NLP-BERT 璋锋瓕鑷劧璇█澶勭悊妯″瀷锛欱ERT-鍩轰簬pytorch
Posted 鏈哄櫒瀛︿範AI绠楁硶宸ョ▼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP-BERT 璋锋瓕鑷劧璇█澶勭悊妯″瀷锛欱ERT-鍩轰簬pytorch相关的知识,希望对你有一定的参考价值。
鍚慉I杞瀷鐨勭▼搴忓憳閮藉叧娉ㄤ簡杩欎釜鍙?/span>馃憞馃憞馃憞
涓€銆佸墠瑷€
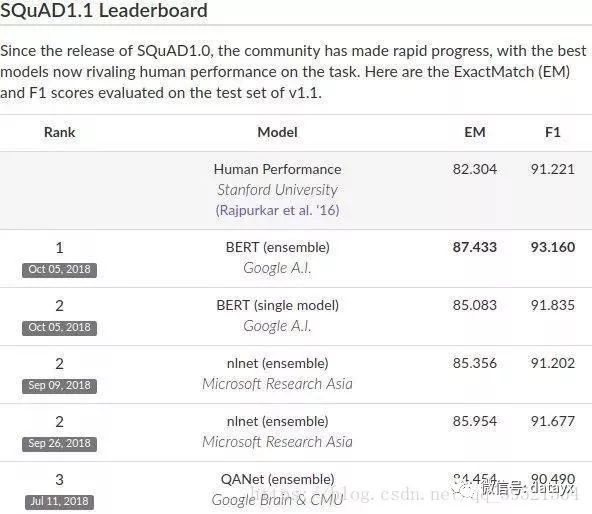
鏈€杩戣胺姝屾悶浜嗕釜澶ф柊闂伙紝鍏徃AI鍥㈤槦鏂板彂甯冪殑BERT妯″瀷锛屽湪鏈哄櫒闃呰鐞嗚В椤剁骇姘村钩娴嬭瘯SQuAD1.1涓〃鐜板嚭鎯婁汉鐨勬垚缁╋細鍏ㄩ儴涓や釜琛¢噺鎸囨爣涓婂叏闈㈣秴瓒婁汉绫伙紝骞朵笖杩樺湪11绉嶄笉鍚孨LP娴嬭瘯涓垱鍑烘渶浣虫垚缁╋紝鍖呮嫭灏咷LUE鍩哄噯鎺ㄨ嚦80.4锛咃紙缁濆鏀硅繘7.6锛咃級锛孧ultiNLI鍑嗙‘搴﹁揪鍒?6.7% 锛堢粷瀵规敼杩涚巼5.6锛咃級绛夈€傚彲浠ラ瑙佺殑鏄紝BERT灏嗕负NLP甯︽潵閲岀▼纰戝紡鐨勬敼鍙橈紝涔熸槸NLP棰嗗煙杩戞湡鏈€閲嶈鐨勮繘灞曘€?br>
璋锋瓕鍥㈤槦鐨凾hang Luong鐩存帴瀹氫箟锛欱ERT妯″瀷寮€鍚簡NLP鐨勬柊鏃朵唬锛?br>
浠庣幇鍦ㄧ殑澶ц秼鍔挎潵鐪嬶紝浣跨敤鏌愮妯″瀷棰勮缁冧竴涓瑷€妯″瀷鐪嬭捣鏉ユ槸涓€绉嶆瘮杈冮潬璋辩殑鏂规硶銆備粠涔嬪墠AI2鐨?ELMo锛屽埌 OpenAI鐨刦ine-tune transformer锛屽啀鍒癎oogle鐨勮繖涓狟ERT锛屽叏閮芥槸瀵归璁粌鐨勮瑷€妯″瀷鐨勫簲鐢ㄣ€?br>
BERT杩欎釜妯″瀷涓庡叾瀹冧袱涓笉鍚岀殑鏄?br>
瀹冨湪璁粌鍙屽悜璇█妯″瀷鏃朵互鍑忓皬鐨勬鐜囨妸灏戦噺鐨勮瘝鏇挎垚浜哅ask鎴栬€呭彟涓€涓殢鏈虹殑璇嶃€傛垜涓汉鎰熻杩欎釜鐩殑鍦ㄤ簬浣挎ā鍨嬭杩鍔犲涓婁笅鏂囩殑璁板繂銆傝嚦浜庤繖涓鐜囷紝鎴戠寽鏄疛acob鎷嶈剳琚嬮殢渚胯鐨勩€?br> 澧炲姞浜嗕竴涓娴嬩笅涓€鍙ョ殑loss銆傝繖涓湅璧锋潵灏辨瘮杈冩柊濂囦簡銆?br>
BERT妯″瀷鍏锋湁浠ヤ笅涓や釜鐗圭偣锛?br>
绗竴锛屾槸杩欎釜妯″瀷闈炲父鐨勬繁锛?2灞傦紝骞朵笉瀹?wide锛夛紝涓棿灞傚彧鏈?024锛岃€屼箣鍓嶇殑Transformer妯″瀷涓棿灞傛湁2048銆傝繖浼间箮鍙堝嵃璇佷簡璁$畻鏈哄浘鍍忓鐞嗙殑涓€涓鐐光€斺€旀繁鑰岀獎 姣?娴呰€屽 鐨勬ā鍨嬫洿濂姐€?br>
绗簩锛孧LM锛圡asked Language Model锛夛紝鍚屾椂鍒╃敤宸︿晶鍜屽彸渚х殑璇嶈锛岃繖涓湪ELMo涓婂凡缁忓嚭鐜颁簡锛岀粷瀵逛笉鏄師鍒涖€傚叾娆★紝瀵逛簬Mask锛堥伄鎸★級鍦ㄨ瑷€妯″瀷涓婄殑搴旂敤锛屽凡缁忚Ziang Xie鎻愬嚭浜嗭紙鎴戝緢鏈夊垢鐨勪篃鍙備笌鍒颁簡杩欑瘒璁烘枃涓級锛歔1703.02573] Data Noising as Smoothing in Neural Network Language Models銆?/p>
https://arxiv.org/abs/1703.02573
杩欎篃鏄瘒宸ㄦ槦浜戦泦鐨勮鏂囷細Sida Wang锛孞iwei Li锛堥渚鎶€鐨勫垱濮嬩汉鍏糃EO鍏煎彶涓婂彂鏂囨渶澶氱殑NLP瀛﹁€咃級锛孉ndrew Ng锛孌an Jurafsky閮芥槸Coauthor銆備絾寰堝彲鎯滅殑鏄粬浠病鏈夊叧娉ㄥ埌杩欑瘒璁烘枃銆傜敤杩欑瘒璁烘枃鐨勬柟娉曞幓鍋歁asking锛岀浉淇RET鐨勮兘鍔涜涓嶅畾杩樹細鏈夋彁鍗囥€?br>
BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Paper URL : https://arxiv.org/abs/1810.04805
浜屻€佸浣曠悊瑙ERT妯″瀷
[1] BERT 瑕佽В鍐充粈涔堥棶棰橈紵
閫氬父鎯呭喌 transformer 妯″瀷鏈夊緢澶氬弬鏁伴渶瑕佽缁冦€傝濡?BERT BASE 妯″瀷: L=12, H=768, A=12, 闇€瑕佽缁冪殑妯″瀷鍙傛暟鎬绘暟鏄?12 * 768 * 12 = 110M銆傝繖涔堝鍙傛暟闇€瑕佽缁冿紝鑷劧闇€瑕佹捣閲忕殑璁粌璇枡銆傚鏋滃叏閮ㄧ敤浜哄姏鏍囨敞鐨勫姙娉曪紝鏉ュ埗浣滆缁冩暟鎹紝浜哄姏鎴愭湰澶ぇ銆?br>
鍙椼€夾 Neural Probabilistic Language Model銆嬭鏂囩殑鍚彂锛孊ERT 涔熺敤 unsupervised 鐨勫姙娉曪紝鏉ヨ缁?transformer 妯″瀷銆傜缁忔鐜囪瑷€妯″瀷杩欑瘒璁烘枃锛屼富瑕佽浜嗕袱浠朵簨鍎匡紝1. 鑳藉惁鐢ㄦ暟鍊煎悜閲忥紙word vector锛夋潵琛ㄨ揪鑷劧璇█璇嶆眹鐨勮涔夛紵2. 濡備綍缁欐瘡涓瘝姹囷紝鎵惧埌鎭板綋鐨勬暟鍊煎悜閲忥紵
杩欑瘒璁烘枃鍐欏緱闈炲父绮惧僵锛屾繁鍏ユ祬鍑猴紝瑕佽█涓嶇儲锛岃€屼笖闈㈤潰淇卞埌銆傜粡鍏歌鏂囷紝鍊煎緱鍙嶅鍜€鍤笺€傚緢澶氬悓琛屾湅鍙嬮兘鐔熸倝杩欑瘒璁烘枃锛屽唴瀹逛笉閲嶅璇翠簡銆傚父鐢ㄧ殑涓枃姹夊瓧鏈?3500 涓紝杩欎簺瀛楃粍鍚堟垚璇嶆眹锛屼腑鏂囪瘝姹囨暟閲忛珮杈?50 涓囦釜銆傚亣濡傝瘝鍚戦噺鐨勭淮搴︽槸 512锛岄偅涔堣瑷€妯″瀷鐨勫弬鏁版暟閲忥紝鑷冲皯鏄?512 * 50涓?= 256M
妯″瀷鍙傛暟鏁伴噺杩欎箞澶э紝蹇呯劧闇€瑕佹捣閲忕殑璁粌璇枡銆備粠鍝噷鏀堕泦杩欎簺娴烽噺鐨勮缁冭鏂欙紵銆夾 Neural Probabilistic Language Model銆嬭繖绡囪鏂囪锛屾瘡涓€绡囨枃绔狅紝澶╃敓鏄缁冭鏂欍€傞毦閬撲笉闇€瑕佷汉宸ユ爣娉ㄥ悧锛熷洖绛旓紝涓嶉渶瑕併€?br>
鎴戜滑缁忓父璇达紝鈥滆璇濅笉瑕侀涓夊€掑洓锛岃閫氶『锛岃杩炶疮鈥濓紝鎰忔€濇槸涓婁笅鏂囩殑璇嶆眹锛屽簲璇ュ叿鏈夎涔夌殑杩炶疮鎬с€傚熀浜庤嚜鐒惰瑷€鐨勮繛璐€э紝璇█妯″瀷鏍规嵁鍓嶆枃鐨勮瘝锛岄娴嬩笅涓€涓皢鍑虹幇鐨勮瘝銆傚鏋滆瑷€妯″瀷鐨勫弬鏁版纭紝濡傛灉姣忎釜璇嶇殑璇嶅悜閲忚缃纭紝閭d箞璇█妯″瀷鐨勯娴嬶紝灏卞簲璇ユ瘮杈冨噯纭€傚ぉ涓嬫枃绔狅紝鏁颁笉鑳滄暟锛屾墍浠ヨ缁冩暟鎹紝鍙栦箣涓嶅敖鐢ㄤ箣涓嶇銆?br>
娣卞害瀛︿範鍥涘ぇ瑕佺礌锛?. 璁粌鏁版嵁銆?. 妯″瀷銆?. 绠楀姏銆?. 搴旂敤銆傝缁冩暟鎹湁浜嗭紝鎺ヤ笅鍘荤殑闂鏄ā鍨嬨€?br>
[2] BERT 鐨勪簲涓叧閿瘝 Pre-training銆丏eep銆丅idirectional銆乀ransformer銆丩anguage Understanding 鍒嗗埆鏄粈涔堟剰鎬濓紵
銆夾 Neural Probabilistic Language Model銆嬭繖绡囪鏂囪鐨?Language Model锛屼弗鏍艰鏄瑷€鐢熸垚妯″瀷锛圠anguage Generative Model锛夛紝棰勬祴璇彞涓笅涓€涓皢浼氬嚭鐜扮殑璇嶆眹銆傝瑷€鐢熸垚妯″瀷鑳戒笉鑳界洿鎺ョЩ鐢ㄥ埌鍏跺畠 NLP 闂涓婂幓锛?br>
璀锛屾窐瀹濅笂鏈夊緢澶氱敤鎴疯瘎璁猴紝鑳藉惁鎶婃瘡涓€鏉$敤鎴疯浆鎹㈡垚璇勫垎锛?2銆?1銆?銆?銆?锛屽叾涓?-2 鏄瀬宸紝+2 鏄瀬濂姐€傚亣濡傛湁杩欐牱涓€鏉$敤鎴疯瘎璇紝鈥滀拱浜嗕竴浠堕箍鏅楀悓娆捐‖琛紝娌℃兂鍒帮紝绌垮湪鑷繁韬笂锛屼笉鍍忓皬椴滆倝锛屽€掑儚鏄帹甯堚€濓紝璇烽棶杩欐潯璇勮锛岀瓑鍚屼簬 -2锛岃繕鏄叾瀹冿紵
璇█鐢熸垚妯″瀷锛岃兘涓嶈兘寰堝ソ鍦拌В鍐充笂杩伴棶棰橈紵杩涗竴姝ラ棶锛屾湁娌℃湁 鈥滈€氱敤鐨勨€?璇█妯″瀷锛岃兘澶熺悊瑙h瑷€鐨勮涔夛紝閫傜敤浜庡悇绉?NLP 闂锛烞ERT 杩欑瘒璁烘枃鐨勯鐩緢鐩寸櫧锛屻€夿ERT: Pre-training of Deep Bidirectional Transformers for Language Understanding銆嬶紝涓€鐪肩湅鍘伙紝灏辫兘鐚滃緱鍒拌繖绡囨枃绔犱細璁插摢浜涘唴瀹广€?br>
杩欎釜棰樼洰鏈変簲涓叧閿瘝锛屽垎鍒槸 Pre-training銆丏eep銆丅idirectional銆乀ransformers銆佸拰 Language Understanding銆傚叾涓?pre-training 鐨勬剰鎬濇槸锛屼綔鑰呰涓猴紝纭疄瀛樺湪閫氱敤鐨勮瑷€妯″瀷锛屽厛鐢ㄦ枃绔犻璁粌閫氱敤妯″瀷锛岀劧鍚庡啀鏍规嵁鍏蜂綋搴旂敤锛岀敤 supervised 璁粌鏁版嵁锛岀簿鍔犲伐锛坒ine tuning锛夋ā鍨嬶紝浣夸箣閫傜敤浜庡叿浣撳簲鐢ㄣ€備负浜嗗尯鍒簬閽堝璇█鐢熸垚鐨?Language Model锛屼綔鑰呯粰閫氱敤鐨勮瑷€妯″瀷锛屽彇浜嗕竴涓悕瀛楋紝鍙瑷€琛ㄥ緛妯″瀷 Language Representation Model銆?br>
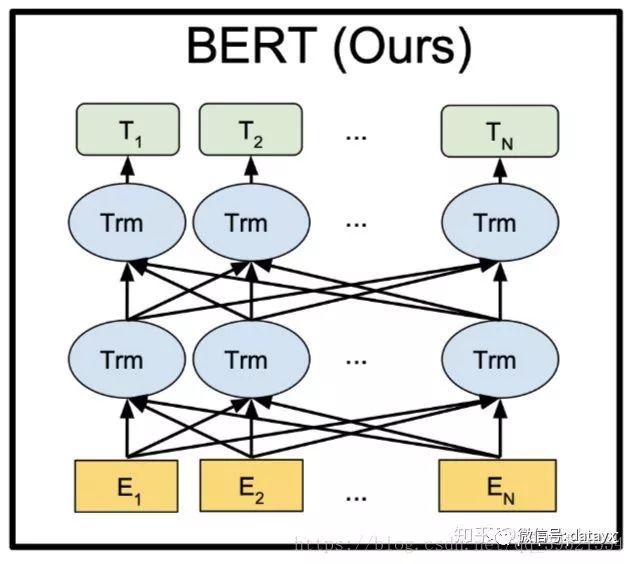
鑳藉疄鐜拌瑷€琛ㄥ緛鐩爣鐨勬ā鍨嬶紝鍙兘浼氭湁寰堝绉嶏紝鍏蜂綋鐢ㄥ摢涓€绉嶅憿锛熶綔鑰呮彁璁紝鐢?Deep Bidirectional Transformers 妯″瀷銆傚亣濡傜粰涓€涓彞瀛?鈥滆兘瀹炵幇璇█琛ㄥ緛[mask]鐨勬ā鍨嬧€濓紝閬洊浣忓叾涓€滅洰鏍団€濅竴璇嶃€備粠鍓嶅線鍚庨娴媅mask]锛屼篃灏辨槸鐢ㄢ€滆兘/瀹炵幇/璇█/琛ㄥ緛鈥濓紝鏉ラ娴媅mask]锛涙垨鑰咃紝浠庡悗寰€鍓嶉娴媅mask]锛屼篃灏辨槸鐢ㄢ€滄ā鍨?鐨勨€濓紝鏉ラ娴媅mask]锛岀О涔嬩负鍗曞悜棰勬祴 unidirectional銆傚崟鍚戦娴嬶紝涓嶈兘瀹屾暣鍦扮悊瑙f暣涓鍙ョ殑璇箟銆備簬鏄爺绌惰€呬滑灏濊瘯鍙屽悜棰勬祴銆傛妸浠庡墠寰€鍚庯紝涓庝粠鍚庡線鍓嶇殑涓や釜棰勬祴锛屾嫾鎺ュ湪涓€璧?[mask1/mask2]锛岃繖灏辨槸鍙屽悜棰勬祴 bi-directional銆傜粏鑺傚弬闃呫€奛eural Machine Translation by Jointly Learning to Align and Translate銆嬨€?br>
BERT 鐨勪綔鑰呰涓猴紝bi-directional 浠嶇劧涓嶈兘瀹屾暣鍦扮悊瑙f暣涓鍙ョ殑璇箟锛屾洿濂界殑鍔炴硶鏄敤涓婁笅鏂囧叏鍚戞潵棰勬祴[mask]锛屼篃灏辨槸鐢?鈥滆兘/瀹炵幇/璇█/琛ㄥ緛/../鐨?妯″瀷鈥濓紝鏉ラ娴媅mask]銆侭ERT 浣滆€呮妸涓婁笅鏂囧叏鍚戠殑棰勬祴鏂规硶锛岀О涔嬩负 deep bi-directional銆傚浣曟潵瀹炵幇涓婁笅鏂囧叏鍚戦娴嬪憿锛烞ERT 鐨勪綔鑰呭缓璁娇鐢?Transformer 妯″瀷銆傝繖涓ā鍨嬬敱銆夾ttention Is All You Need銆嬩竴鏂囧彂鏄庛€?br>
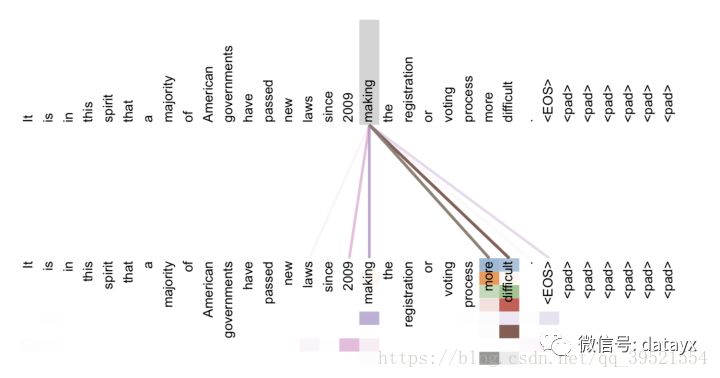
杩欎釜妯″瀷鐨勬牳蹇冩槸鑱氱劍鏈哄埗锛屽浜庝竴涓鍙ワ紝鍙互鍚屾椂鍚敤澶氫釜鑱氱劍鐐癸紝鑰屼笉蹇呭眬闄愪簬浠庡墠寰€鍚庣殑锛屾垨鑰呬粠鍚庡線鍓嶇殑锛屽簭鍒椾覆琛屽鐞嗐€備笉浠呰姝g‘鍦伴€夋嫨妯″瀷鐨勭粨鏋勶紝鑰屼笖杩樿姝g‘鍦拌缁冩ā鍨嬬殑鍙傛暟锛岃繖鏍锋墠鑳戒繚闅滄ā鍨嬭兘澶熷噯纭湴鐞嗚В璇彞鐨勮涔夈€侭ERT 鐢ㄤ簡涓や釜姝ラ锛岃瘯鍥惧幓姝g‘鍦拌缁冩ā鍨嬬殑鍙傛暟銆傜涓€涓楠ゆ槸鎶婁竴绡囨枃绔犱腑锛?5% 鐨勮瘝姹囬伄鐩栵紝璁╂ā鍨嬫牴鎹笂涓嬫枃鍏ㄥ悜鍦伴娴嬭閬洊鐨勮瘝銆傚亣濡傛湁 1 涓囩瘒鏂囩珷锛屾瘡绡囨枃绔犲钩鍧囨湁 100 涓瘝姹囷紝闅忔満閬洊 15% 鐨勮瘝姹囷紝妯″瀷鐨勪换鍔℃槸姝g‘鍦伴娴嬭繖 15 涓囦釜琚伄鐩栫殑璇嶆眹銆傞€氳繃鍏ㄥ悜棰勬祴琚伄鐩栦綇鐨勮瘝姹囷紝鏉ュ垵姝ヨ缁?Transformer 妯″瀷鐨勫弬鏁般€傜劧鍚庯紝鐢ㄧ浜屼釜姝ラ缁х画璁粌妯″瀷鐨勫弬鏁般€傝濡備粠涓婅堪 1 涓囩瘒鏂囩珷涓紝鎸戦€?20 涓囧璇彞锛屾€诲叡 40 涓囨潯璇彞銆傛寫閫夎鍙ュ鐨勬椂鍊欙紝鍏朵腑 2*10 涓囧璇彞锛屾槸杩炵画鐨勪袱鏉′笂涓嬫枃璇彞锛屽彟澶?2*10 涓囧璇彞锛屼笉鏄繛缁殑璇彞銆傜劧鍚庤 Transformer 妯″瀷鏉ヨ瘑鍒繖 20 涓囧璇彞锛屽摢浜涙槸杩炵画鐨勶紝鍝簺涓嶈繛缁€?br>
杩欎袱姝ヨ缁冨悎鍦ㄤ竴璧凤紝绉颁负棰勮缁?pre-training銆傝缁冪粨鏉熷悗鐨?Transformer 妯″瀷锛屽寘鎷畠鐨勫弬鏁帮紝鏄綔鑰呮湡寰呯殑閫氱敤鐨勮瑷€琛ㄥ緛妯″瀷銆?br>
涓夈€丅ERT妯″瀷瑙f瀽
棣栧厛鏉ョ湅涓嬭胺姝孉I鍥㈤槦鍋氱殑杩欑瘒璁烘枃銆?br>

BERT鐨勬柊璇█琛ㄧず妯″瀷锛屽畠浠h〃Transformer鐨勫弻鍚戠紪鐮佸櫒琛ㄧず銆備笌鏈€杩戠殑鍏朵粬璇█琛ㄧず妯″瀷涓嶅悓锛孊ERT鏃ㄥ湪閫氳繃鑱斿悎璋冭妭鎵€鏈夊眰涓殑涓婁笅鏂囨潵棰勫厛璁粌娣卞害鍙屽悜琛ㄧず銆傚洜姝わ紝棰勮缁冪殑BERT琛ㄧず鍙互閫氳繃涓€涓澶栫殑杈撳嚭灞傝繘琛屽井璋冿紝閫傜敤浜庡箍娉涗换鍔$殑鏈€鍏堣繘妯″瀷鐨勬瀯寤猴紝姣斿闂瓟浠诲姟鍜岃瑷€鎺ㄧ悊锛屾棤闇€閽堝鍏蜂綋浠诲姟鍋氬ぇ骞呮灦鏋勪慨鏀广€?br>
璁烘枃浣滆€呰涓虹幇鏈夌殑鎶€鏈弗閲嶅埗绾︿簡棰勮缁冭〃绀虹殑鑳藉姏銆傚叾涓昏灞€闄愬湪浜庢爣鍑嗚瑷€妯″瀷鏄崟鍚戠殑锛岃繖浣垮緱鍦ㄦā鍨嬬殑棰勮缁冧腑鍙互浣跨敤鐨勬灦鏋勭被鍨嬪緢鏈夐檺銆?br>
鍦ㄨ鏂囦腑锛屼綔鑰呴€氳繃鎻愬嚭BERT锛氬嵆Transformer鐨勫弻鍚戠紪鐮佽〃绀烘潵鏀硅繘鍩轰簬鏋舵瀯寰皟鐨勬柟娉曘€?br>
BERT 鎻愬嚭涓€绉嶆柊鐨勯璁粌鐩爣锛氶伄钄借瑷€妯″瀷锛坢asked language model锛孧LM锛夛紝鏉ュ厠鏈嶄笂鏂囨彁鍒扮殑鍗曞悜鎬у眬闄愩€侻LM 鐨勭伒鎰熸潵鑷?Cloze 浠诲姟锛圱aylor, 1953锛夈€侻LM 闅忔満閬斀妯″瀷杈撳叆涓殑涓€浜?token锛岀洰鏍囧湪浜庝粎鍩轰簬閬斀璇嶇殑璇鏉ラ娴嬪叾鍘熷璇嶆眹 id銆?br>
涓庝粠宸﹀埌鍙崇殑璇█妯″瀷棰勮缁冧笉鍚岋紝MLM 鐩爣鍏佽琛ㄥ緛铻嶅悎宸﹀彸涓や晶鐨勮澧冿紝浠庤€岄璁粌涓€涓繁搴﹀弻鍚?Transformer銆傞櫎浜嗛伄钄借瑷€妯″瀷涔嬪锛屾湰鏂囦綔鑰呰繕寮曞叆浜嗕竴涓€滀笅涓€鍙ラ娴嬧€濓紙next sentence prediction锛変换鍔★紝鍙互鍜孧LM鍏卞悓棰勮缁冩枃鏈鐨勮〃绀恒€?br>
璁烘枃鐨勪富瑕佽础鐚湪浜庯細
璇佹槑浜嗗弻鍚戦璁粌瀵硅瑷€琛ㄧず鐨勯噸瑕佹€с€備笌涔嬪墠浣跨敤鐨勫崟鍚戣瑷€妯″瀷杩涜棰勮缁冧笉鍚岋紝BERT浣跨敤閬斀璇█妯″瀷鏉ュ疄鐜伴璁粌鐨勬繁搴﹀弻鍚戣〃绀恒€?br> 璁烘枃琛ㄦ槑锛岄鍏堣缁冪殑琛ㄧず鍏嶅幓浜嗚澶氬伐绋嬩换鍔¢渶瑕侀拡瀵圭壒瀹氫换鍔′慨鏀逛綋绯绘灦鏋勭殑闇€姹傘€?BERT鏄涓€涓熀浜庡井璋冪殑琛ㄧず妯″瀷锛屽畠鍦ㄥぇ閲忕殑鍙ュ瓙绾у拰token绾т换鍔′笂瀹炵幇浜嗘渶鍏堣繘鐨勬€ц兘锛屽己浜庤澶氶潰鍚戠壒瀹氫换鍔′綋绯绘灦鏋勭殑绯荤粺銆?br> BERT鍒锋柊浜?1椤筃LP浠诲姟鐨勬€ц兘璁板綍銆傛湰鏂囪繕鎶ュ憡浜?BERT 鐨勬ā鍨嬬畝鍖栫爺绌讹紙ablation study锛夛紝琛ㄦ槑妯″瀷鐨勫弻鍚戞€ф槸涓€椤归噸瑕佺殑鏂版垚鏋溿€傜浉鍏充唬鐮佸拰棰勫厛璁粌鐨勬ā鍨嬪皢浼氬叕甯冨湪goo.gl/language/bert涓娿€?br>
BERT鐩墠宸茬粡鍒锋柊鐨?1椤硅嚜鐒惰瑷€澶勭悊浠诲姟鐨勬渶鏂拌褰曞寘鎷細灏咷LUE鍩哄噯鎺ㄨ嚦80.4锛咃紙缁濆鏀硅繘7.6锛咃級锛孧ultiNLI鍑嗙‘搴﹁揪鍒?6.7% 锛堢粷瀵规敼杩涚巼5.6锛咃級锛屽皢SQuAD v1.1闂瓟娴嬭瘯F1寰楀垎绾綍鍒锋柊涓?3.2鍒嗭紙缁濆鎻愬崌1.5鍒嗭級锛岃秴杩囦汉绫昏〃鐜?.0鍒嗐€?br>璁烘枃鐨勬牳蹇冿細璇﹁ВBERT妯″瀷鏋舵瀯
鏈妭浠嬬粛BERT妯″瀷鏋舵瀯鍜屽叿浣撳疄鐜帮紝骞朵粙缁嶉璁粌浠诲姟锛岃繖鏄繖绡囪鏂囩殑鏍稿績鍒涙柊銆?br>
妯″瀷鏋舵瀯
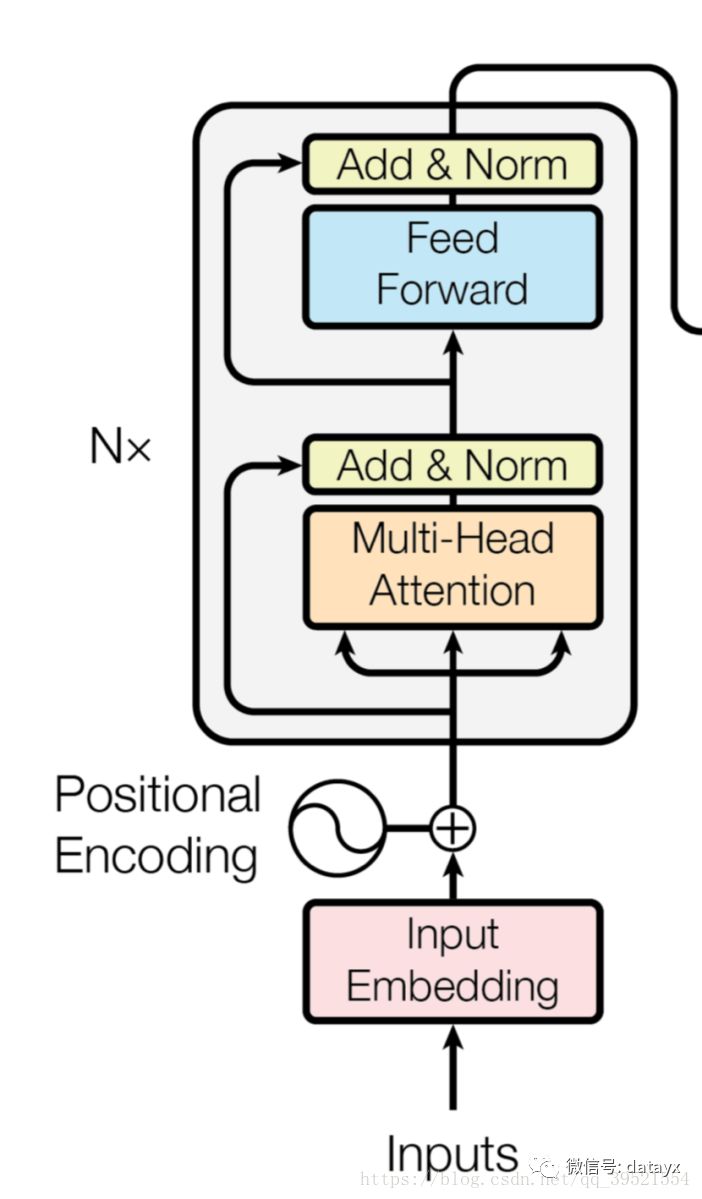
BERT鐨勬ā鍨嬫灦鏋勬槸鍩轰簬Vaswani et al. (2017) 涓弿杩扮殑鍘熷瀹炵幇multi-layer bidirectional Transformer缂栫爜鍣紝骞跺湪tensor2tensor搴撲腑鍙戝竷銆傜敱浜嶵ransformer鐨勪娇鐢ㄦ渶杩戝彉寰楁棤澶勪笉鍦紝璁烘枃涓殑瀹炵幇涓庡師濮嬪疄鐜板畬鍏ㄧ浉鍚岋紝鍥犳杩欓噷灏嗙渷鐣ュ妯″瀷缁撴瀯鐨勮缁嗘弿杩般€?br>
鍦ㄨ繖椤瑰伐浣滀腑锛岃鏂囧皢灞傛暟锛堝嵆Transformer blocks锛夎〃绀轰负L锛屽皢闅愯棌澶у皬琛ㄧず涓篐锛屽皢self-attention heads鐨勬暟閲忚〃绀轰负A銆傚湪鎵€鏈夋儏鍐典笅锛屽皢feed-forward/filter 鐨勫ぇ灏忚缃负 4H锛屽嵆H = 768鏃朵负3072锛孒 = 1024鏃朵负4096銆傝鏂囦富瑕佹姤鍛婁簡涓ょ妯″瀷澶у皬鐨勭粨鏋滐細
BERT_{BASE} : L=12, H=768, A=12, Total Parameters=110M
BERT_{LARGE} : L=24, H=1024, A=16, Total Parameters=340M
涓轰簡杩涜姣旇緝锛岃鏂囬€夋嫨浜?BERT_{LARGE} 锛屽畠涓嶰penAI GPT鍏锋湁鐩稿悓鐨勬ā鍨嬪ぇ灏忋€傜劧鑰岋紝閲嶈鐨勬槸锛孊ERT Transformer 浣跨敤鍙屽悜self-attention锛岃€孏PT Transformer 浣跨敤鍙楅檺鍒剁殑self-attention锛屽叾涓瘡涓猼oken鍙兘澶勭悊鍏跺乏渚х殑涓婁笅鏂囥€傜爺绌跺洟闃熸敞鎰忓埌锛屽湪鏂囩尞涓紝鍙屽悜 Transformer 閫氬父琚О涓衡€淭ransformer encoder鈥濓紝鑰屽乏渚т笂涓嬫枃琚О涓衡€淭ransformer decoder鈥濓紝鍥犱负瀹冨彲浠ョ敤浜庢枃鏈敓鎴愩€侭ERT锛孫penAI GPT鍜孍LMo涔嬮棿鐨勬瘮杈冨鍥?鎵€绀恒€?br>
鍥?锛氶璁粌妯″瀷鏋舵瀯鐨勫樊寮傘€侭ERT浣跨敤鍙屽悜Transformer銆侽penAI GPT浣跨敤浠庡乏鍒板彸鐨凾ransformer銆侲LMo浣跨敤缁忚繃鐙珛璁粌鐨勪粠宸﹀埌鍙冲拰浠庡彸鍒板乏LSTM鐨勪覆鑱旀潵鐢熸垚涓嬫父浠诲姟鐨勭壒寰併€備笁涓ā鍨嬩腑锛屽彧鏈塀ERT琛ㄧず鍦ㄦ墍鏈夊眰涓叡鍚屼緷璧栦簬宸﹀彸涓婁笅鏂囥€?br>
杈撳叆琛ㄧず锛坕nput representation锛?br>
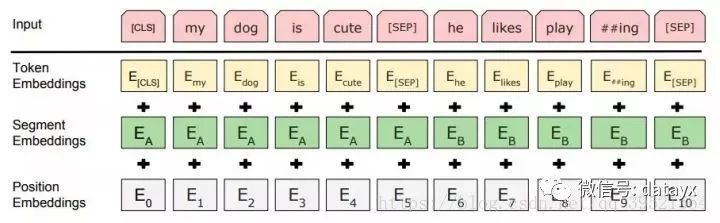
璁烘枃鐨勮緭鍏ヨ〃绀猴紙input representation锛夎兘澶熷湪涓€涓猼oken搴忓垪涓槑纭湴琛ㄧず鍗曚釜鏂囨湰鍙ュ瓙鎴栦竴瀵规枃鏈彞瀛愶紙渚嬪锛?[Question, Answer]锛夈€傚浜庣粰瀹歵oken锛屽叾杈撳叆琛ㄧず閫氳繃瀵圭浉搴旂殑token銆乻egment鍜宲osition embeddings杩涜姹傚拰鏉ユ瀯閫犮€傚浘2鏄緭鍏ヨ〃绀虹殑鐩磋琛ㄧず锛?br>
鍥?锛欱ERT杈撳叆琛ㄧず銆傝緭鍏ュ祵鍏ユ槸token embeddings, segmentation embeddings 鍜宲osition embeddings 鐨勬€诲拰銆?/p>
鍏蜂綋濡備笅锛?br>
浣跨敤WordPiece宓屽叆锛圵u et al., 2016锛夊拰30,000涓猼oken鐨勮瘝姹囪〃銆傜敤##琛ㄧず鍒嗚瘝銆?br> 浣跨敤瀛︿範鐨刾ositional embeddings锛屾敮鎸佺殑搴忓垪闀垮害鏈€澶氫负512涓猼oken銆?br> 姣忎釜搴忓垪鐨勭涓€涓猼oken濮嬬粓鏄壒娈婂垎绫诲祵鍏ワ紙[CLS]锛夈€傚搴斾簬璇oken鐨勬渶缁堥殣钘忕姸鎬侊紙鍗筹紝Transformer鐨勮緭鍑猴級琚敤浣滃垎绫讳换鍔$殑鑱氬悎搴忓垪琛ㄧず銆傚浜庨潪鍒嗙被浠诲姟锛屽皢蹇界暐姝ゅ悜閲忋€?br> 鍙ュ瓙瀵硅鎵撳寘鎴愪竴涓簭鍒椼€備互涓ょ鏂瑰紡鍖哄垎鍙ュ瓙銆傞鍏堬紝鐢ㄧ壒娈婃爣璁帮紙[SEP]锛夊皢瀹冧滑鍒嗗紑銆傚叾娆★紝娣诲姞涓€涓猯earned sentence A宓屽叆鍒扮涓€涓彞瀛愮殑姣忎釜token涓紝涓€涓猻entence B宓屽叆鍒扮浜屼釜鍙ュ瓙鐨勬瘡涓猼oken涓€?br> 瀵逛簬鍗曚釜鍙ュ瓙杈撳叆锛屽彧浣跨敤 sentence A宓屽叆銆?br>
鍏抽敭鍒涙柊锛氶璁粌浠诲姟
涓嶱eters et al. (2018) 鍜?Radford et al. (2018)涓嶅悓锛岃鏂囦笉浣跨敤浼犵粺鐨勪粠宸﹀埌鍙虫垨浠庡彸鍒板乏鐨勮瑷€妯″瀷鏉ラ璁粌BERT銆傜浉鍙嶏紝浣跨敤涓や釜鏂扮殑鏃犵洃鐫i娴嬩换鍔″BERT杩涜棰勮缁冦€?br>
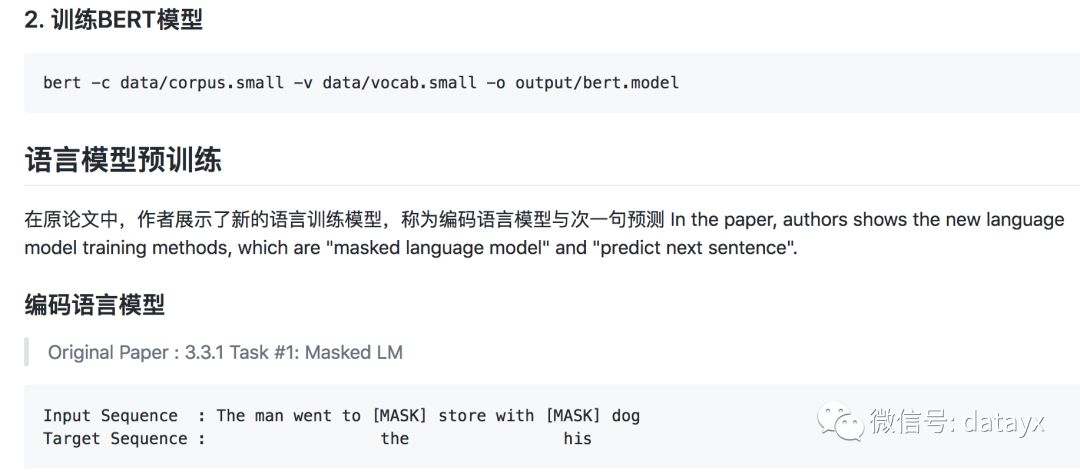
浠诲姟1: Masked LM
浠庣洿瑙変笂鐪嬶紝鐮旂┒鍥㈤槦鏈夌悊鐢辩浉淇★紝娣卞害鍙屽悜妯″瀷姣攍eft-to-right 妯″瀷鎴杔eft-to-right and right-to-left妯″瀷鐨勬祬灞傝繛鎺ユ洿寮哄ぇ銆傞仐鎲剧殑鏄紝鏍囧噯鏉′欢璇█妯″瀷鍙兘浠庡乏鍒板彸鎴栦粠鍙冲埌宸﹁繘琛岃缁冿紝鍥犱负鍙屽悜鏉′欢浣滅敤灏嗗厑璁告瘡涓崟璇嶅湪澶氬眰涓婁笅鏂囦腑闂存帴鍦扳€渟ee itself鈥濄€?br>
涓轰簡璁粌涓€涓繁搴﹀弻鍚戣〃绀猴紙deep bidirectional representation锛夛紝鐮旂┒鍥㈤槦閲囩敤浜嗕竴绉嶇畝鍗曠殑鏂规硶锛屽嵆闅忔満灞忚斀锛坢asking锛夐儴鍒嗚緭鍏oken锛岀劧鍚庡彧棰勬祴閭d簺琚睆钄界殑token銆傝鏂囧皢杩欎釜杩囩▼绉颁负鈥渕asked LM鈥?MLM)锛屽敖绠″湪鏂囩尞涓畠缁忓父琚О涓篊loze浠诲姟(Taylor, 1953)銆?br>
鍦ㄨ繖涓緥瀛愪腑锛屼笌masked token瀵瑰簲鐨勬渶缁堥殣钘忓悜閲忚杈撳叆鍒拌瘝姹囪〃涓婄殑杈撳嚭softmax涓紝灏卞儚鍦ㄦ爣鍑哃M涓竴鏍枫€傚湪鍥㈤槦鎵€鏈夊疄楠屼腑锛岄殢鏈哄湴灞忚斀浜嗘瘡涓簭鍒椾腑15%鐨刉ordPiece token銆備笌鍘诲櫔鐨勮嚜鍔ㄧ紪鐮佸櫒锛圴incent et al.锛?2008锛夌浉鍙嶏紝鍙娴媘asked words鑰屼笉鏄噸寤烘暣涓緭鍏ャ€?br>
铏界劧杩欑‘瀹炶兘璁╁洟闃熻幏寰楀弻鍚戦璁粌妯″瀷锛屼絾杩欑鏂规硶鏈変袱涓己鐐广€傞鍏堬紝棰勮缁冨拰finetuning涔嬮棿涓嶅尮閰嶏紝鍥犱负鍦╢inetuning鏈熼棿浠庢湭鐪嬪埌[MASK]token銆備负浜嗚В鍐宠繖涓棶棰橈紝鍥㈤槦骞朵笉鎬绘槸鐢ㄥ疄闄呯殑[MASK]token鏇挎崲琚€渕asked鈥濈殑璇嶆眹銆傜浉鍙嶏紝璁粌鏁版嵁鐢熸垚鍣ㄩ殢鏈洪€夋嫨15锛呯殑token銆備緥濡傚湪杩欎釜鍙ュ瓙鈥渕y dog is hairy鈥濅腑锛屽畠閫夋嫨鐨則oken鏄€渉airy鈥濄€傜劧鍚庯紝鎵ц浠ヤ笅杩囩▼锛?br>
鏁版嵁鐢熸垚鍣ㄥ皢鎵ц浠ヤ笅鎿嶄綔锛岃€屼笉鏄缁堢敤[MASK]鏇挎崲鎵€閫夊崟璇嶏細
80锛呯殑鏃堕棿锛氱敤[MASK]鏍囪鏇挎崲鍗曡瘝锛屼緥濡傦紝my dog is hairy 鈫?my dog is [MASK]
10锛呯殑鏃堕棿锛氱敤涓€涓殢鏈虹殑鍗曡瘝鏇挎崲璇ュ崟璇嶏紝渚嬪锛宮y dog is hairy 鈫?my dog is apple
10锛呯殑鏃堕棿锛氫繚鎸佸崟璇嶄笉鍙橈紝渚嬪锛宮y dog is hairy 鈫?my dog is hairy. 杩欐牱鍋氱殑鐩殑鏄皢琛ㄧず鍋忓悜浜庡疄闄呰瀵熷埌鐨勫崟璇嶃€?br>
Transformer encoder涓嶇煡閬撳畠灏嗚瑕佹眰棰勬祴鍝簺鍗曡瘝鎴栧摢浜涘崟璇嶅凡琚殢鏈哄崟璇嶆浛鎹紝鍥犳瀹冭杩繚鎸佹瘡涓緭鍏oken鐨勫垎甯冨紡涓婁笅鏂囪〃绀恒€傛澶栵紝鍥犱负闅忔満鏇挎崲鍙彂鐢熷湪鎵€鏈塼oken鐨?.5锛咃紙鍗?5锛呯殑10锛咃級锛岃繖浼间箮涓嶄細鎹熷妯″瀷鐨勮瑷€鐞嗚В鑳藉姏銆?br>
浣跨敤MLM鐨勭浜屼釜缂虹偣鏄瘡涓猙atch鍙娴嬩簡15锛呯殑token锛岃繖琛ㄦ槑妯″瀷鍙兘闇€瑕佹洿澶氱殑棰勮缁冩楠ゆ墠鑳芥敹鏁涖€傚洟闃熻瘉鏄嶮LM鐨勬敹鏁涢€熷害鐣ユ參浜?left-to-right鐨勬ā鍨嬶紙棰勬祴姣忎釜token锛夛紝浣哅LM妯″瀷鍦ㄥ疄楠屼笂鑾峰緱鐨勬彁鍗囪繙杩滆秴杩囧鍔犵殑璁粌鎴愭湰銆?br>
浠诲姟2锛氫笅涓€鍙ラ娴?br>
璁稿閲嶈鐨勪笅娓镐换鍔★紝濡傞棶绛旓紙QA锛夊拰鑷劧璇█鎺ㄧ悊锛圢LI锛夐兘鏄熀浜庣悊瑙d袱涓彞瀛愪箣闂寸殑鍏崇郴锛岃繖骞舵病鏈夐€氳繃璇█寤烘ā鐩存帴鑾峰緱銆?br>
鍦ㄤ负浜嗚缁冧竴涓悊瑙e彞瀛愮殑妯″瀷鍏崇郴锛岄鍏堣缁冧竴涓簩杩涘埗鍖栫殑涓嬩竴鍙ユ祴浠诲姟锛岃繖涓€浠诲姟鍙互浠庝换浣曞崟璇鏂欏簱涓敓鎴愩€傚叿浣撳湴璇达紝褰撻€夋嫨鍙ュ瓙A鍜孊浣滀负棰勮缁冩牱鏈椂锛孊鏈?0锛呯殑鍙兘鏄疉鐨勪笅涓€涓彞瀛愶紝涔熸湁50锛呯殑鍙兘鏄潵鑷鏂欏簱鐨勯殢鏈哄彞瀛愩€備緥濡傦細
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
鍥㈤槦瀹屽叏闅忔満鍦伴€夋嫨浜哊otNext璇彞锛屾渶缁堢殑棰勮缁冩ā鍨嬪湪姝や换鍔′笂瀹炵幇浜?7锛?98锛呯殑鍑嗙‘鐜囥€?/p>
瀹為獙缁撴灉
濡傚墠鏂囨墍杩帮紝BERT鍦?1椤筃LP浠诲姟涓埛鏂颁簡鎬ц兘琛ㄧ幇璁板綍锛佸湪杩欎竴鑺備腑锛屽洟闃熺洿瑙傚憟鐜癇ERT鍦ㄨ繖浜涗换鍔$殑瀹為獙缁撴灉锛屽叿浣撶殑瀹為獙璁剧疆鍜屾瘮杈冭闃呰鍘熻鏂?
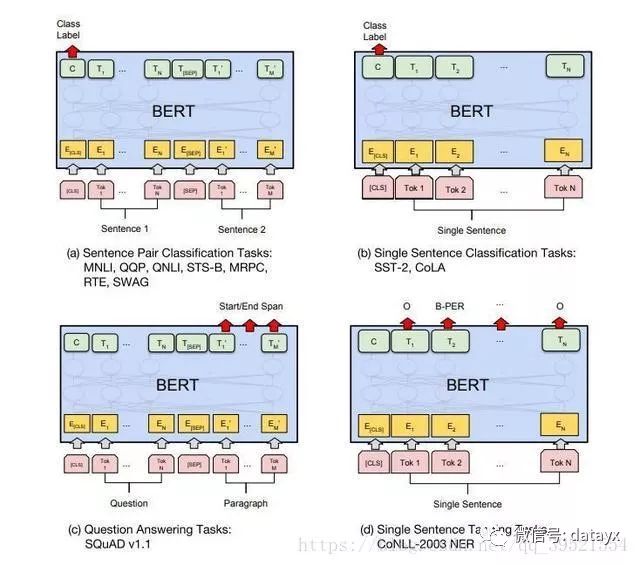
鍥?锛氭垜浠殑闈㈠悜鐗瑰畾浠诲姟鐨勬ā鍨嬫槸灏咮ERT涓庝竴涓澶栫殑杈撳嚭灞傜粨鍚堣€屽舰鎴愮殑锛屽洜姝ら渶瑕佷粠澶村紑濮嬪涔犳渶灏忔暟閲忕殑鍙傛暟銆傚湪杩欎簺浠诲姟涓紝锛坅锛夊拰锛坆锛夋槸搴忓垪绾т换鍔★紝鑰岋紙c锛夊拰锛坉锛夋槸token绾т换鍔°€傚湪鍥句腑锛孍琛ㄧず杈撳叆宓屽叆锛孴i琛ㄧずtokeni鐨勪笂涓嬫枃琛ㄧず锛孾CLS]鏄敤浜庡垎绫昏緭鍑虹殑鐗规畩绗﹀彿锛孾SEP]鏄敤浜庡垎闅旈潪杩炵画token搴忓垪鐨勭壒娈婄鍙枫€?br>
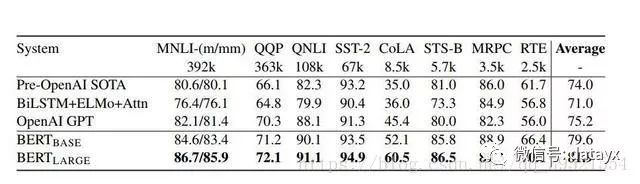
鍥?锛欸LUE娴嬭瘯缁撴灉锛岀敱GLUE璇勪及鏈嶅姟鍣ㄧ粰鍑恒€傛瘡涓换鍔′笅鏂圭殑鏁板瓧琛ㄧず璁粌鏍蜂緥鐨勬暟閲忋€傗€滃钩鍧団€濅竴鏍忎腑鐨勬暟鎹笌GLUE瀹樻柟璇勫垎绋嶆湁涓嶅悓锛屽洜涓烘垜浠帓闄や簡鏈夐棶棰樼殑WNLI闆嗐€侭ERT 鍜孫penAI GPT鐨勭粨鏋滄槸鍗曟ā鍨嬨€佸崟浠诲姟涓嬬殑鏁版嵁銆傛墍鏈夌粨鏋滄潵鑷猦ttps://gluebenchmark.com/leaderboard鍜宧ttps://blog.openai.com/language-unsupervised/
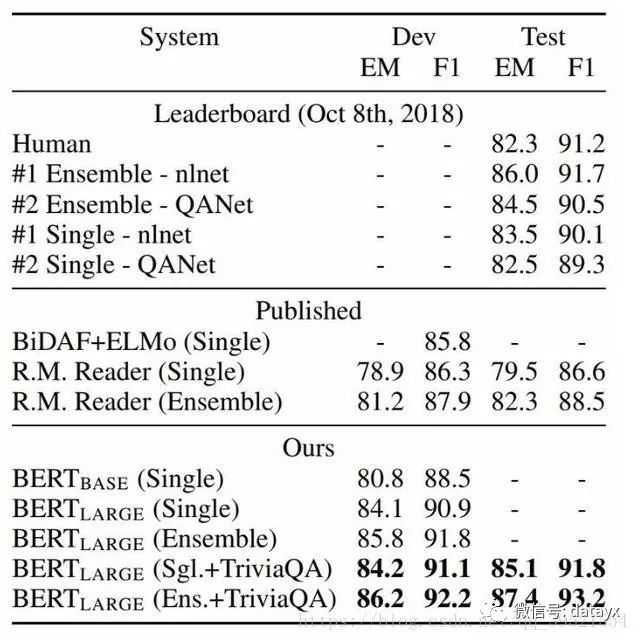
鍥?锛歋QuAD 缁撴灉銆侭ERT 闆嗘垚鏄娇鐢ㄤ笉鍚岄璁粌妫€鏌ョ偣鍜宖ine-tuning seed鐨?7x 绯荤粺銆?br>
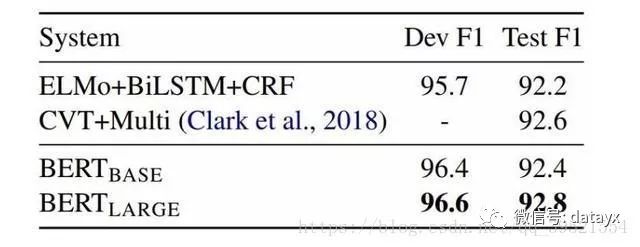
鍥?锛欳oNLL-2003 鍛藉悕瀹炰綋璇嗗埆缁撴灉銆傝秴鍙傛暟鐢卞紑鍙戦泦閫夋嫨锛屽緱鍑虹殑寮€鍙戝拰娴嬭瘯鍒嗘暟鏄娇鐢ㄨ繖浜涜秴鍙傛暟杩涜浜旀闅忔満閲嶅惎鐨勫钩鍧囧€笺€?br>
鍥涖€丅ERT妯″瀷鐨勫奖鍝?br>
BERT鏄竴涓瑷€琛ㄥ緛妯″瀷锛坙anguage representation model锛夛紝閫氳繃瓒呭ぇ鏁版嵁銆佸法澶фā鍨嬨€佸拰鏋佸ぇ鐨勮绠楀紑閿€璁粌鑰屾垚锛屽湪11涓嚜鐒惰瑷€澶勭悊鐨勪换鍔′腑鍙栧緱浜嗘渶浼橈紙state-of-the-art, SOTA锛夌粨鏋溿€傛垨璁镐綘宸茬粡鐚滃埌浜嗘妯″瀷鍑鸿嚜浣曟柟锛屾病閿欙紝瀹冧骇鑷胺姝屻€備及璁′笉灏戜汉浼氳皟渚冭繖绉嶈妯$殑瀹為獙宸茬粡鍩烘湰璁╀竴鑸殑瀹為獙瀹ゅ拰鐮旂┒鍛樻湜灏樿帿鍙婁簡锛屼絾瀹冪‘瀹炵粰鎴戜滑鎻愪緵浜嗗緢澶氬疂璐电殑缁忛獙锛?br>
娣卞害瀛︿範灏辨槸琛ㄥ緛瀛︿範 锛圖eep learning is representation learning锛夛細"We show that pre-trained representations eliminate the needs of many heavily engineered task-specific architectures". 鍦?1椤笲ERT鍒峰嚭鏂板鐣岀殑浠诲姟涓紝澶у鍙湪棰勮缁冭〃寰侊紙pre-trained representation锛夊井璋冿紙fine-tuning锛夌殑鍩虹涓婂姞涓€涓嚎鎬у眰浣滀负杈撳嚭锛坙inear output layer锛夈€傚湪搴忓垪鏍囨敞鐨勪换鍔¢噷锛坋.g. NER锛夛紝鐢氳嚦杩炲簭鍒楄緭鍑虹殑渚濊禆鍏崇郴閮藉厛涓嶇锛坕.e. non-autoregressive and no CRF锛夛紝鐓ф牱绉掓潃涔嬪墠鐨凷OTA锛屽彲瑙佸叾琛ㄥ緛瀛︿範鑳藉姏涔嬪己澶с€?br> 瑙勬ā寰堥噸瑕侊紙Scale matters锛夛細"One of our core claims is that the deep bidirectionality of BERT, which is enabled by masked LM pre-training, is the single most important improvement of BERT compared to previous work". 杩欑閬尅锛坢ask锛夊湪璇█妯″瀷涓婄殑搴旂敤瀵瑰緢澶氫汉鏉ヨ宸茬粡涓嶆柊椴滀簡锛屼絾纭槸BERT鐨勪綔鑰呭湪濡傛瓒呭ぇ瑙勬ā鐨勬暟鎹?妯″瀷+绠楀姏鐨勫熀纭€涓婇獙璇佷簡鍏跺己澶х殑琛ㄥ緛瀛︿範鑳藉姏銆傝繖鏍风殑妯″瀷锛岀敋鑷冲彲浠ュ欢浼稿埌寰堝鍏朵粬鐨勬ā鍨嬶紝鍙兘涔嬪墠閮借涓嶅悓鐨勫疄楠屽鎻愬嚭鍜岃瘯楠岃繃锛屽彧鏄敱浜庤妯$殑灞€闄愭病鑳藉厖鍒嗘寲鎺樿繖浜涙ā鍨嬬殑娼滃姏锛岃€岄仐鎲惧湴璁╁畠浠娣规病鍦ㄤ簡婊氭粴鐨刾aper娲祦涔嬩腑銆?br> 棰勮缁冧环鍊煎緢澶э紙Pre-training is important锛夛細"We believe that this is the first work to demonstrate that scaling to extreme model sizes also leads to large improvements on very small-scale tasks, provided that the model has been sufficiently pre-trained". 棰勮缁冨凡缁忚骞挎硾搴旂敤鍦ㄥ悇涓鍩熶簡锛坋.g. ImageNet for CV, Word2Vec in NLP锛夛紝澶氭槸閫氳繃澶фā鍨嬪ぇ鏁版嵁锛岃繖鏍风殑澶фā鍨嬬粰灏忚妯′换鍔¤兘甯︽潵鐨勬彁鍗囨湁鍑犱綍锛屼綔鑰呬篃缁欏嚭浜嗚嚜宸辩殑绛旀銆侭ERT妯″瀷鐨勯璁粌鏄敤Transformer鍋氱殑锛屼絾鎴戞兂鎹㈠仛LSTM鎴栬€匞RU鐨勮瘽搴旇涓嶄細鏈夊お澶ф€ц兘涓婄殑宸埆锛屽綋鐒惰缁冭绠楁椂鐨勫苟琛岃兘鍔涘氨鍙﹀綋鍒浜嗐€?br>
瀵笲ERT妯″瀷鐨勮鐐?br>
0. high-performance鐨勫師鍥犲叾瀹炶繕鏄綊缁撲簬涓ょ偣锛岄櫎浜嗘ā鍨嬬殑鏀硅繘锛屾洿閲嶈鐨勬槸鐢ㄤ簡瓒呭ぇ鐨勬暟鎹泦锛圔ooksCorpus 800M + English Wikipedia 2.5G鍗曡瘝锛夊拰瓒呭ぇ鐨勭畻鍔涳紙瀵瑰簲浜庤秴澶фā鍨嬶級鍦ㄧ浉鍏崇殑浠诲姟涓婂仛棰勮缁冿紝瀹炵幇浜嗗湪鐩爣浠诲姟涓婅〃鐜扮殑鍗曡皟澧為暱
1. 杩欎釜妯″瀷鐨勫弻鍚戝拰Elmo涓嶄竴鏍凤紝澶ч儴鍒嗕汉瀵逛粬杩欎釜鍙屽悜鍦╪ovelty涓婄殑contribution 鐨勫ぇ灏忔湁璇В锛屾垜瑙夊緱杩欎釜缁嗚妭鍙兘鏄粬姣擡lmo鏄捐憲鎻愬崌鐨勫師鍥犮€侲lmo鏄嫾涓€涓乏鍒板彸鍜屼竴涓彸鍒板乏锛屼粬杩欎釜鏄缁冧腑鐩存帴寮€涓€涓獥鍙o紝鐢ㄤ簡涓湁椤哄簭鐨刢bow銆?br>
2. 鍙鐜版€у樊锛氭湁閽辨墠鑳戒负鎵€娆蹭负锛圧eddit瀵硅窇涓€娆ERT鐨勪环鏍艰璁猴級
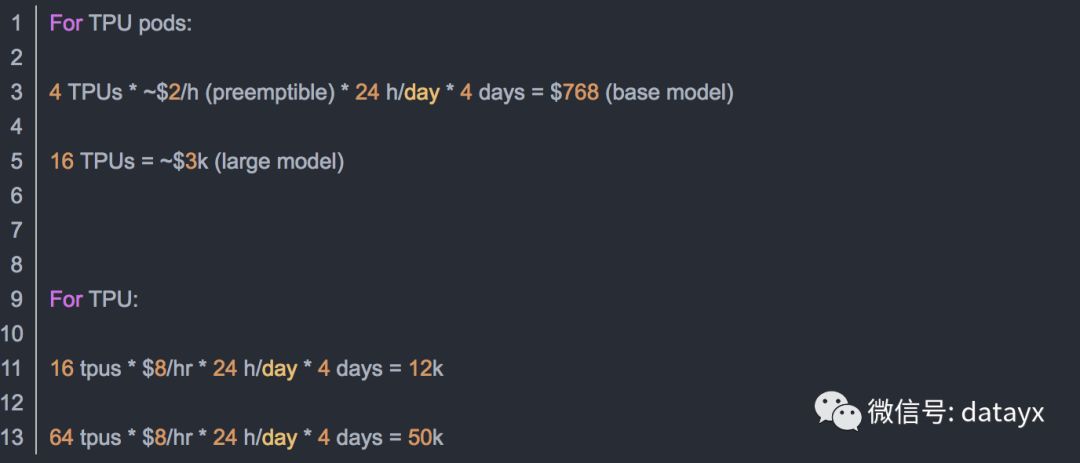 鏈€鍚庝粬闂埌锛欶or GPU:"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? " 锛岀劧鍚庤繖涓氨寰坕nteresting浜嗐€?
鏈€鍚庝粬闂埌锛欶or GPU:"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? " 锛岀劧鍚庤繖涓氨寰坕nteresting浜嗐€?
BERT-Pytorch浣跨敤

https://blog.csdn.net/qq_39521554/article/details/83062188
闃呰杩囨湰鏂囩殑浜鸿繕鐪嬩簡浠ヤ笅锛?/strong>
涓嶆柇鏇存柊璧勬簮
娣卞害瀛︿範銆佹満鍣ㄥ涔犮€佹暟鎹垎鏋愩€乸ython
以上是关于NLP-BERT 璋锋瓕鑷劧璇█澶勭悊妯″瀷锛欱ERT-鍩轰簬pytorch的主要内容,如果未能解决你的问题,请参考以下文章
鑷劧璇█澶勭悊锛氭枃鏈澶勭悊銆佽瑷€妯″瀷銆丷NN
銆愭潕椋為鏉庝匠鏂伴噷绋嬬銆慉utoML鑷劧璇█涓庣炕璇戝ぇ鍗囩骇锛孴PU 3.0杩涘叆璋锋瓕浜戯紒
鎵挎帴cardboard澶栧寘锛寀nity3d澶栧寘锛堝寳浜姩杞€?璋锋瓕CARDBOARD鐪熷己澶э級