项目应用自然语言处理-分词词频统计词性标注格式化输出
Posted 人工智能学术前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目应用自然语言处理-分词词频统计词性标注格式化输出相关的知识,希望对你有一定的参考价值。
分词后词频统计词性标注格式化输出


txt文档读取

首先我们获取一个txt文档,按行进行读入,以list列表形式存储,文本内容为教学用课本。
需要用到 os系统模块,来获取文件所在的路径。
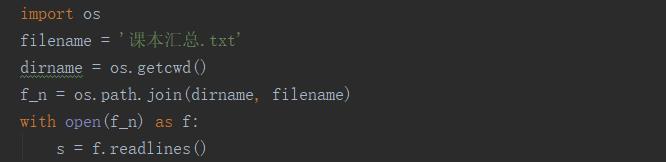
输入的txt文本样例如下图,注意不注明文件的详细的路径时,默认从项目的文件夹内找文件。

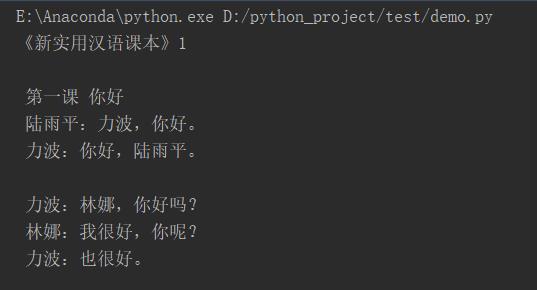
读取的文件存入到字符串s中。print输出读取到的文本内容,并通过使用type()函数,显示参数的数据类型。数据类型显示为<class 'str'>,字符串类型。

输出结果:

数据类型转换:列表类型转字符串
通过使用join()函数,进行组合,根据列表间的符号进行连接,构成字符串。

输出结果:

词性标注和分词
上一节中,我们使用了jieba.cut()直接分词功能,本例中我们使用jieba的pseg方法。pseg.cut(),在分词的同时,对词性进行标注。
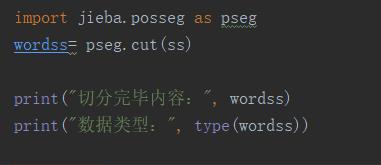
输出结果:
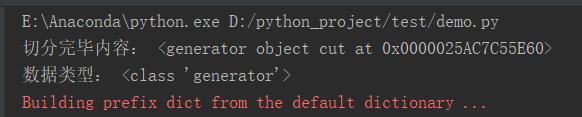
输出结果为,默认的数据类型字典,存一个词,然后再存一个对应词的词性。为了便于使用,我们将词典中内容提取出来,按字符串结构存储。
将字典结构中内容存储至字符串
首先,我们定义两个空的字符串,用于存储词,和词对应的词性标签。使用for循环并用正则表达式过滤拿出数据,使用append()函数,将拿出的数据存储到字符串中。
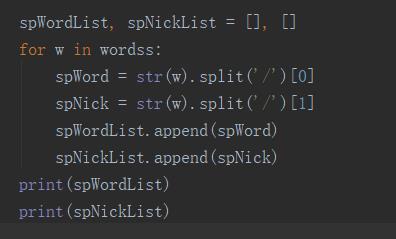
输出结果:

提取出的字符串,按照了文章的顺序,存储了下来,里面的分好的词,没有进行去重处理,这样我们可以进行下一步工作,统计每个词的出现次数。
计算词频
上一步工作中,我们将分好的词,按顺序存储到了字符串中,现在,我们想一边进行去重工作,一边进行词频统计工作。使用到了for循环和set数据结构。
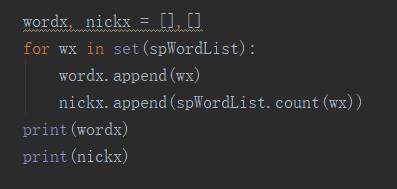
输出结果

同样的,我们使用了两个字符串来存储,一个存储去重后的词,一个存储应用词的词频。此时的词的顺序已经打乱,我们想通过表的索引来将数据映射起来。
构造DataFrame映射出结构化数据
本例中,我们需要调用pandas库,来简单的进行数据处理工作,我们要使用到,pandas的数据结构DataFrame,将两个DataFrame进行链接的merge()函数,以及pandas的csv文件生成结构化的表格。在链接过程中,会出现重复情况,我们由使用了drop_duplicates()函数进行去重。
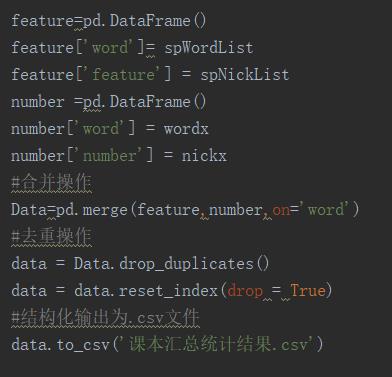
输出结果:
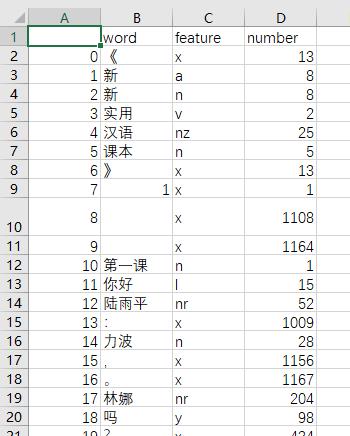
最终,我们生成了csv文件,里面包含了文档中分好的词,标注好的词性标签,以及词频。
更多精彩内容,尽在阅读原文
以上是关于项目应用自然语言处理-分词词频统计词性标注格式化输出的主要内容,如果未能解决你的问题,请参考以下文章