构条件随机场时要考虑的最重要的问题之一,就是指明重复结构和参数绑定。有多种方法可以指明参数绑定,下面进行简要介绍。例如,动态条件随机场(dynamic conditional ramdom fields)[140]允许每个时间步中有多个标记,与动态贝叶斯网络类似。第二个是关系马尔可夫网络(relational Markov networks)[142],其图结构和参数绑定由SQL-like语法确定。马尔可夫逻辑网络(Markov logic networkss)[113,128]利用逻辑公式指定无向模型中局部函数的范围(scopes)。本质上,知识库中每个一阶规则都有一组参数。可以将马尔可夫逻辑网络的逻辑部分(logic protion)看作是一种编程约定(programming convention),用于指定无向模型的重复结构和参数绑定。命令定义因子图(imperatively defined factor graphs)[87]利用图灵完全函数(Turing-complete functions)的完全表达性定义团模板,具体说明了模型的结构和充分统计量\\(f_{pk}\\)。图灵完全函数具有利用递归、任意搜索(arbitrary search)、惰性评价(lazy evaluation)、记性化(memoization,)等高级编程思想的能力。本文团模板的概念受到Taskar等[142]、Sutton等[140]、Richardson和Domingos[113]、McCallum等[87]的启发。
2.5 特征工程
本节介绍特征工程相关的一些技巧(tricks of the trade)。尽管这些技巧主要来自自然语言处理方面应用,但是在其他领域也具有一定的通用性。主要考虑的是经典的取舍矛盾,即利用较大的特征集可以得到更高的精度,因为最终的决策边界更有弹性,但是另一方面来说,更大的特征集要求更大的存储空间以保存所有的参数,而且存在过学习的风险,反而可能会降低模型的精度。
标记-观测特征(Label-observation features)。 首先,当标记变量离散取值的时候,团模板\\(C_p\\)的特征\\(f_{pk}\\)通常采用一种特殊的形式:
\\[
f_{pk}(\\mathbf{y}_c, \\mathbf{x}_c)=\\mathbf{1}_{\\{ \\mathbf{y}_c=\\tilde{\\mathbf{y}}_c \\}} q_{pk}(\\mathbf{x}_c).
\\tag{2.28}
\\]
或者说,每个特征仅在输出配置(configuration)\\(\\tilde{\\mathbf{y}}_c\\)下非0,但是只要满足条件,特征取值仅依赖于输入观测。我们将这种形式的特征称为__标记-观测特征__。本质上,可以认为特征仅依赖于输入\\(\\mathbf{x}_c\\),但是对于每个输出配置,有单独的权重集。这种特征表示方法在计算上也比较有效率,因为计算每个\\(q_{pk}\\)可能涉及到大量的文本或图片处理,使用这种特征表示方法则对于每个特征只需要计算一次。为了避免混淆,我们并不将函数\\(q_{pk}(\\mathbf{x}_c)\\)称为特征,而是称为观测函数。下面是两个观测函数的例子,“word \\(x_t\\) is captialized”,以及“word \\(x_t\\) ends in ing”。
输出配置确定了该特征与哪些输出(或状态)相关,一量确定了输出配置,则该特征仅与观测值相关。这应该是最常见的特征类型之一。
不支持特征(Unsupported Features)。使用标记-观测特征会包含大量的参数。例如,在第一个大规模条件随机场应用中,Sha和Pereira[125]的最佳模型中包含了380万个二值特征。这些特征中的相当一部分在训练集中没有出现,因此其值总是0。原因在于,某些观测函数仅在少数标记中出现。例如,在命名实体识别任务中,特征“word \\(x_t\\) is with and label \\(y_t\\) is CITY-NAME”在训练数据中取值不太可能为1。我们将这种特征称为__不支持特征__。可能会令人感到惊讶,这些特征是有用的。这是因为它们可以被赋予一个负权,从而使得错误标记(如例子中的CITY_NAME)难以到较高的概率。(降低在训练数据中不存在的标记序列的评分将会使出现在训练数据中的标记序列的评分更高,因此后续章节中的参数估计过程会将这些特征赋负值。)模型中使用不支持特征通常会使精确度得到少量提升,但代价是模型中的参数数量会大大增加。
下面介绍一种我们曾成功应用的方法,能够在使用较少内存的情况下利用不支持特征的优点。这种方法称为“不支持特征技巧”,它仅在模型中选择一个较小的不支持特征集。其思想是,很多不支持特征是无用的,因为模型不太可能会错误地激活它们。例如,前文中的特征“with”是一个通常与OTHER标记(表示非命名实体)高度相关联的词。为了减少参数数量,我们在模型中仅使用将那些能够降低错误的不支持特征。一个简单的办法是:首先训练一个没有使用不支持特征的条件随机场,经过数次迭代在模型还没有充分训练时即停止。然后在模型中所有还没有高可信度正确结果的团中加入不支持特征。在前面的例子中,如果我们找到一个训练实例\\(i\\)中位置\\(t\\)的词\\(x_t^{(i)}\\)是with,标记\\(y_t^{(i)}\\)不是CITY-NAME,但\\(p(y_t=\\text{CITY-NAME} | \\mathbf{x}_t^{(i)})\\)大于一个阈值\\(\\epsilon\\),那么就在模型中加入“with”特征。
边-观测特征和节点-观测特征(Edge-Observation and Node-Observation Features)。为了减少模型中特征的数量,我们可以为特定的团模板使用标记-观测特征,但其他团模板不使用。__边-观测特征__和__节点-观测特征__是两种最常见的标记-观测特征。考虑一个具有\\(M\\)个观测函数\\(\\{q_m(\\mathbf{x})\\}\\ (m \\in \\{1,2,\\cdots, M\\})\\)的线性链条件随机场。如果使用了边-观测特征,每个转移【状态转移】的因子可以依赖于所有的观测函数,于是我们可以利用诸如“word \\(x_t\\) is New, label \\(y_t\\) is LOCATION and label \\(y_{t-1}\\) is LOCATION”这样的特征。这会使得模型中包含大量的参数,这样对内存使用不利而且容易过度学习。减少参数数量的一种方法是利用节点-观测特征替代边-观测特征。利用这种特征,转移因子不再依赖于观测函数。于是我们可以使用诸如“label \\(y_t\\) is LOCATION and label \\(y_{t-1}\\) is LOCATION”和“word \\(x_t\\) is NEW and label \\(y_t\\) is LOCATION”这样的特征,但是不能使用同时依赖\\(x_t, y_t\\)和\\(y_{t-1}\\)的特征。表2.1正式地描述了边-观测特征和节点-观测特征。同样,哪种选择更好依赖于具体问题,例如观测函数数量和数据集大小。

”边“是指状态之间的边(状态转移)。边-观测特征中,__转移特征__与观测值相关,而节点-观测特征中,__转移特征__与观测值与边无关;两种情况下,__状态特征__都可以与观测值相关。
边界标记(Boundary Labels)。另一个问题是如何处理边界标记,即序列的开始和结尾,或者图像的边缘。有时候边界标记与其他标记具有不同的特征。例如,句子中间的首字母大写词汇常表示专有名词,但是是句子第一个词首字母大写却不是。处理该问题的方法是在每个句子的标记序列前添加一个START标记,从而模型能够学习具有任何特征的边界标记。例如,如果使用了边-观测特征,那么诸如“\\(y_{t-1}=\\text{START}\\) and \\(y_t = \\text{PERSON}\\) and word \\(x_t\\) is capitalized”这样的特征可以表示首字母大写的句首词并不能表明它是一个专有名词。
特征归纳(Feature Induction)。前文中所述的“不支持特征技巧”是没办法中的办法(poor man’s version of feature induction)。McCallum[83]给出了一种合理的方法:条件随机场特征归纳。模型从一些基本特征开始,在训练过程中加入其他特征。或者,可以利用特征选择。特征选择的一种更现代的方法是\\(L_1\\)规则化(\\(L_1\\)regularization),我们将在第5.1.1节中讨论该方法。Lavergne等[65]发现在最有利情况下,\\(L_1\\)发现模型全部特征中仅有1%为非0。仅使用这些特征,获得了与使用高密度特征配置类似的性能。他们还发现,在使用优化的\\(L_1\\)规则化似然来寻找非0特征之后,仅利用一个\\(L_2\\)规则化目标对非0特征的权值进行微调也有用。
定类特征(Categorical Features)。如果观测值是定类的而非定序的,即观测值是离散但没有内在排序的,那么就需要将它们转化为二值特征。例如,在\\(f_k(y,x_t)\\)上学习线性权重时,如果\\(x_t\\)是词dog则\\(f_k\\)是1,否则为0,这是有意义的。但是若\\(f_k\\)是词\\(x_t\\)在词汇表中的序号,这样就是无意义的。因此,在文本处理应用中,条件随机场的特征通常是二值的;在其他应用领域,比如视觉和语音领域,特征常常是实值。对于实值特征,可以利用经典的方法,例如可将特征标准化为均值为0方差为1的形式,或者将其转化为定类取值再转化为两值特征。
来自不同时间步的特征(Features from Different Time Steps)。尽管我们定义的特征函数\\(f(y_t,y_{t-1},\\mathbf{x}_t)\\)中没有指明,但是要知道特征不仅可以依赖当前标记,还可以依赖相邻的标记。例如,“word \\(x_{t+2}\\) is Times and label \\(y_t\\) is ORGANIZTION”,在识别New York Times(作为报纸)的时候会非常有用。还可以利用来自多个时间步的特征,如“words \\(x_{t+1}\\) and \\(x_{t+2}\\) are York Times”。
备用特征(Features as Backoff)。在语言应用中,有时候在模型中包含冗余因子会很有帮助。例如,在线性链条件随机场中,会同时包含边因子\\(\\Psi_t(y_t,y_{t-1},\\mathbf{x}_t)\\)和变量因子\\(\\Psi_t(y_t,\\mathbf{x}_t)\\)。尽管仅利用边因子就可以定义同样的分布族,但冗余的节点因子会带来与语言模型中的备用特征相似的优势,即在特征数量比较多而数据集比较小时(有成百上千的特征,但数据集很小!)。在使用冗余特征时,对其进行标准化非常重要(5.1.1节),因为较大权值的惩罚作用使得权值可以通过重叠特征扩散。
作为模型联合的特征(Features as Model Combination)。另一种有意思的特征,是来自相同任务的更简单的方法的结果。例如,如果已经有了一个简单的基于规则的系统(例如,包含规则“any string of digits between 1900 and 2100 is a year”),系统的预测可以作为另一个条件随机场的观测函数。另一个例子是地名辞典特征,这是基于预定义词项列表的观测函数,如“\\(q(x_t)=1\\) if \\(x_t\\) appears in a list of city names obtained from Wikipedia”。【基于规则的特征,或是否在列表中的存在作为特征】
更复杂的例子是利用一个生成模型的输出作为另一个判别模型的输入。你如,可以利用这样的特征\\(f_t(y,\\mathbf{x})=p_{HMM}(y_t=y|\\mathbf{x})\\),其中\\(p_{HMM}\\)是在类似数据集上训练的HMM模型中标记\\(y_t=y\\)的边缘概率。可能在同样的数据集上训练HMM和CRF-with-HMM-feature并不是一个好主意,因为HMM在其自己的数据集上可能表现很好,这会造成CRF过于依赖HMM。当目标是提升现有系统在同样任务上的性能时,这种方法比较有用。Bernal等[7]研究从DNA序列中识别基因,这是一个使用该方法的一个很好的例子。
另一个相关的思想是对输入\\(\\mathbf{x}_t\\)进行聚类,即用你喜欢的任何方法对语料库中的词进行聚类,然后利用词\\(x_t\\)的聚类标记作为附加特征。这种特征在Miller等[90]中使用的效果很好。
输入依赖的结构(Input-Dependent Structure)。在任意结构条件随机场中,有时候允许\\(p(\\mathbf{y}|\\mathbf{x})\\)的图结构依赖于输入\\(\\mathbf{x}\\)会有帮助【结构随输入变化】。一个简单的例子是“skip-chain CRF”[37,117,133],它已经被用在文本应用中。这种条件随机场背后的思想,是当相同的词两次出现在同一个句子中时,我们倾向于给它们做相同的标记。因此,我们在相应的两个词之间添加一条连边。这样,就得到了一个依赖于输入\\(\\mathbf{x}\\)的\\(\\mathbf{y}\\)的图结构。
2.6 实例
本节详细给出了两个条件随机场应用实例。第一个是用于自然语言文本的线性链条件随机场,第二个是用于计算机视觉的网状结构条件随机场。
2.6.1 命名实体识别
命名实体识别是将恰当的名称识别并分割出来,如文本中的人或组织的名称。文中在很多地方都使用了该例子,现在我们详细介绍利用条件随机场解决该问题的细节内容。
实体(entity)是世界上的人、地方或东西,提述(mention)是实体的名称所对应的的短语或文本。命名实体识别是分割问题(segmentation)的一种,因为在英语中命名实体常涉及到多个词,如_The New York Times_、_the White House_等。实体的类型与具体问题相关。例如,在CoNLL2003评测的分享任务[121] (Conference on Computational Natural Language Learning, CoNLL)中,实体是人名、地名、组织,以及混杂实体(miscellaneous entities)。在生物医学中[55,51],主要分割问题的目的是提取分子生物学文献中的表达信息。因此,实体包括基因、蛋白质、细胞系(cell line)等。本节,我们考虑CoNLL2003的分享任务,因为它是早期条件随机场应用的代表。
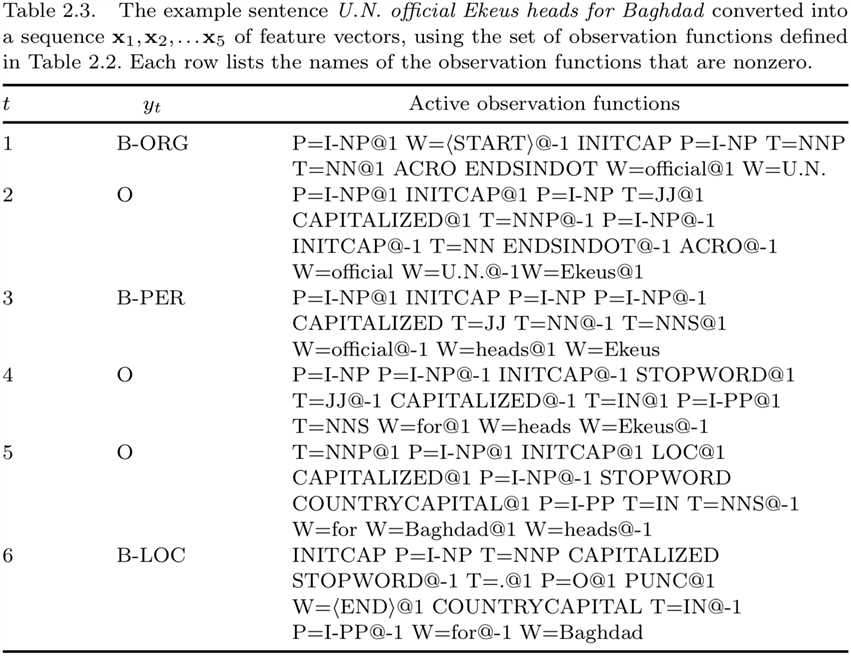
CoNLL2003分享任务的数据由英文和德文新闻文章组成。英文文章是路透社从1996到1997年间的联机新闻文章。训练集包括946篇新闻203621个符号,开发集(development set)包括216篇文章51362个词,测试集包括231篇文章46435个词。每篇文章都经过手工标注,包括命名实体的位置及类型。例如句子 U.N. official Ekeus heads for Baghdad。句中,_U.N._被标记为组织,_Ekeus_被标记为人名,_Baghdad_被标记为地名。
为了将该问题表示为序列标注问题,我们需要将实体的标签转换成标记序列。标记需要能够将多个词识别为一个实体(如_New York Times_)。我们采用一种标准的技巧:利用标记(B-???)表示实体的第一个词,利用(I-???)表示实体其他的词,利用O表示非实体词。这种标记框架被称为BIO符号,其优点是它能将相邻的两个同类型实体切分开,如_Alice gave Bob Charlie’s ball_,而且B-???标记可与相应的I-???标记有不同的权重。此外,还有与BIO不同的标记方法,可以将分割问题转成实体标记问题,但是我们这里不作更多介绍。
在CoNLL2003数据集中有四种类型的实体:人(PER)、组织(ORG)、地方(LOC)及其他(MISC)。因此我们需要9个种标记
\\[
\\mathcal{Y}=\\{\\text{B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG, B-MISC, I-MISC, O}\\}
\\]
利用这种标记方法,我们将前面的例句标记为如下形式
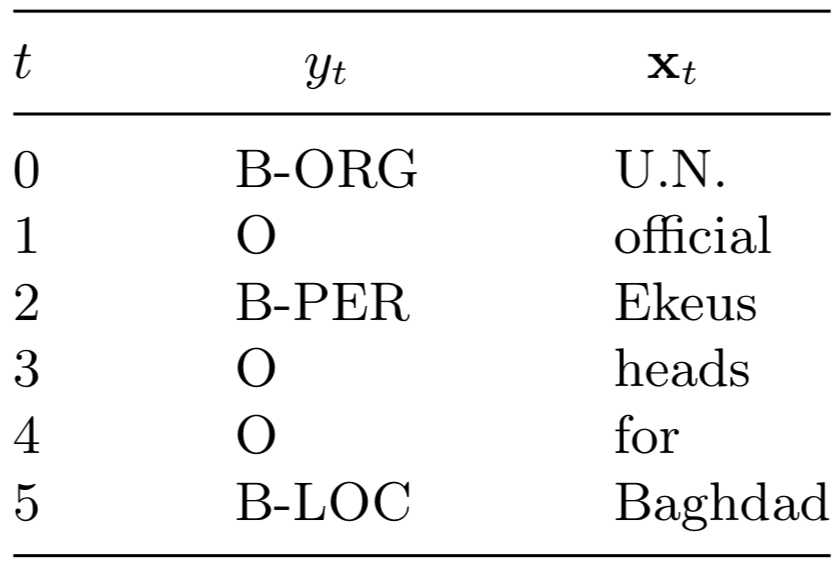
为了为该问题定义一个线性链条件随机场,我们需要确定特征函数\\(f_k(y_t,y_{t-1},\\mathbf{x}_t)\\)的集合\\(\\mathcal{F}\\)。最简单的选择是我们前面描述过的像HMM那样的特征集。该特征集中有两种类型的特征。第一种称为标记-标记(label-label)特征,即
\\[
f_{ij}^{LL}(y_t,y_{t-1},\\mathbf{x}_t)=\\mathbf{1}_{\\{y_t=i\\}}\\mathbf{1}_{\\{y_{t-1}=j\\}} \\ \\forall i,j \\in \\mathcal{Y}.
\\tag{2.29}
\\]
该问题有9个不同的标记,因此有81个标记-标记特征。第二种是标记-单词特征,即
\\[
f_{iv}^{LW}(y_t,y_{t-1},\\mathbf{x}_t)=\\mathbf{1}_{\\{y_t=i\\}}\\mathbf{1}_{\\{\\mathbf{x}_t=v\\}}\\ \\forall i \\in \\mathcal{Y}, v \\in \\mathcal{V},
\\tag{2.30}
\\]
其中,\\(\\mathcal{V}\\)是在语料库中出现的所有不重复单词。在CoNLL2003的英语数据集中,有21249个词,因此共有191241个标记-单词特征。其中的大部分没有太大用途,很多词在训练集中仅出现一次。对比式(2.18),完整的特征集为\\(\\mathcal{F}=\\{f_{ij}^{LL}| \\forall i,j \\in \\mathcal{Y} \\} \\cup \\{f_{iv}^{LW} \\forall i \\in \\mathcal{Y}, v \\in \\mathcal{V} \\}\\)。
实际的NER(命名实体识别)系统中使用的特征会更多。例如,当预测单词_Baghbad_的标记时,知道前一个词_for_的标记会很有用。为了表示这种特征,我们在每个向量\\(\\mathbf{x}_t\\)中增加了相邻的词,即\\(\\mathbf{x}_t=(x_{t0},x_{t1},x_{t2})\\),其中\\(x_{t1}\\)是位于\\(t\\)的词,\\(x_{t0}\\)和\\(x_{t2}\\)分别是其前一个和后一个词。序列的开始和结属加上特殊标记\\(\\langle \\text{START} \\rangle\\)和\\(\\langle END \\rangle\\)。例句如下所示

为了构建一个条件随机场,我们保留前面的标记-标记特征,但是现在我们有三种不同的标记-单词特征:
\\[
\\begin{align}
f_{iv}^{LW0}(y_t,y_{t-1},\\mathbf{x}_t) & = \\mathbf{1}_{\\{y_t=i\\}}\\mathbf{1}_{\\{x_{t0}=v\\}} \\forall i \\in \\mathcal{Y}, v \\in \\mathcal{V} \\f_{iv}^{LW1}(y_t,y_{t-1},\\mathbf{x}_t) & = \\mathbf{1}_{\\{y_t=i\\}}\\mathbf{1}_{\\{x_{t1}=v\\}} \\forall i \\in \\mathcal{Y}, v \\in \\mathcal{V} \\f_{iv}^{LW2}(y_t,y_{t-1},\\mathbf{x}_t) & = \\mathbf{1}_{\\{y_t=i\\}}\\mathbf{1}_{\\{x_{t2}=v\\}} \\forall i \\in \\mathcal{Y}, v \\in \\mathcal{V}.
\\end{align}
\\]
不过, 我们还希望使用更多特征,大部都是基于单词\\(x_t\\)的。包括标记-观测特征(如2.5节所示)。为定义该特征,我们定义一列观测函数\\(q_b(x)\\),它的参数为单个词汇。对于每个观测函数\\(q_b\\),相应的标记-观测特征\\(f_{ib}^{LO}\\)的形式为:
\\[
f_{ib}^{LO}(y_t,y_{t-1},\\mathbf{x}_t)=\\mathbf{1}_{\\{y_t = i \\}}q_b(\\mathbf{x}_t) \\ \\ \\forall i \\in \\mathcal{Y}.
\\tag{2.31}
\\]
MCCallum和Li[86]在该数据集上使用条件随机场时,他们使用了大量观测-标记函数,部分如表2.2所示。这些函数都是二值函数。基于这三种特征集的例句如表2.3所示。为了显示特征集,我们这给出的是对每个词都非0的观测函数。
这些特征是文本处理中典型的条件随机场特征集,但是并非是最好的。在于该特殊的任务,Chieu和Ng[20]给出了一个使用单一模型(没有使用集成方法)的非常好的特征集,

2.6.2 图片标记
许多不同结构的条件随机场已被用于计算机视觉。在本例中,我们根据是否前景或背景、是否是人造结构[61,62]、是否是天空、水或植物等[49],对图片区域进行分类。
更严格地,令向量\\(\\mathbf{x}=\\{x_1,x_2,\\cdots,x_T \\}\\)表示大小为\\(\\sqrt{T} \\times \\sqrt{T}\\)的图片。也就是说,\\(\\mathbf{x}_{1:\\sqrt{T}}\\)为图片第一行的像素,\\(\\mathbf{x}_{\\sqrt{T}+1:2\\sqrt{T}}\\)表示第二行的像素,以次类推。\\(x_i\\)表示相应的像素值。为了简单起见,将图片处理为黑白的,于是每个\\(x_i\\)的取值为0到256,表示位置\\(i\\)的像素的色彩强度(彩色图片的处理方式类似)。目的是预测一个向量\\(\\mathbf{y}=(y_1,y_2,\\cdots,y_T)\\),其中每个\\(y_i\\)为像素\\(i\\)的标记,如果该像素属于图片中的人造结构则为\\(+1\\),否则为\\(-1\\)。
计算机视觉文献中提出了多种图像特征。一个简单的例子,给定位于\\(i\\)的像素,我们基于以\\(i\\)为中心的\\(5\\times 5\\)的像素阵计算一个像素密度直方图(histogram),然后以直方图中每个值的计数作为特征。实际中会用到更为复杂的特征,例如图像的概率为基、纹理基元特征(texton features)[127]、SIFT特征[77]等。重要的是,这些特征都不仅仅依赖于像素\\(x_i\\);大部分有趣的特征依赖于一个像素区域,甚至是整个图片。
图片的一个基本特点是相邻的相素倾向于具有相同的标记。将该特点考虑进模型的一种方法是在\\(\\mathbf{y}\\)上利用先验分布来“平滑”预测。计算机视觉中最常使用的先验分布是网格状结构的无向图模型,称为马尔可夫随机场(Markov random field)[10]。马尔可夫随机场是一种生成式无向模型,其中有两种因子:一种将每个标记\\(y_i\\)与对应的\\(x_i\\)相连系,另一种使得标记\\(y_i\\)和\\(y_j\\)倾向于有相同的标记。
更严格地,令\\(\\mathcal{N}\\)为相素之间的相邻关系(neighborhood relationship),\\((i,j)\\in \\mathcal{N}\\)当且仅当\\(x_i\\)和\\(x_j\\)为相邻像素。\\(\\mathcal{N}\\)构成了一个\\(\\sqrt{T}\\times \\sqrt{T}\\)的格子。马尔可夫随机场是一个生成模型:
\\[
\\begin{align}
p(\\mathbf{y}) &=\\frac{1}{Z} \\prod_{(i,j) \\in \\mathcal{N}} \\Psi(y_i,y_j) \\p(\\mathbf{y}, \\mathbf{x})&=p(\\mathbf{y})\\prod _{i=1}^Tp(x_i|y_i). \\tag{2.32}
\\end{align}
\\]
其中,\\(\\Psi\\)是能够促进平滑因子。一般情况下其形式为:若\\(y_i=y_j\\)则\\(\\Psi(y_i,y_j)=1\\),否则\\(\\Psi(y_i,y_j)=\\alpha\\)。\\(\\alpha\\)为从数据中学习到的参数,一般\\(\\alpha < 1\\)。原因在于当\\(\\alpha<1\\)时最大化\\(\\log p(\\mathbf{y}, \\mathbf{x})\\)具有高效的算法。分布\\(p(x_i|y_i)\\)是一个像素值上的类别-条件分布(class-conditional distribution),例如,\\(x_i\\)上的混合高斯分布。
马尔可夫随机场的缺点是,它难以利用如前面所述的像素区域上的特征,因为这些特征会使\\(p(\\mathbf{x}|\\mathbf{y})\\)非常复杂。条件模型可以解决这个问题。
马尔可夫随机场仅能利用相信像素是否具有相同标记的信息,以及给定标记条件下像素值的条件分布信息。不能利用其他的特征。
下面我介要介绍的用于该任务的条件随机场与马尔可夫随机场非常像似,唯一的不同在于条件随机场允许像素点和像素连边的因子依赖任意图像特征。令\\(q(x_i)\\)为基于\\(x_i\\)附近图像区域的特征构成的向量,例如,利用前面提到的颜色直方图(color histograms)或图像梯度(image gradient)。除此之外,我们还需要一个依赖于像素点对\\(x_i\\)和\\(x_j\\)的特征向量\\(\\nu(x_i,x_j)\\),以使得模型能够将\\(x_i\\)和\\(x_j\\)的相似或不同之处考虑进去。方法之一,是将\\(\\nu(x_i,x_j)\\)定义为\\(q(x_i)\\)和\\(q(x_j)\\)中特征的向量积(cross-products)的集合。也就是说,为了计算\\(\\nu(x_i,x_j)\\),首先通过计算外积矩阵\\(q(x_i)q(x_j)^\\top\\),然后再变为向量。
我们将函数\\(q\\)和\\(\\nu\\)称为特征,因为在计算机视觉领域常使用这样的术语。但是在本文中,我们已经将“特征”这个词用于描述输入\\(\\mathbf{x}\\)和标记\\(\\mathbf{y}\\)。因此,下文中我们将\\(q\\)和\\(\\nu\\)称为观测函数,用以定义条件随机场中的标记-观测特征。由此,得到的标记-观测特征为
\\[
\\begin{align}
f_m(y_i,x_i) &= \\mathbf{1}_{\\{y_i=m\\}}q(x_i) \\ \\ \\forall m \\in \\{0,1\\} \\g_{m,m‘}(y_i,y_j,x_i,x_j)& = \\mathbf{1}_{\\{y_i=m\\}}\\mathbf{1}_{\\{y_i=m‘\\}} \\nu(x_i,x_j) \\ \\ \\forall m,m‘ \\in \\{0,1\\} \\f(y_i,x_i) &= \\left( \\begin{array}{c} f_0(y_i,x_i) \\\\ f_1(y_i,x_i) \\end{array} \\right) \\g(y_i,y_j,x_i,x_j) &= \\left( \\begin{array}{c} g_{00}(y_i,y_j,x_i,x_j)\\\\ g_{01}(y_i,y_j,x_i,x_j)\\\\ g_{10}(y_i,y_j,x_i,x_j)\\\\ g_{11}(y_i,y_j,x_i,x_j) \\end{array}\\right)
\\end{align}
\\]
利用标记-观测特征使得模型中每个标记可以有单独的权值集合。
为了使这个例子更加具体化,下面给出\\(g\\)和\\(\\nu\\)的一种形式(来自一些著名的应用[14,119])。考虑马尔可夫随机场(式2.32)中的每对因子\\(\\Psi(x_i,y_j)\\),尽管它使\\(x_i\\)和\\(y_i\\)趋于一致,但其方式不够灵活。如果像素\\(x_i\\)和\\(x_j\\)具有不同的标记,我们希望它们具有不同的颜色强度,因为不同的物体往往具有不同的色调。因此,如果我们看到标记边界上的两个像素具有非常不同的色度,这不令人奇怪,但是如果这两个像素具有同样的色度,这就令人生疑了。不幸地,\\(\\Psi\\)在两种情况下给出了同样的惩罚,因为the potential不依赖于像素值。为了解决这个问题,我们采用了文献[14,119]中提出的方法:
\\[
\\begin{align}
\\nu(x_i,x_j) &=\\exp\\{-\\beta (x_i-x_j)^2\\}\\g(y_i,y_j,x_i,x_j) &=\\mathbf{1}_{\\{y_i\\neq y_j\\}}\\nu(x_i,x_j). \\tag{2.33}
\\end{align}
\\]
综合以上分析,条件随机场模型为:
\\[
p(\\mathbf{y}|\\mathbf{x}) = \\frac{1}{Z(\\mathbf{x})} \\exp \\left\\{ \\sum_{i=1}^T \\theta^\\top f(y_i,x_i) + \\sum_{(i,j)\\in \\mathcal{N}} \\lambda^\\top g(y_i,y_j,x_i,x_j) \\right\\},
\\tag{2.34}
\\]
其中,\\(\\alpha \\in \\Re, \\theta \\in \\Re^K, \\lambda \\in \\Re^{K^2}\\)为模型参数。前两项类似于条马尔可夫随机场中的两种因子。第一项表示\\(x_i\\)的局部信息对标记\\(y_i\\)的作用。利用式(2.33)中的\\(g\\),第二项使得相邻的标记趋于相似,而且依赖于不同的像素密度。
这是式(2.25)定义的任意结构条件随机场的一个例子,式(2.25)中有三个团模板,式(2.34)中的三项每项对应着一个。
式(2.34)与(2.32)的区别类似于图2.6和图2.5中线性链条件随机场的区别。成对因子依赖于图像特征而不仅仅是标记自身。另外,正如序列的情况类似,马尔可夫随机场模型(式2.32)的条件分布\\(p(\\mathbf{y}|\\mathbf{x})\\)是条件随机场的一个特例,即式(2.34)中\\(\\lambda=0\\)的情况。
这个简单的条件随机场模型有多种改进方法。首先,特征函数\\(q\\)和\\(\\nu\\)可以更复杂,例如,考虑图像形状和基本结构(texture)[127],或者依赖于图像的全局特征而不是局部特征。此外,还可以使用结构比网格更复杂的标记结构。例如,可以定义基于标记区域的因子[49,56]。关于计算机视觉领域条件随机场和其他结构的预测模型,可以参考Nowozin和Lampert[101]。
2.7 条件随机场的应用
除了上面的两个例子,条件随机场还被运用到其他很多领域之中,包括文本处理、计算机视觉、生物信息等。条件随机场第一个大规模使用的是Sha和Pereira[125],获得了名词从句分割的最好的效果。在那之后,线性链条件随机场被用于许多自然语言处理问题,包括命名实体识别[86],NER特征归纳[83],浅度解析[125,138],蛋白质名称识别[124],网页地址提取[29],信息整合[156],语义角色分析[118],音调口音预测[47],语音处理中的电话分类[48],观点源识别[21],机器翻译中的单词对齐[12],论文中的引用抽取[105],文档表格信息抽取[106],中文分词[104],日文词法分析[59],等等。
在生物信息领域,条件随机场被用于RNA结构分析[123]和蛋白质结构预测[76]。半马尔可夫(Semi-Markov)条件随机场[122]允许使用更加灵活的特征函数。在线性链条件随机场中,特征函数\\(f()\\)被限制在仅能依赖于连续的标记对。而在半马尔可夫条件随机场中,特征函数可以依赖于更多的标记,即一个具有相同值的标记序列。在许多依赖抽取任务中非常有用。
任意结构条件随机场还被用于自然语言处理的多种任务中。其中之一,是同时进行多种标记的任务。例如,Sutton等[140]使用了一个两层动态条件随机场,同时进行词性标记和名词短识提取。另一种应用是多标记分类(multi-label classification),每个实例可以有多种标记。Ghamrawi and McCallum [42]给出了一个能够学习不同类别之间依赖关系的条件随机场,因此不再为每个类别给出单独的分类器,提高了分类质量。最后,skip-chain CRF [133]是一种任意结构条件随机场,能够表示信息抽取中的长程依赖关系。
另一种使用不同结构的任意结构CRFs的应用是在专有名词共指(proper-noun coreference)问题上,即确定文档中提到的实体,例如Mr. President 和he指同一实体。McCallum和Wellner[88]利用一个完全连接的条件随机场来解决这个问题。类似的模型还用在手写字母和图表的分割之上[26,108]。
如2.6.2节所述,条件随机场被广泛用于计算机视觉中,例如,网格结构(grid-shaped)条件随机场用于标注和切分图片[49,61,127]。尽管图片标记是计算机视觉中常见的条件随机场应用,但在该领域还有很多其他问题可以使用条件随机场。例如,Quattoni等[109]利用了一个树状的条件随机场,目的是使用隐变量识别物体的特征。该研究是最较早在条件随机场中使用隐变量的例子。Felzenszwalb 等[36]等的研究是一个相当成功的包含了物体不同部分对应的变量的判别模型。
另一个计算机视觉问题是识别在不同图片中出现的相似物体。例如,Deselaers等[33]给出了一个条件随机场模型来解决该问题。
计算机视觉方面的综述文献参见Nowozin和Lampert[101]。
任意结构条件随机场在自然语中的应用参见文献[16,37,133]。
在一些条件随机场应用中,尽管图模型难以确定,但依旧存在有效的动态规划算法。例如,McCallum等[84]研究了字符串匹配问题。使用CRF来研究语法派生问题(derivations of a grammar)的文献参见[23,38,114,148]。
2.8 关于术语
图模型不同方面的理论是在不同的领域被独立地提出的,因此许多概念在不同领域有不同的称呼。例如,无向模型一般被称为马尔可夫随机场、马尔可夫网络或Gibbs分布。如前所述,我们使用“图模型”表示一族由图结构定义的分布;“随机场”或“分布”表示单独的概率分布;“网络”表示图结构自身。这种称呼与某些文献并不完全一致,部分原因是一般情况下也不需要对这些概念进行精确地区分。
同样,有向网络模型一般称为贝叶斯网络,但是我们避免使用该术语,因为容易与贝叶斯统计中的概念相混淆。“生成模型”是在文献中常常使用的一个重要术语,但是没有精确的定义。(我们在2.2节给出了自己的定义)。
以上是关于条件随机场介绍—— An Introduction to Conditional Random Fields的主要内容,如果未能解决你的问题,请参考以下文章